 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending against Model Inversion Attacks via Random Erasing
Paper and Code
Sep 02, 2024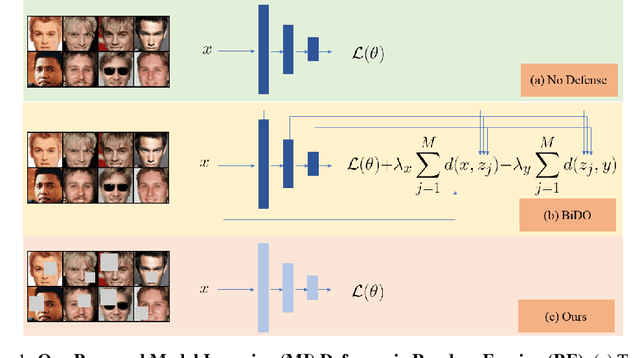

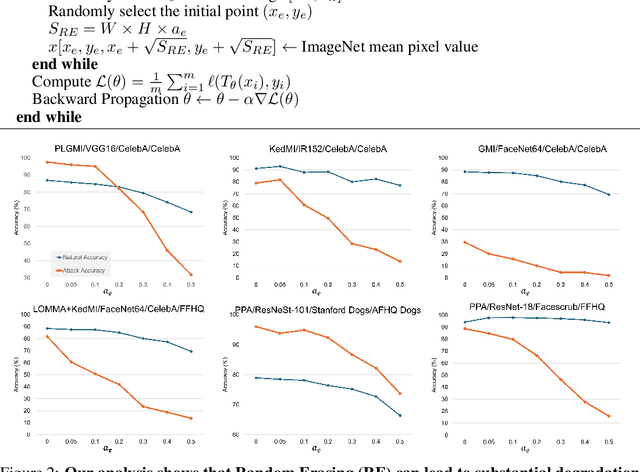

Model Inversion (MI) is a type of privacy violation that focuses on reconstructing private training data through abusive exploitation of machine learning models. To defend against MI attacks, state-of-the-art (SOTA) MI defense methods rely on regularizations that conflict with the training loss, creating explicit tension between privacy protection and model utility. In this paper, we present a new method to defend against MI attacks. Our method takes a new perspective and focuses on training data. Our idea is based on a novel insight on Random Erasing (RE), which has been applied in the past as a data augmentation technique to improve the model accuracy under occlusion. In our work, we instead focus on applying RE for degrading MI attack accuracy. Our key insight is that MI attacks require significant amount of private training data information encoded inside the model in order to reconstruct high-dimensional private images. Therefore, we propose to apply RE to reduce private information presented to the model during training. We show that this can lead to substantial degradation in MI reconstruction quality and attack accuracy. Meanwhile, natural accuracy of the model is only moderately affected. Our method is very simple to implement and complementary to existing defense methods. Our extensive experiments of 23 setups demonstrate that our method can achieve SOTA performance in balancing privacy and utility of the models. The results consistently demonstrate the superiority of our method over existing defenses across different MI attacks, network architectures, and attack configurations.