 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Back-Translation with Domain Text Generation for Sign Language Gloss Translation
Paper and Code
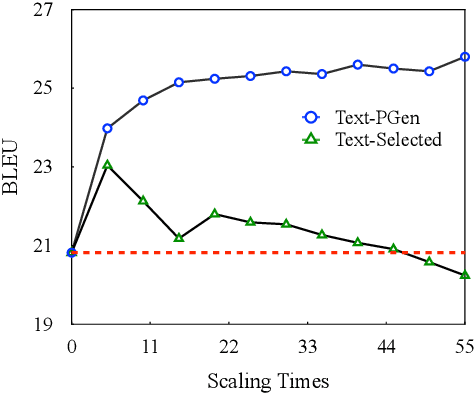

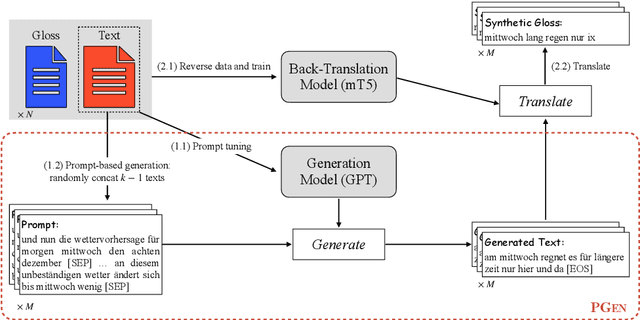

Sign language gloss translation aims to translate the sign glosses into spoken language texts, which is challenging due to the scarcity of labeled gloss-text parallel data. Back translation (BT), which generates pseudo-parallel data by translating in-domain spoken language texts into sign glosses, has been applied to alleviate the data scarcity problem. However, the lack of large-scale high-quality domain spoken language text data limits the effect of BT. In this paper, to overcome the limitation, we propose a Prompt based domain text Generation (PGEN) approach to produce the large-scale in-domain spoken language text data. Specifically, PGEN randomly concatenates sentences from the original in-domain spoken language text data as prompts to induce a pre-trained language model (i.e., GPT-2) to generate spoken language texts in a similar style. Experimental results on three benchmarks of sign language gloss translation in varied languages demonstrate that BT with spoken language texts generated by PGEN significantly outperforms the compared methods. In addition, as the scale of spoken language texts generated by PGEN increases, the BT technique can achieve further improvements, demonstrating the effectiveness of our approach. We release the code and data for facilitating future research in this field.