 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending against Model Inversion Attacks via Random Erasing
Sep 02, 2024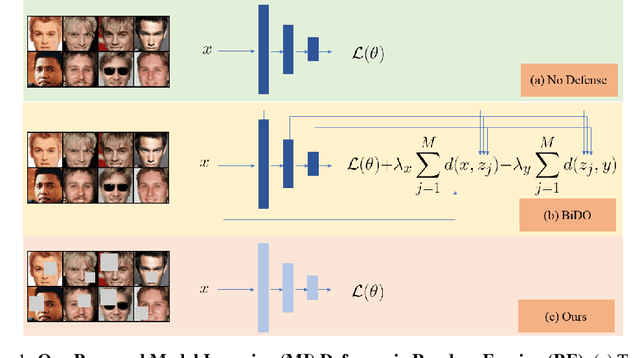

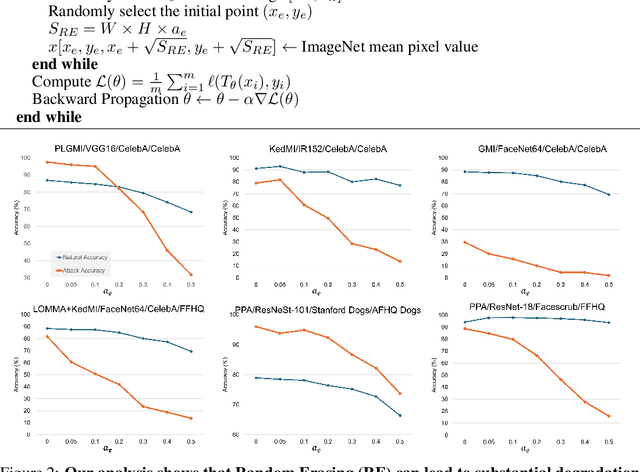

Model Inversion (MI) is a type of privacy violation that focuses on reconstructing private training data through abusive exploitation of machine learning models. To defend against MI attacks, state-of-the-art (SOTA) MI defense methods rely on regularizations that conflict with the training loss, creating explicit tension between privacy protection and model utility. In this paper, we present a new method to defend against MI attacks. Our method takes a new perspective and focuses on training data. Our idea is based on a novel insight on Random Erasing (RE), which has been applied in the past as a data augmentation technique to improve the model accuracy under occlusion. In our work, we instead focus on applying RE for degrading MI attack accuracy. Our key insight is that MI attacks require significant amount of private training data information encoded inside the model in order to reconstruct high-dimensional private images. Therefore, we propose to apply RE to reduce private information presented to the model during training. We show that this can lead to substantial degradation in MI reconstruction quality and attack accuracy. Meanwhile, natural accuracy of the model is only moderately affected. Our method is very simple to implement and complementary to existing defense methods. Our extensive experiments of 23 setups demonstrate that our method can achieve SOTA performance in balancing privacy and utility of the models. The results consistently demonstrate the superiority of our method over existing defenses across different MI attacks, network architectures, and attack configurations.
Towards Good Practices for Data Augmentation in GAN Training
Jun 09, 2020


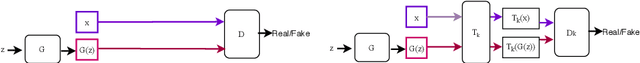
Recent successes in Generative Adversarial Networks (GAN) have affirmed the importance of using more data in GAN training. Yet it is expensive to collect data in many domains such as medical applications. Data Augmentation (DA) has been applied in these applications. In this work, we first argue that the classical DA approach could mislead the generator to learn the distribution of the augmented data, which could be different from that of the original data. We then propose a principled framework, termed Data Augmentation Optimized for GAN (DAG), to enable the use of augmented data in GAN training to improve the learning of the original distribution. We provide theoretical analysis to show that using our proposed DAG aligns with the original GAN in minimizing the JS divergence w.r.t. the original distribution and it leverages the augmented data to improve the learnings of discriminator and generator. The experiments show that DAG improves various GAN models. Furthermore, when DAG is used in some GAN models, the system establishes state-of-the-art Fr\'echet Inception Distance (FID) scores.
Self-supervised GAN: Analysis and Improvement with Multi-class Minimax Game
Nov 16, 2019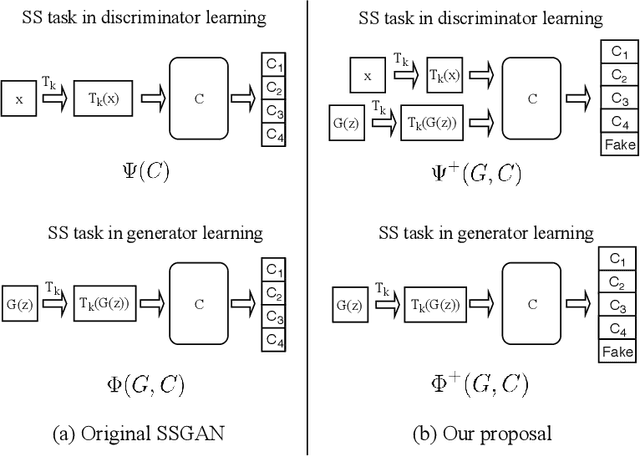
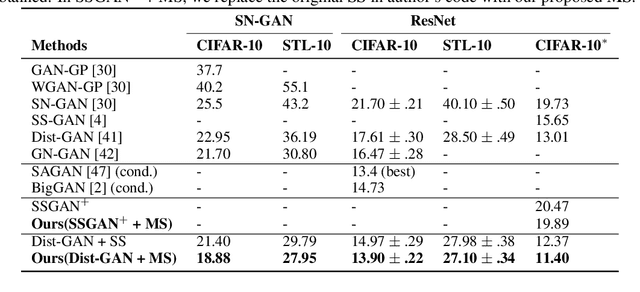


Self-supervised (SS) learning is a powerful approach for representation learning using unlabeled data. Recently, it has been applied to Generative Adversarial Networks (GAN) training. Specifically, SS tasks were proposed to address the catastrophic forgetting issue in the GAN discriminator. In this work, we perform an in-depth analysis to understand how SS tasks interact with learning of generator. From the analysis, we identify issues of SS tasks which allow a severely mode-collapsed generator to excel the SS tasks. To address the issues, we propose new SS tasks based on a multi-class minimax game. The competition between our proposed SS tasks in the game encourages the generator to learn the data distribution and generate diverse samples. We provide both theoretical and empirical analysis to support that our proposed SS tasks have better convergence property. We conduct experiments to incorporate our proposed SS tasks into two different GAN baseline models. Our approach establishes state-of-the-art FID scores on CIFAR-10, CIFAR-100, STL-10, CelebA, Imagenet $32\times32$ and Stacked-MNIST datasets, outperforming existing works by considerable margins in some cases. Our unconditional GAN model approaches performance of conditional GAN without using labeled data. Our code: \url{https://github.com/tntrung/msgan}
An Improved Self-supervised GAN via Adversarial Training
May 14, 2019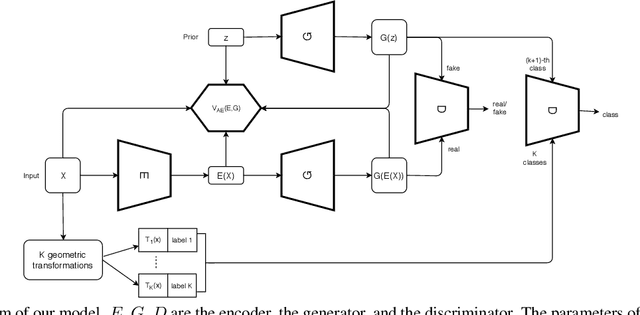

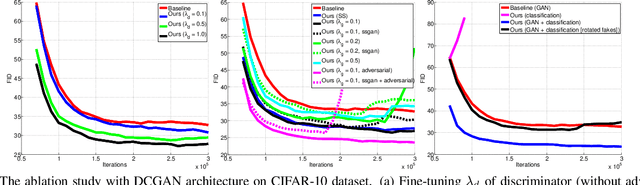
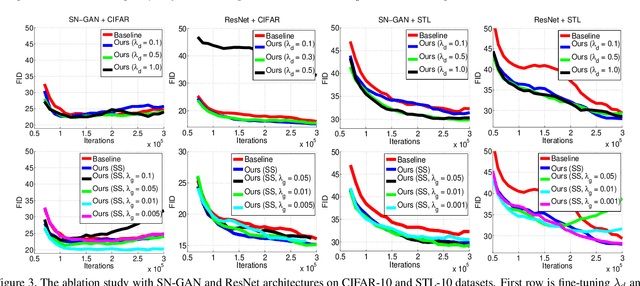
We propose to improve unconditional Generative Adversarial Networks (GAN) by training the self-supervised learning with the adversarial process. In particular, we apply self-supervised learning via the geometric transformation on input images and assign the pseudo-labels to these transformed images. (i) In addition to the GAN task, which distinguishes data (real) versus generated (fake) samples, we train the discriminator to predict the correct pseudo-labels of real transformed samples (classification task). Importantly, we find out that simultaneously training the discriminator to classify the fake class from the pseudo-classes of real samples for the classification task will improve the discriminator and subsequently lead better guides to train generator. (ii) The generator is trained by attempting to confuse the discriminator for not only the GAN task but also the classification task. For the classification task, the generator tries to confuse the discriminator recognizing the transformation of its output as one of the real transformed classes. Especially, we exploit that when the generator creates samples that result in a similar loss (via cross-entropy) as that of the real ones, the training is more stable and the generator distribution tends to match better the data distribution. When integrating our techniques into a state-of-the-art Auto-Encoder (AE) based-GAN model, they help to significantly boost the model's performance and also establish new state-of-the-art Fr\'echet Inception Distance (FID) scores in the literature of unconditional GAN for CIFAR-10 and STL-10 datasets.