 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Emotion Expression Recognition in Older Adults Interacting with a Virtual Coach
Nov 09, 2023The EMPATHIC project aimed to design an emotionally expressive virtual coach capable of engaging healthy seniors to improve well-being and promote independent aging. One of the core aspects of the system is its human sensing capabilities, allowing for the perception of emotional states to provide a personalized experience. This paper outlines the development of the emotion expression recognition module of the virtual coach, encompassing data collection, annotation design, and a first methodological approach, all tailored to the project requirements. With the latter, we investigate the role of various modalities, individually and combined, for discrete emotion expression recognition in this context: speech from audio, and facial expressions, gaze, and head dynamics from video. The collected corpus includes users from Spain, France, and Norway, and was annotated separately for the audio and video channels with distinct emotional labels, allowing for a performance comparison across cultures and label types. Results confirm the informative power of the modalities studied for the emotional categories considered, with multimodal methods generally outperforming others (around 68% accuracy with audio labels and 72-74% with video labels). The findings are expected to contribute to the limited literature on emotion recognition applied to older adults in conversational human-machine interaction.
3D Face Pose and Animation Tracking via Eigen-Decomposition based Bayesian Approach
Aug 29, 2019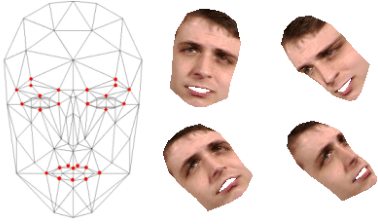
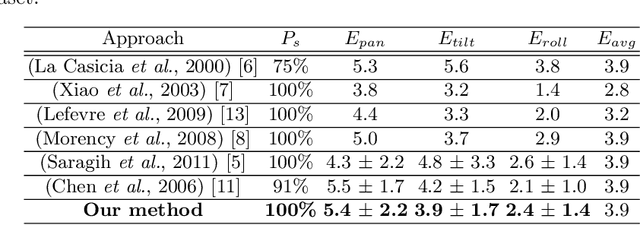


This paper presents a new method to track both the face pose and the face animation with a monocular camera. The approach is based on the 3D face model CANDIDE and on the SIFT (Scale Invariant Feature Transform) descriptors, extracted around a few given landmarks (26 selected vertices of CANDIDE model) with a Bayesian approach. The training phase is performed on a synthetic database generated from the first video frame. At each current frame, the face pose and animation parameters are estimated via a Bayesian approach, with a Gaussian prior and a Gaussian likelihood function whose the mean and the covariance matrix eigenvalues are updated from the previous frame using eigen decomposition. Numerical results on pose estimation and landmark locations are reported using the Boston University Face Tracking (BUFT) database and Talking Face video. They show that our approach, compared to six other published algorithms, provides a very good compromise and presents a promising perspective due to the good results in terms of landmark localization.