 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking the CoW with the TopCoW Challenge: Topology-Aware Anatomical Segmentation of the Circle of Willis for CTA and MRA
Dec 29, 2023



The Circle of Willis (CoW) is an important network of arteries connecting major circulations of the brain. Its vascular architecture is believed to affect the risk, severity, and clinical outcome of serious neuro-vascular diseases. However, characterizing the highly variable CoW anatomy is still a manual and time-consuming expert task. The CoW is usually imaged by two angiographic imaging modalities, magnetic resonance angiography (MRA) and computed tomography angiography (CTA), but there exist limited public datasets with annotations on CoW anatomy, especially for CTA. Therefore we organized the TopCoW Challenge in 2023 with the release of an annotated CoW dataset and invited submissions worldwide for the CoW segmentation task, which attracted over 140 registered participants from four continents. TopCoW dataset was the first public dataset with voxel-level annotations for CoW's 13 vessel components, made possible by virtual-reality (VR) technology. It was also the first dataset with paired MRA and CTA from the same patients. TopCoW challenge aimed to tackle the CoW characterization problem as a multiclass anatomical segmentation task with an emphasis on topological metrics. The top performing teams managed to segment many CoW components to Dice scores around 90%, but with lower scores for communicating arteries and rare variants. There were also topological mistakes for predictions with high Dice scores. Additional topological analysis revealed further areas for improvement in detecting certain CoW components and matching CoW variant's topology accurately. TopCoW represented a first attempt at benchmarking the CoW anatomical segmentation task for MRA and CTA, both morphologically and topologically.
Applying Deep Reinforcement Learning to the HP Model for Protein Structure Prediction
Dec 09, 2022



A central problem in computational biophysics is protein structure prediction, i.e., finding the optimal folding of a given amino acid sequence. This problem has been studied in a classical abstract model, the HP model, where the protein is modeled as a sequence of H (hydrophobic) and P (polar) amino acids on a lattice. The objective is to find conformations maximizing H-H contacts. It is known that even in this reduced setting, the problem is intractable (NP-hard). In this work, we apply deep reinforcement learning (DRL) to the two-dimensional HP model. We can obtain the conformations of best known energies for benchmark HP sequences with lengths from 20 to 50. Our DRL is based on a deep Q-network (DQN). We find that a DQN based on long short-term memory (LSTM) architecture greatly enhances the RL learning ability and significantly improves the search process. DRL can sample the state space efficiently, without the need of manual heuristics. Experimentally we show that it can find multiple distinct best-known solutions per trial. This study demonstrates the effectiveness of deep reinforcement learning in the HP model for protein folding.
A Closer Look at Few-shot Image Generation
May 08, 2022
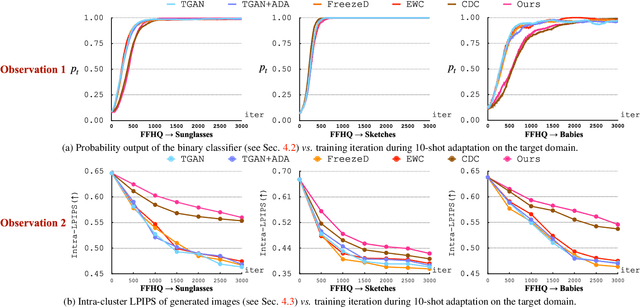

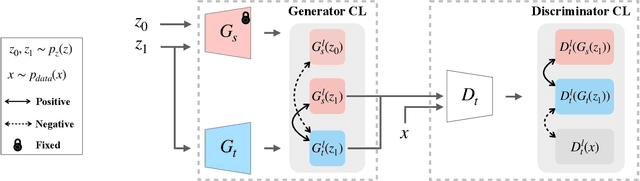
Modern GANs excel at generating high quality and diverse images. However, when transferring the pretrained GANs on small target data (e.g., 10-shot), the generator tends to replicate the training samples. Several methods have been proposed to address this few-shot image generation task, but there is a lack of effort to analyze them under a unified framework. As our first contribution, we propose a framework to analyze existing methods during the adaptation. Our analysis discovers that while some methods have disproportionate focus on diversity preserving which impede quality improvement, all methods achieve similar quality after convergence. Therefore, the better methods are those that can slow down diversity degradation. Furthermore, our analysis reveals that there is still plenty of room to further slow down diversity degradation. Informed by our analysis and to slow down the diversity degradation of the target generator during adaptation, our second contribution proposes to apply mutual information (MI) maximization to retain the source domain's rich multi-level diversity information in the target domain generator. We propose to perform MI maximization by contrastive loss (CL), leverage the generator and discriminator as two feature encoders to extract different multi-level features for computing CL. We refer to our method as Dual Contrastive Learning (DCL). Extensive experiments on several public datasets show that, while leading to a slower diversity-degrading generator during adaptation, our proposed DCL brings visually pleasant quality and state-of-the-art quantitative performance.
Rethinking of Pedestrian Attribute Recognition: A Reliable Evaluation under Zero-Shot Pedestrian Identity Setting
Jul 08, 2021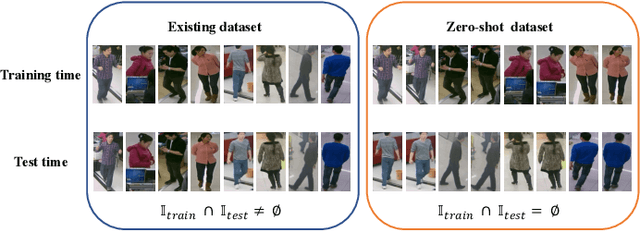


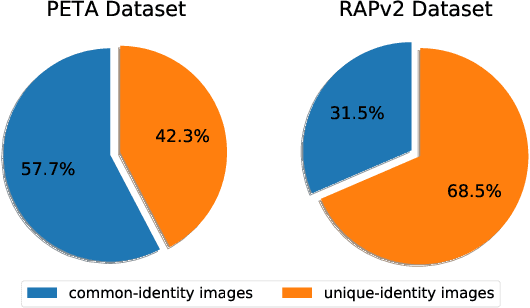
Pedestrian attribute recognition aims to assign multiple attributes to one pedestrian image captured by a video surveillance camera. Although numerous methods are proposed and make tremendous progress, we argue that it is time to step back and analyze the status quo of the area. We review and rethink the recent progress from three perspectives. First, given that there is no explicit and complete definition of pedestrian attribute recognition, we formally define and distinguish pedestrian attribute recognition from other similar tasks. Second, based on the proposed definition, we expose the limitations of the existing datasets, which violate the academic norm and are inconsistent with the essential requirement of practical industry application. Thus, we propose two datasets, PETA\textsubscript{$ZS$} and RAP\textsubscript{$ZS$}, constructed following the zero-shot settings on pedestrian identity. In addition, we also introduce several realistic criteria for future pedestrian attribute dataset construction. Finally, we reimplement existing state-of-the-art methods and introduce a strong baseline method to give reliable evaluations and fair comparisons. Experiments are conducted on four existing datasets and two proposed datasets to measure progress on pedestrian attribute recognition.
Rethinking of Pedestrian Attribute Recognition: Realistic Datasets with Efficient Method
May 26, 2020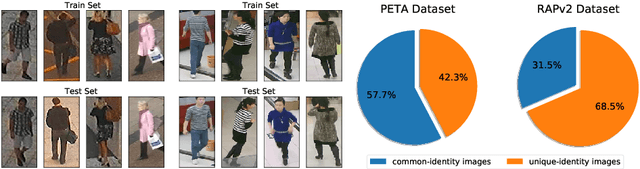
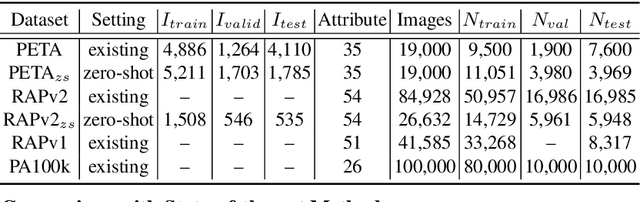
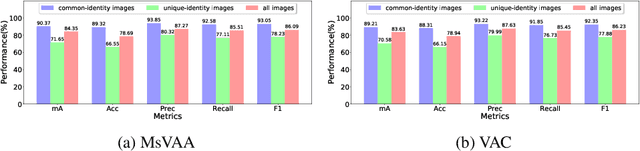
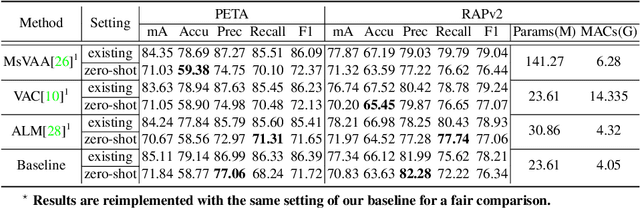
Despite various methods are proposed to make progress in pedestrian attribute recognition, a crucial problem on existing datasets is often neglected, namely, a large number of identical pedestrian identities in train and test set, which is not consistent with practical application. Thus, images of the same pedestrian identity in train set and test set are extremely similar, leading to overestimated performance of state-of-the-art methods on existing datasets. To address this problem, we propose two realistic datasets PETA\textsubscript{$zs$} and RAPv2\textsubscript{$zs$} following zero-shot setting of pedestrian identities based on PETA and RAPv2 datasets. Furthermore, compared to our strong baseline method, we have observed that recent state-of-the-art methods can not make performance improvement on PETA, RAPv2, PETA\textsubscript{$zs$} and RAPv2\textsubscript{$zs$}. Thus, through solving the inherent attribute imbalance in pedestrian attribute recognition, an efficient method is proposed to further improve the performance. Experiments on existing and proposed datasets verify the superiority of our method by achieving state-of-the-art performance.
EANet: Enhancing Alignment for Cross-Domain Person Re-identification
Dec 29, 2018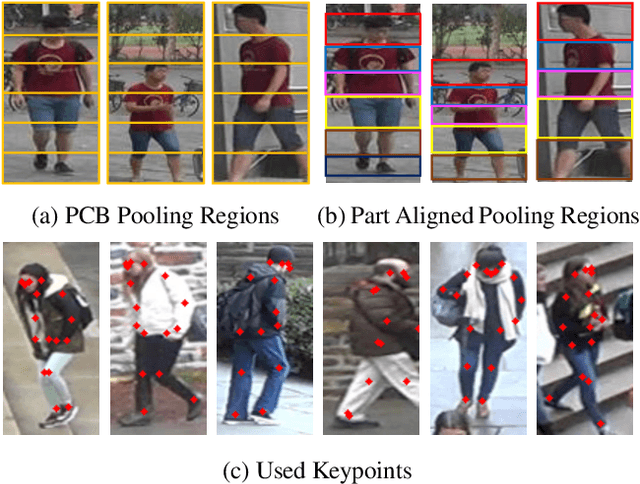

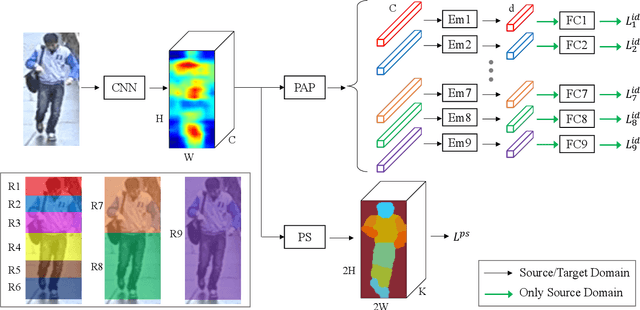

Person re-identification (ReID) has achieved significant improvement under the single-domain setting. However, directly exploiting a model to new domains is always faced with huge performance drop, and adapting the model to new domains without target-domain identity labels is still challenging. In this paper, we address cross-domain ReID and make contributions for both model generalization and adaptation. First, we propose Part Aligned Pooling (PAP) that brings significant improvement for cross-domain testing. Second, we design a Part Segmentation (PS) constraint over ReID feature to enhance alignment and improve model generalization. Finally, we show that applying our PS constraint to unlabeled target domain images serves as effective domain adaptation. We conduct extensive experiments between three large datasets, Market1501, CUHK03 and DukeMTMC-reID. Our model achieves state-of-the-art performance under both source-domain and cross-domain settings. For completeness, we also demonstrate the complementarity of our model to existing domain adaptation methods. The code is available at https://github.com/huanghoujing/EANet.