 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Face Pose and Animation Tracking via Eigen-Decomposition based Bayesian Approach
Paper and Code
Aug 29, 2019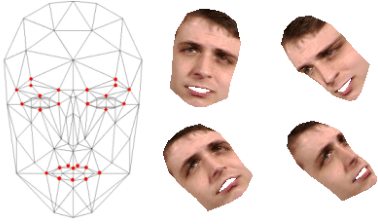
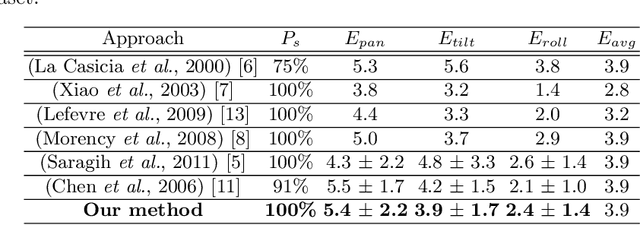


This paper presents a new method to track both the face pose and the face animation with a monocular camera. The approach is based on the 3D face model CANDIDE and on the SIFT (Scale Invariant Feature Transform) descriptors, extracted around a few given landmarks (26 selected vertices of CANDIDE model) with a Bayesian approach. The training phase is performed on a synthetic database generated from the first video frame. At each current frame, the face pose and animation parameters are estimated via a Bayesian approach, with a Gaussian prior and a Gaussian likelihood function whose the mean and the covariance matrix eigenvalues are updated from the previous frame using eigen decomposition. Numerical results on pose estimation and landmark locations are reported using the Boston University Face Tracking (BUFT) database and Talking Face video. They show that our approach, compared to six other published algorithms, provides a very good compromise and presents a promising perspective due to the good results in terms of landmark localization.