 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHome monitoring for frailty detection through sound and speaker diarization analysis
Aug 17, 2023



As the French, European and worldwide populations are aging, there is a strong interest for new systems that guarantee a reliable and privacy preserving home monitoring for frailty prevention. This work is a part of a global environmental audio analysis system which aims to help identification of Activities of Daily Life (ADL) through human and everyday life sounds recognition, speech presence and number of speakers detection. The focus is made on the number of speakers detection. In this article, we present how recent advances in sound processing and speaker diarization can improve the existing embedded systems. We study the performances of two new methods and discuss the benefits of DNN based approaches which improve performances by about 100%.
Towards Measuring and Scoring Speaker Diarization Fairness
Feb 20, 2023Speaker diarization, or the task of finding "who spoke and when", is now used in almost every speech processing application. Nevertheless, its fairness has not yet been evaluated because there was no protocol to study its biases one by one. In this paper we propose a protocol and a scoring method designed to evaluate speaker diarization fairness. This protocol is applied on a large dataset of spoken utterances and report the performances of speaker diarization depending on the gender, the age, the accent of the speaker and the length of the spoken sentence. Some biases induced by the gender, or the accent of the speaker were identified when we applied a state-of-the-art speaker diarization method.
3D Face Pose and Animation Tracking via Eigen-Decomposition based Bayesian Approach
Aug 29, 2019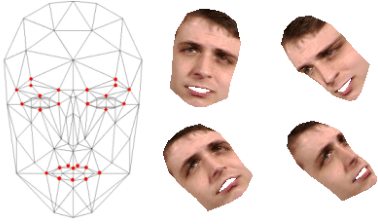
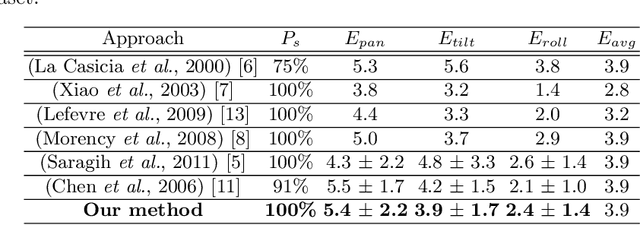


This paper presents a new method to track both the face pose and the face animation with a monocular camera. The approach is based on the 3D face model CANDIDE and on the SIFT (Scale Invariant Feature Transform) descriptors, extracted around a few given landmarks (26 selected vertices of CANDIDE model) with a Bayesian approach. The training phase is performed on a synthetic database generated from the first video frame. At each current frame, the face pose and animation parameters are estimated via a Bayesian approach, with a Gaussian prior and a Gaussian likelihood function whose the mean and the covariance matrix eigenvalues are updated from the previous frame using eigen decomposition. Numerical results on pose estimation and landmark locations are reported using the Boston University Face Tracking (BUFT) database and Talking Face video. They show that our approach, compared to six other published algorithms, provides a very good compromise and presents a promising perspective due to the good results in terms of landmark localization.
The Intelligent Voice 2016 Speaker Recognition System
Nov 02, 2016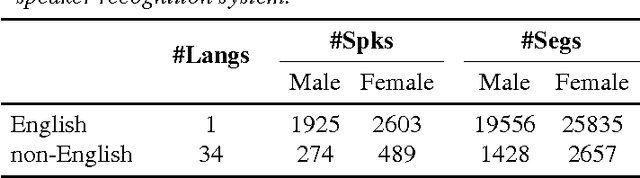

This paper presents the Intelligent Voice (IV) system submitted to the NIST 2016 Speaker Recognition Evaluation (SRE). The primary emphasis of SRE this year was on developing speaker recognition technology which is robust for novel languages that are much more heterogeneous than those used in the current state-of-the-art, using significantly less training data, that does not contain meta-data from those languages. The system is based on the state-of-the-art i-vector/PLDA which is developed on the fixed training condition, and the results are reported on the protocol defined on the development set of the challenge.