 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Generative Modeling with Limited Data, Few Shots, and Zero Shot
Jul 26, 2023
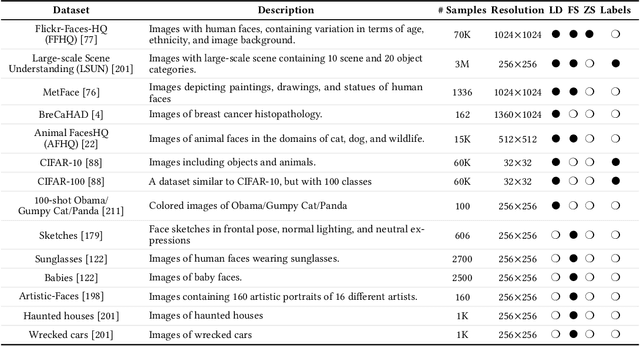

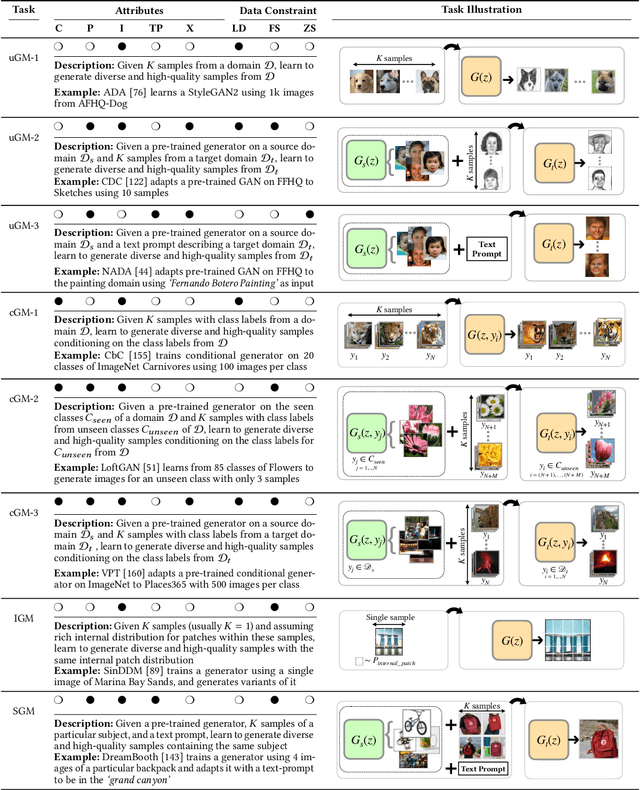
In machine learning, generative modeling aims to learn to generate new data statistically similar to the training data distribution. In this paper, we survey learning generative models under limited data, few shots and zero shot, referred to as Generative Modeling under Data Constraint (GM-DC). This is an important topic when data acquisition is challenging, e.g. healthcare applications. We discuss background, challenges, and propose two taxonomies: one on GM-DC tasks and another on GM-DC approaches. Importantly, we study interactions between different GM-DC tasks and approaches. Furthermore, we highlight research gaps, research trends, and potential avenues for future exploration. Project website: https://gmdc-survey.github.io.
Revisit Multimodal Meta-Learning through the Lens of Multi-Task Learning
Oct 27, 2021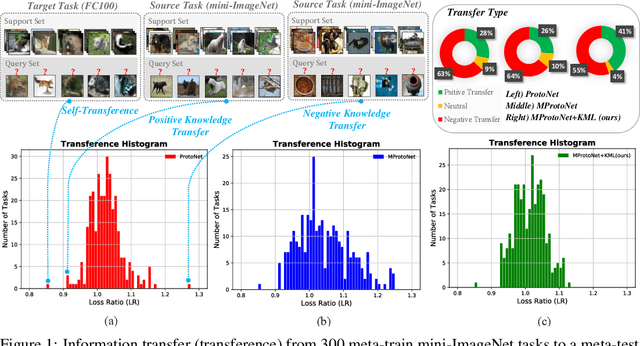
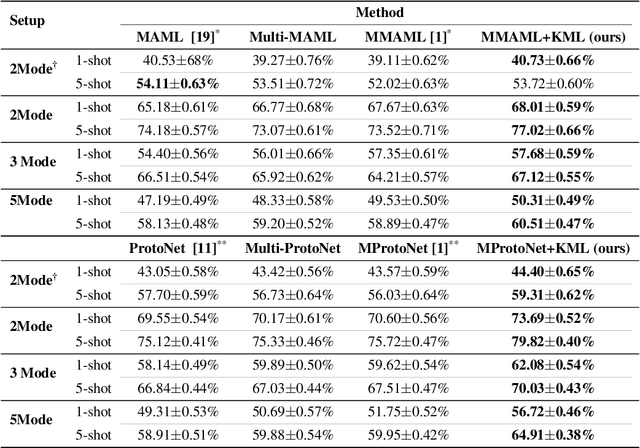
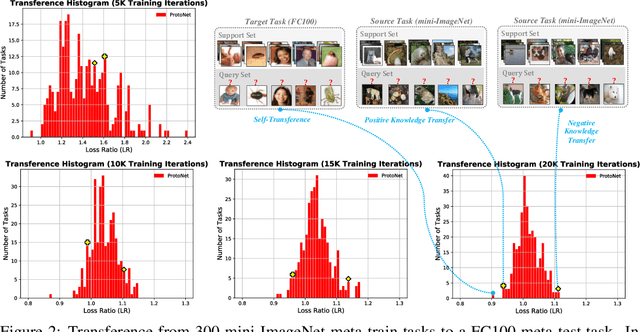
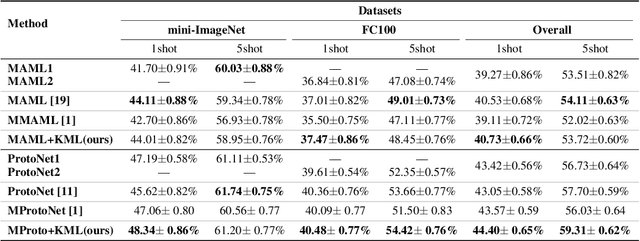
Multimodal meta-learning is a recent problem that extends conventional few-shot meta-learning by generalizing its setup to diverse multimodal task distributions. This setup makes a step towards mimicking how humans make use of a diverse set of prior skills to learn new skills. Previous work has achieved encouraging performance. In particular, in spite of the diversity of the multimodal tasks, previous work claims that a single meta-learner trained on a multimodal distribution can sometimes outperform multiple specialized meta-learners trained on individual unimodal distributions. The improvement is attributed to knowledge transfer between different modes of task distributions. However, there is no deep investigation to verify and understand the knowledge transfer between multimodal tasks. Our work makes two contributions to multimodal meta-learning. First, we propose a method to quantify knowledge transfer between tasks of different modes at a micro-level. Our quantitative, task-level analysis is inspired by the recent transference idea from multi-task learning. Second, inspired by hard parameter sharing in multi-task learning and a new interpretation of related work, we propose a new multimodal meta-learner that outperforms existing work by considerable margins. While the major focus is on multimodal meta-learning, our work also attempts to shed light on task interaction in conventional meta-learning. The code for this project is available at https://miladabd.github.io/KML.
Multi-focus Image Fusion for Visual Sensor Networks
Oct 02, 2020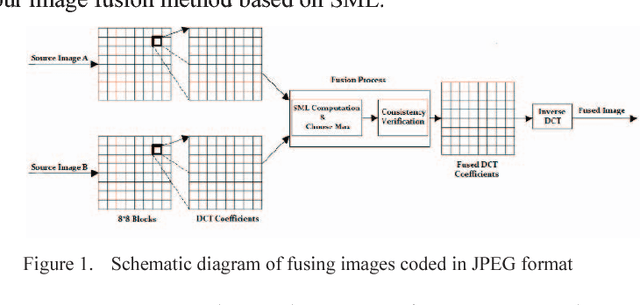



Image fusion in visual sensor networks (VSNs) aims to combine information from multiple images of the same scene in order to transform a single image with more information. Image fusion methods based on discrete cosine transform (DCT) are less complex and time-saving in DCT based standards of image and video which makes them more suitable for VSN applications. In this paper, an efficient algorithm for the fusion of multi-focus images in the DCT domain is proposed. The Sum of modified laplacian (SML) of corresponding blocks of source images is used as a contrast criterion and blocks with the larger value of SML are absorbed to output images. The experimental results on several images show the improvement of the proposed algorithm in terms of both subjective and objective quality of fused image relative to other DCT based techniques.
Aircraft Fuselage Defect Detection using Deep Neural Networks
Dec 26, 2017

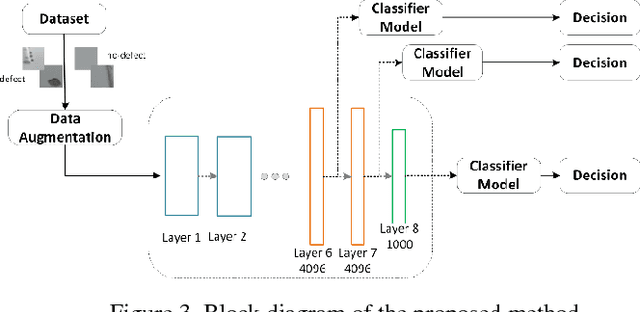
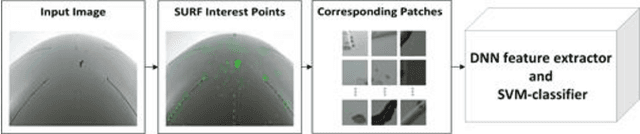
To ensure flight safety of aircraft structures, it is necessary to have regular maintenance using visual and nondestructive inspection (NDI) methods. In this paper, we propose an automatic image-based aircraft defect detection using Deep Neural Networks (DNNs). To the best of our knowledge, this is the first work for aircraft defect detection using DNNs. We perform a comprehensive evaluation of state-of-the-art feature descriptors and show that the best performance is achieved by vgg-f DNN as feature extractor with a linear SVM classifier. To reduce the processing time, we propose to apply SURF key point detector to identify defect patch candidates. Our experiment results suggest that we can achieve over 96% accuracy at around 15s processing time for a high-resolution (20-megapixel) image on a laptop.