 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking of Pedestrian Attribute Recognition: Realistic Datasets with Efficient Method
Paper and Code
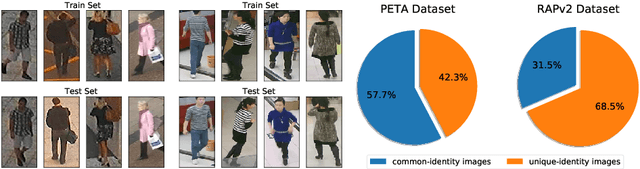
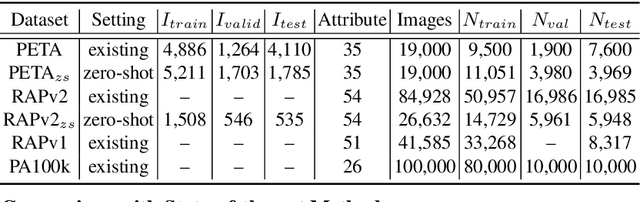
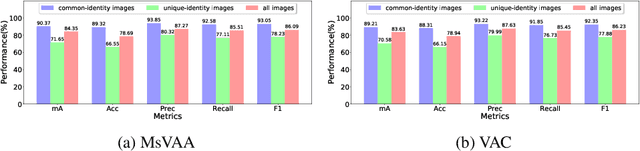
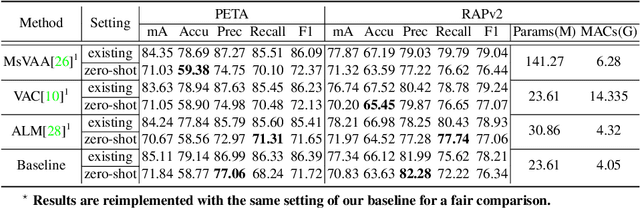
Despite various methods are proposed to make progress in pedestrian attribute recognition, a crucial problem on existing datasets is often neglected, namely, a large number of identical pedestrian identities in train and test set, which is not consistent with practical application. Thus, images of the same pedestrian identity in train set and test set are extremely similar, leading to overestimated performance of state-of-the-art methods on existing datasets. To address this problem, we propose two realistic datasets PETA\textsubscript{$zs$} and RAPv2\textsubscript{$zs$} following zero-shot setting of pedestrian identities based on PETA and RAPv2 datasets. Furthermore, compared to our strong baseline method, we have observed that recent state-of-the-art methods can not make performance improvement on PETA, RAPv2, PETA\textsubscript{$zs$} and RAPv2\textsubscript{$zs$}. Thus, through solving the inherent attribute imbalance in pedestrian attribute recognition, an efficient method is proposed to further improve the performance. Experiments on existing and proposed datasets verify the superiority of our method by achieving state-of-the-art performance.