 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Transferable Forensic Features for CNN-generated Images Detection
Aug 24, 2022



Visual counterfeits are increasingly causing an existential conundrum in mainstream media with rapid evolution in neural image synthesis methods. Though detection of such counterfeits has been a taxing problem in the image forensics community, a recent class of forensic detectors -- universal detectors -- are able to surprisingly spot counterfeit images regardless of generator architectures, loss functions, training datasets, and resolutions. This intriguing property suggests the possible existence of transferable forensic features (T-FF) in universal detectors. In this work, we conduct the first analytical study to discover and understand T-FF in universal detectors. Our contributions are 2-fold: 1) We propose a novel forensic feature relevance statistic (FF-RS) to quantify and discover T-FF in universal detectors and, 2) Our qualitative and quantitative investigations uncover an unexpected finding: color is a critical T-FF in universal detectors. Code and models are available at https://keshik6.github.io/transferable-forensic-features/
Revisiting Label Smoothing and Knowledge Distillation Compatibility: What was Missing?
Jun 29, 2022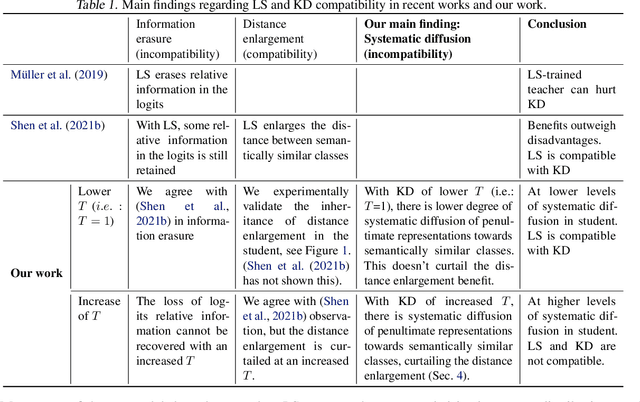
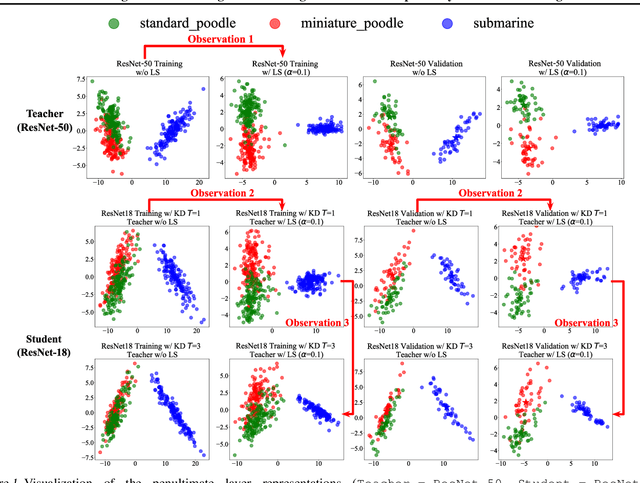

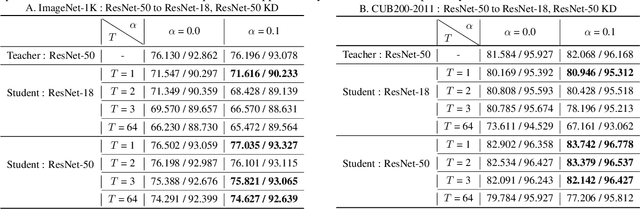
This work investigates the compatibility between label smoothing (LS) and knowledge distillation (KD). Contemporary findings addressing this thesis statement take dichotomous standpoints: Muller et al. (2019) and Shen et al. (2021b). Critically, there is no effort to understand and resolve these contradictory findings, leaving the primal question -- to smooth or not to smooth a teacher network? -- unanswered. The main contributions of our work are the discovery, analysis and validation of systematic diffusion as the missing concept which is instrumental in understanding and resolving these contradictory findings. This systematic diffusion essentially curtails the benefits of distilling from an LS-trained teacher, thereby rendering KD at increased temperatures ineffective. Our discovery is comprehensively supported by large-scale experiments, analyses and case studies including image classification, neural machine translation and compact student distillation tasks spanning across multiple datasets and teacher-student architectures. Based on our analysis, we suggest practitioners to use an LS-trained teacher with a low-temperature transfer to achieve high performance students. Code and models are available at https://keshik6.github.io/revisiting-ls-kd-compatibility/
A Closer Look at Fourier Spectrum Discrepancies for CNN-generated Images Detection
Mar 31, 2021

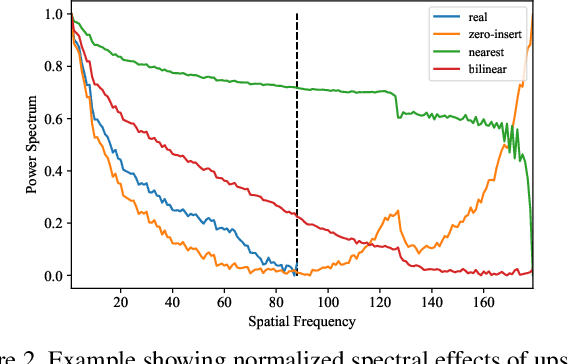
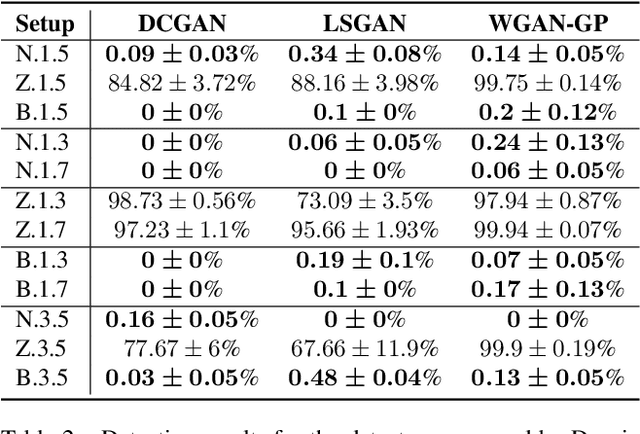
CNN-based generative modelling has evolved to produce synthetic images indistinguishable from real images in the RGB pixel space. Recent works have observed that CNN-generated images share a systematic shortcoming in replicating high frequency Fourier spectrum decay attributes. Furthermore, these works have successfully exploited this systematic shortcoming to detect CNN-generated images reporting up to 99% accuracy across multiple state-of-the-art GAN models. In this work, we investigate the validity of assertions claiming that CNN-generated images are unable to achieve high frequency spectral decay consistency. We meticulously construct a counterexample space of high frequency spectral decay consistent CNN-generated images emerging from our handcrafted experiments using DCGAN, LSGAN, WGAN-GP and StarGAN, where we empirically show that this frequency discrepancy can be avoided by a minor architecture change in the last upsampling operation. We subsequently use images from this counterexample space to successfully bypass the recently proposed forensics detector which leverages on high frequency Fourier spectrum decay attributes for CNN-generated image detection. Through this study, we show that high frequency Fourier spectrum decay discrepancies are not inherent characteristics for existing CNN-based generative models--contrary to the belief of some existing work--, and such features are not robust to perform synthetic image detection. Our results prompt re-thinking of using high frequency Fourier spectrum decay attributes for CNN-generated image detection. Code and models are available at https://keshik6.github.io/Fourier-Discrepancies-CNN-Detection/
InfoMax-GAN: Improved Adversarial Image Generation via Information Maximization and Contrastive Learning
Jul 09, 2020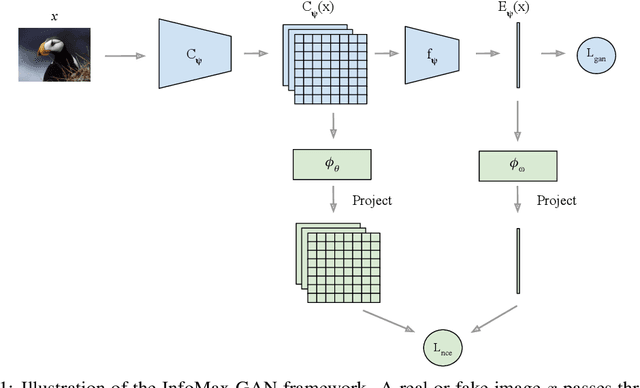

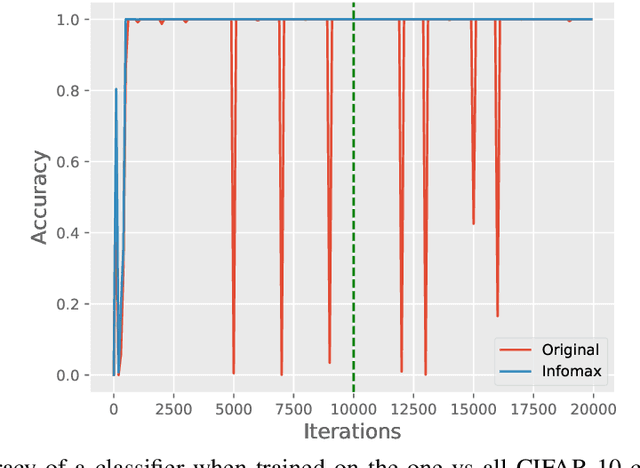
While Generative Adversarial Networks (GANs) are fundamental to many generative modelling applications, they suffer from numerous issues. In this work, we propose a principled framework to simultaneously address two fundamental issues in GANs: catastrophic forgetting of the discriminator and mode collapse of the generator. We achieve this by employing for GANs a contrastive learning and mutual information maximization approach, and perform extensive analyses to understand sources of improvements. Our approach significantly stabilises GAN training and improves GAN performance for image synthesis across five datasets under the same training and evaluation conditions against state-of-the-art works. Our approach is simple to implement and practical: it involves only one objective, is computationally inexpensive, and is robust across a wide range of hyperparameters without any tuning. For reproducibility, our code is available at https://github.com/kwotsin/mimicry.
Towards Good Practices for Data Augmentation in GAN Training
Jun 09, 2020


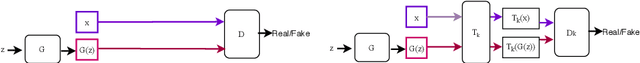
Recent successes in Generative Adversarial Networks (GAN) have affirmed the importance of using more data in GAN training. Yet it is expensive to collect data in many domains such as medical applications. Data Augmentation (DA) has been applied in these applications. In this work, we first argue that the classical DA approach could mislead the generator to learn the distribution of the augmented data, which could be different from that of the original data. We then propose a principled framework, termed Data Augmentation Optimized for GAN (DAG), to enable the use of augmented data in GAN training to improve the learning of the original distribution. We provide theoretical analysis to show that using our proposed DAG aligns with the original GAN in minimizing the JS divergence w.r.t. the original distribution and it leverages the augmented data to improve the learnings of discriminator and generator. The experiments show that DAG improves various GAN models. Furthermore, when DAG is used in some GAN models, the system establishes state-of-the-art Fr\'echet Inception Distance (FID) scores.
Self-supervised GAN: Analysis and Improvement with Multi-class Minimax Game
Nov 16, 2019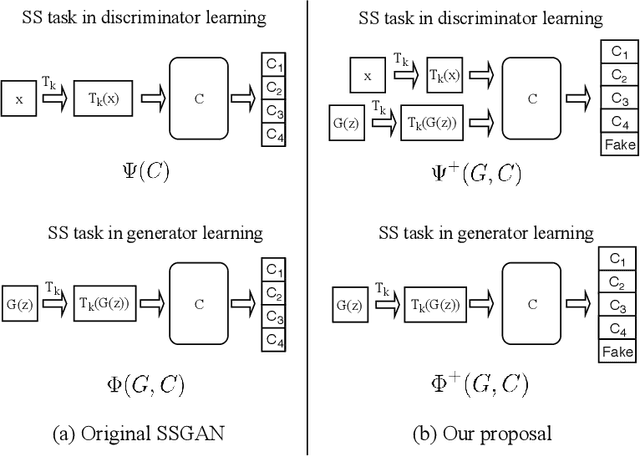
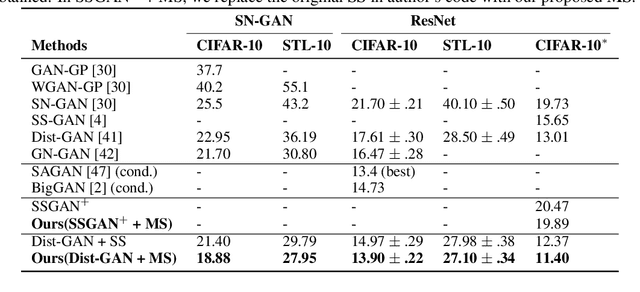


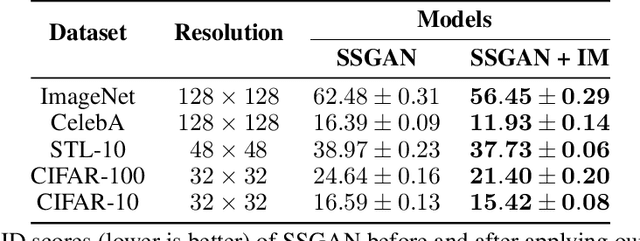
Self-supervised (SS) learning is a powerful approach for representation learning using unlabeled data. Recently, it has been applied to Generative Adversarial Networks (GAN) training. Specifically, SS tasks were proposed to address the catastrophic forgetting issue in the GAN discriminator. In this work, we perform an in-depth analysis to understand how SS tasks interact with learning of generator. From the analysis, we identify issues of SS tasks which allow a severely mode-collapsed generator to excel the SS tasks. To address the issues, we propose new SS tasks based on a multi-class minimax game. The competition between our proposed SS tasks in the game encourages the generator to learn the data distribution and generate diverse samples. We provide both theoretical and empirical analysis to support that our proposed SS tasks have better convergence property. We conduct experiments to incorporate our proposed SS tasks into two different GAN baseline models. Our approach establishes state-of-the-art FID scores on CIFAR-10, CIFAR-100, STL-10, CelebA, Imagenet $32\times32$ and Stacked-MNIST datasets, outperforming existing works by considerable margins in some cases. Our unconditional GAN model approaches performance of conditional GAN without using labeled data. Our code: \url{https://github.com/tntrung/msgan}
3D Face Pose and Animation Tracking via Eigen-Decomposition based Bayesian Approach
Aug 29, 2019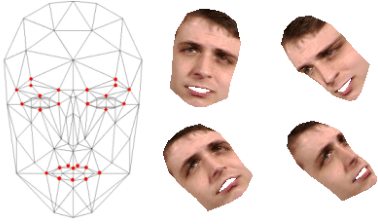
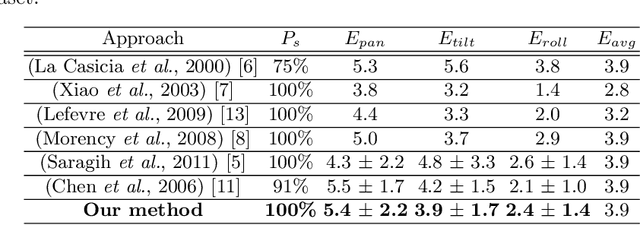


This paper presents a new method to track both the face pose and the face animation with a monocular camera. The approach is based on the 3D face model CANDIDE and on the SIFT (Scale Invariant Feature Transform) descriptors, extracted around a few given landmarks (26 selected vertices of CANDIDE model) with a Bayesian approach. The training phase is performed on a synthetic database generated from the first video frame. At each current frame, the face pose and animation parameters are estimated via a Bayesian approach, with a Gaussian prior and a Gaussian likelihood function whose the mean and the covariance matrix eigenvalues are updated from the previous frame using eigen decomposition. Numerical results on pose estimation and landmark locations are reported using the Boston University Face Tracking (BUFT) database and Talking Face video. They show that our approach, compared to six other published algorithms, provides a very good compromise and presents a promising perspective due to the good results in terms of landmark localization.
An Improved Self-supervised GAN via Adversarial Training
May 14, 2019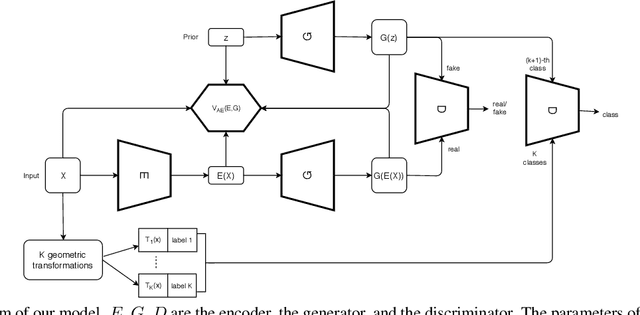

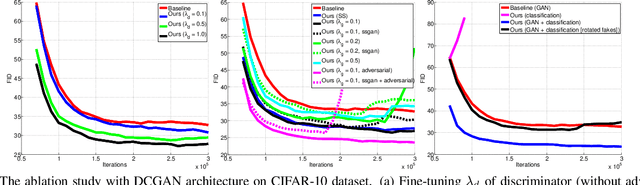
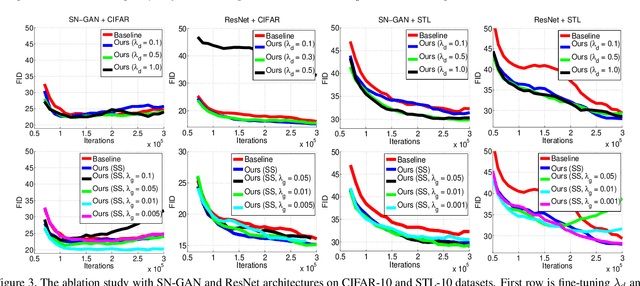
We propose to improve unconditional Generative Adversarial Networks (GAN) by training the self-supervised learning with the adversarial process. In particular, we apply self-supervised learning via the geometric transformation on input images and assign the pseudo-labels to these transformed images. (i) In addition to the GAN task, which distinguishes data (real) versus generated (fake) samples, we train the discriminator to predict the correct pseudo-labels of real transformed samples (classification task). Importantly, we find out that simultaneously training the discriminator to classify the fake class from the pseudo-classes of real samples for the classification task will improve the discriminator and subsequently lead better guides to train generator. (ii) The generator is trained by attempting to confuse the discriminator for not only the GAN task but also the classification task. For the classification task, the generator tries to confuse the discriminator recognizing the transformation of its output as one of the real transformed classes. Especially, we exploit that when the generator creates samples that result in a similar loss (via cross-entropy) as that of the real ones, the training is more stable and the generator distribution tends to match better the data distribution. When integrating our techniques into a state-of-the-art Auto-Encoder (AE) based-GAN model, they help to significantly boost the model's performance and also establish new state-of-the-art Fr\'echet Inception Distance (FID) scores in the literature of unconditional GAN for CIFAR-10 and STL-10 datasets.
Improving GAN with neighbors embedding and gradient matching
Nov 04, 2018

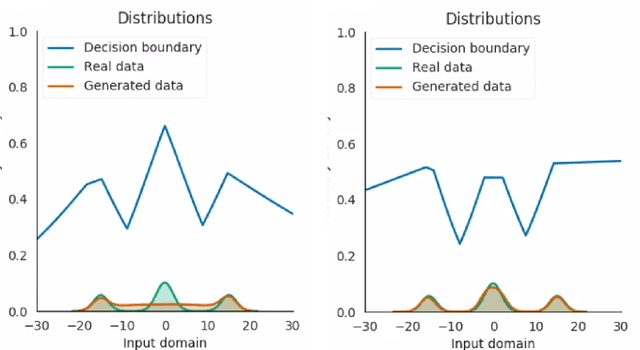
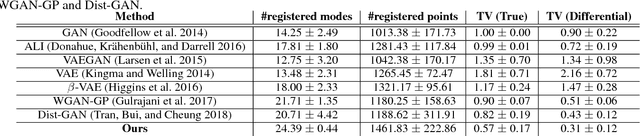
We propose two new techniques for training Generative Adversarial Networks (GANs). Our objectives are to alleviate mode collapse in GAN and improve the quality of the generated samples. First, we propose neighbor embedding, a manifold learning-based regularization to explicitly retain local structures of latent samples in the generated samples. This prevents generator from producing nearly identical data samples from different latent samples, and reduces mode collapse. We propose an inverse t-SNE regularizer to achieve this. Second, we propose a new technique, gradient matching, to align the distributions of the generated samples and the real samples. As it is challenging to work with high-dimensional sample distributions, we propose to align these distributions through the scalar discriminator scores. We constrain the difference between the discriminator scores of the real samples and generated ones. We further constrain the difference between the gradients of these discriminator scores. We derive these constraints from Taylor approximations of the discriminator function. We perform experiments to demonstrate that our proposed techniques are computationally simple and easy to be incorporated in existing systems. When Gradient matching and Neighbour embedding are applied together, our GN-GAN achieves outstanding results on 1D/2D synthetic, CIFAR-10 and STL-10 datasets, e.g. FID score of $30.80$ for the STL-10 dataset. Our code is available at: https://github.com/tntrung/gan
DOPING: Generative Data Augmentation for Unsupervised Anomaly Detection with GAN
Aug 24, 2018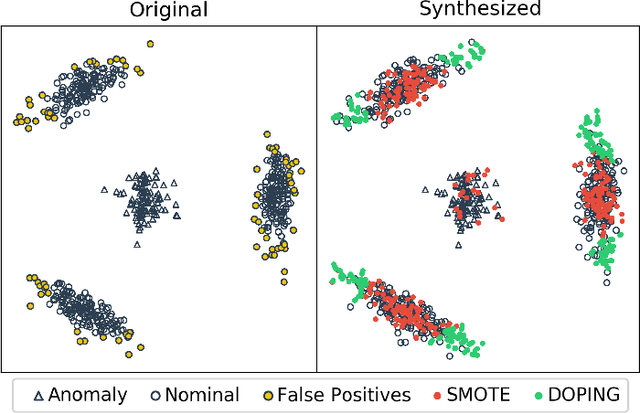


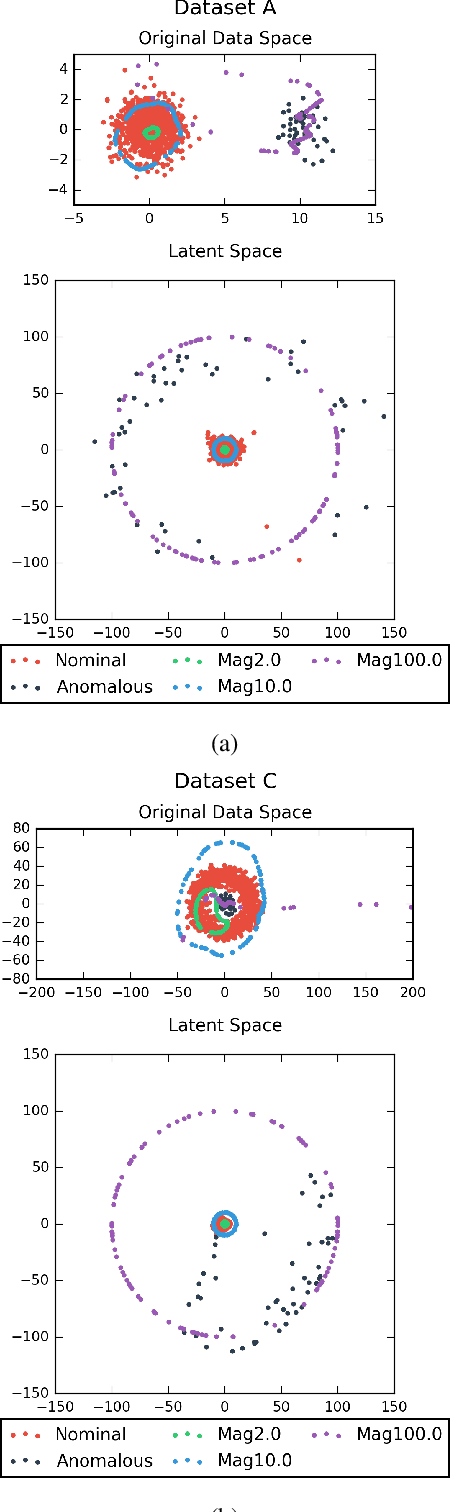
Recently, the introduction of the generative adversarial network (GAN) and its variants has enabled the generation of realistic synthetic samples, which has been used for enlarging training sets. Previous work primarily focused on data augmentation for semi-supervised and supervised tasks. In this paper, we instead focus on unsupervised anomaly detection and propose a novel generative data augmentation framework optimized for this task. In particular, we propose to oversample infrequent normal samples - normal samples that occur with small probability, e.g., rare normal events. We show that these samples are responsible for false positives in anomaly detection. However, oversampling of infrequent normal samples is challenging for real-world high-dimensional data with multimodal distributions. To address this challenge, we propose to use a GAN variant known as the adversarial autoencoder (AAE) to transform the high-dimensional multimodal data distributions into low-dimensional unimodal latent distributions with well-defined tail probability. Then, we systematically oversample at the `edge' of the latent distributions to increase the density of infrequent normal samples. We show that our oversampling pipeline is a unified one: it is generally applicable to datasets with different complex data distributions. To the best of our knowledge, our method is the first data augmentation technique focused on improving performance in unsupervised anomaly detection. We validate our method by demonstrating consistent improvements across several real-world datasets.