 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMessage-Passing State-Space Models: Improving Graph Learning with Modern Sequence Modeling
May 24, 2025The recent success of State-Space Models (SSMs) in sequence modeling has motivated their adaptation to graph learning, giving rise to Graph State-Space Models (GSSMs). However, existing GSSMs operate by applying SSM modules to sequences extracted from graphs, often compromising core properties such as permutation equivariance, message-passing compatibility, and computational efficiency. In this paper, we introduce a new perspective by embedding the key principles of modern SSM computation directly into the Message-Passing Neural Network framework, resulting in a unified methodology for both static and temporal graphs. Our approach, MP-SSM, enables efficient, permutation-equivariant, and long-range information propagation while preserving the architectural simplicity of message passing. Crucially, MP-SSM enables an exact sensitivity analysis, which we use to theoretically characterize information flow and evaluate issues like vanishing gradients and over-squashing in the deep regime. Furthermore, our design choices allow for a highly optimized parallel implementation akin to modern SSMs. We validate MP-SSM across a wide range of tasks, including node classification, graph property prediction, long-range benchmarks, and spatiotemporal forecasting, demonstrating both its versatility and strong empirical performance.
RSFR: A Coarse-to-Fine Reconstruction Framework for Diffusion Tensor Cardiac MRI with Semantic-Aware Refinement
Apr 25, 2025Cardiac diffusion tensor imaging (DTI) offers unique insights into cardiomyocyte arrangements, bridging the gap between microscopic and macroscopic cardiac function. However, its clinical utility is limited by technical challenges, including a low signal-to-noise ratio, aliasing artefacts, and the need for accurate quantitative fidelity. To address these limitations, we introduce RSFR (Reconstruction, Segmentation, Fusion & Refinement), a novel framework for cardiac diffusion-weighted image reconstruction. RSFR employs a coarse-to-fine strategy, leveraging zero-shot semantic priors via the Segment Anything Model and a robust Vision Mamba-based reconstruction backbone. Our framework integrates semantic features effectively to mitigate artefacts and enhance fidelity, achieving state-of-the-art reconstruction quality and accurate DT parameter estimation under high undersampling rates. Extensive experiments and ablation studies demonstrate the superior performance of RSFR compared to existing methods, highlighting its robustness, scalability, and potential for clinical translation in quantitative cardiac DTI.
Towards Invariance to Node Identifiers in Graph Neural Networks
Feb 19, 2025Message-Passing Graph Neural Networks (GNNs) are known to have limited expressive power, due to their message passing structure. One mechanism for circumventing this limitation is to add unique node identifiers (IDs), which break the symmetries that underlie the expressivity limitation. In this work, we highlight a key limitation of the ID framework, and propose an approach for addressing it. We begin by observing that the final output of the GNN should clearly not depend on the specific IDs used. We then show that in practice this does not hold, and thus the learned network does not possess this desired structural property. Such invariance to node IDs may be enforced in several ways, and we discuss their theoretical properties. We then propose a novel regularization method that effectively enforces ID invariance to the network. Extensive evaluations on both real-world and synthetic tasks demonstrate that our approach significantly improves ID invariance and, in turn, often boosts generalization performance.
Celcomen: spatial causal disentanglement for single-cell and tissue perturbation modeling
Sep 09, 2024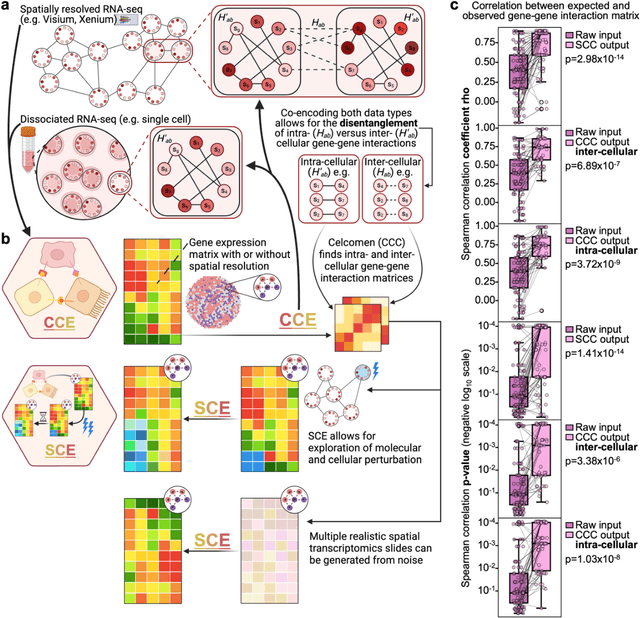
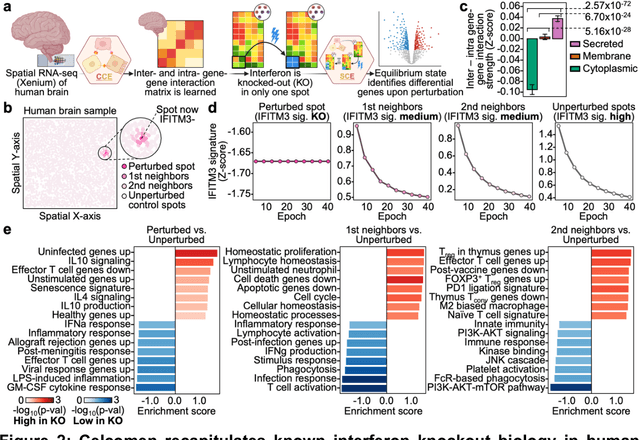
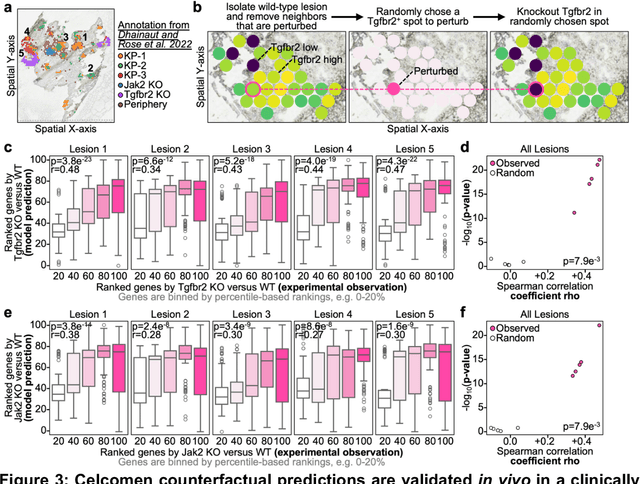
Celcomen leverages a mathematical causality framework to disentangle intra- and inter- cellular gene regulation programs in spatial transcriptomics and single-cell data through a generative graph neural network. It can learn gene-gene interactions, as well as generate post-perturbation counterfactual spatial transcriptomics, thereby offering access to experimentally inaccessible samples. We validated its disentanglement, identifiability, and counterfactual prediction capabilities through simulations and in clinically relevant human glioblastoma, human fetal spleen, and mouse lung cancer samples. Celcomen provides the means to model disease and therapy induced changes allowing for new insights into single-cell spatially resolved tissue responses relevant to human health.
Learning Task-Specific Sampling Strategy for Sparse-View CT Reconstruction
Sep 03, 2024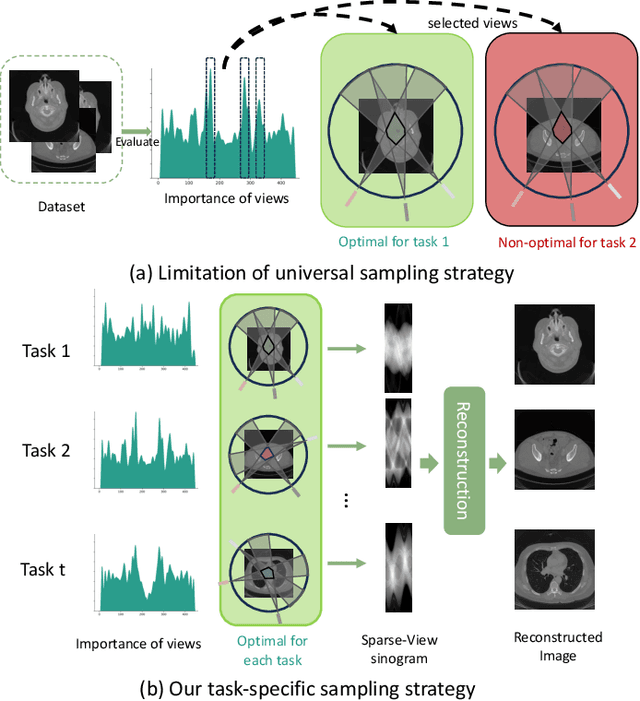
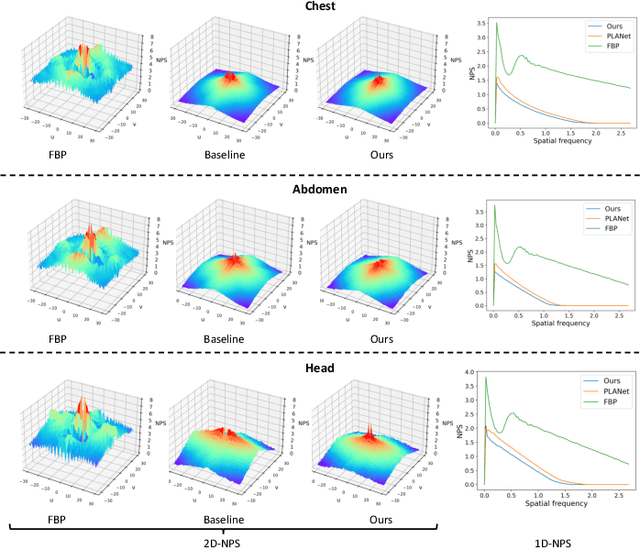

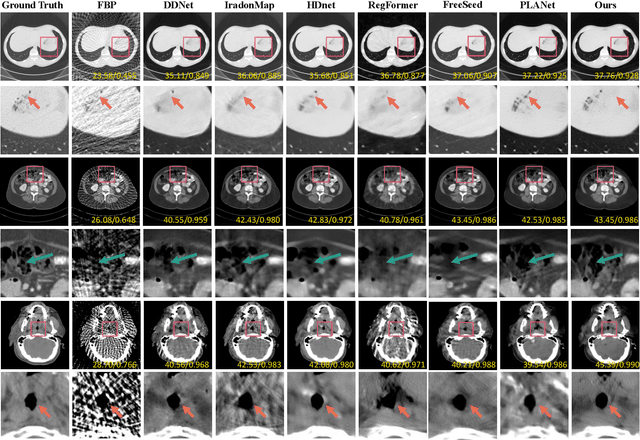
Sparse-View Computed Tomography (SVCT) offers low-dose and fast imaging but suffers from severe artifacts. Optimizing the sampling strategy is an essential approach to improving the imaging quality of SVCT. However, current methods typically optimize a universal sampling strategy for all types of scans, overlooking the fact that the optimal strategy may vary depending on the specific scanning task, whether it involves particular body scans (e.g., chest CT scans) or downstream clinical applications (e.g., disease diagnosis). The optimal strategy for one scanning task may not perform as well when applied to other tasks. To address this problem, we propose a deep learning framework that learns task-specific sampling strategies with a multi-task approach to train a unified reconstruction network while tailoring optimal sampling strategies for each individual task. Thus, a task-specific sampling strategy can be applied for each type of scans to improve the quality of SVCT imaging and further assist in performance of downstream clinical usage. Extensive experiments across different scanning types provide validation for the effectiveness of task-specific sampling strategies in enhancing imaging quality. Experiments involving downstream tasks verify the clinical value of learned sampling strategies, as evidenced by notable improvements in downstream task performance. Furthermore, the utilization of a multi-task framework with a shared reconstruction network facilitates deployment on current imaging devices with switchable task-specific modules, and allows for easily integrate new tasks without retraining the entire model.
Beyond U: Making Diffusion Models Faster & Lighter
Oct 31, 2023Diffusion models are a family of generative models that yield record-breaking performance in tasks such as image synthesis, video generation, and molecule design. Despite their capabilities, their efficiency, especially in the reverse denoising process, remains a challenge due to slow convergence rates and high computational costs. In this work, we introduce an approach that leverages continuous dynamical systems to design a novel denoising network for diffusion models that is more parameter-efficient, exhibits faster convergence, and demonstrates increased noise robustness. Experimenting with denoising probabilistic diffusion models, our framework operates with approximately a quarter of the parameters and 30% of the Floating Point Operations (FLOPs) compared to standard U-Nets in Denoising Diffusion Probabilistic Models (DDPMs). Furthermore, our model is up to 70% faster in inference than the baseline models when measured in equal conditions while converging to better quality solutions.
Deep Learning-based Diffusion Tensor Cardiac Magnetic Resonance Reconstruction: A Comparison Study
Apr 04, 2023In vivo cardiac diffusion tensor imaging (cDTI) is a promising Magnetic Resonance Imaging (MRI) technique for evaluating the micro-structure of myocardial tissue in the living heart, providing insights into cardiac function and enabling the development of innovative therapeutic strategies. However, the integration of cDTI into routine clinical practice is challenging due to the technical obstacles involved in the acquisition, such as low signal-to-noise ratio and long scanning times. In this paper, we investigate and implement three different types of deep learning-based MRI reconstruction models for cDTI reconstruction. We evaluate the performance of these models based on reconstruction quality assessment and diffusion tensor parameter assessment. Our results indicate that the models we discussed in this study can be applied for clinical use at an acceleration factor (AF) of $\times 2$ and $\times 4$, with the D5C5 model showing superior fidelity for reconstruction and the SwinMR model providing higher perceptual scores. There is no statistical difference with the reference for all diffusion tensor parameters at AF $\times 2$ or most DT parameters at AF $\times 4$, and the quality of most diffusion tensor parameter maps are visually acceptable. SwinMR is recommended as the optimal approach for reconstruction at AF $\times 2$ and AF $\times 4$. However, we believed the models discussed in this studies are not prepared for clinical use at a higher AF. At AF $\times 8$, the performance of all models discussed remains limited, with only half of the diffusion tensor parameters being recovered to a level with no statistical difference from the reference. Some diffusion tensor parameter maps even provide wrong and misleading information.
NorMatch: Matching Normalizing Flows with Discriminative Classifiers for Semi-Supervised Learning
Nov 17, 2022
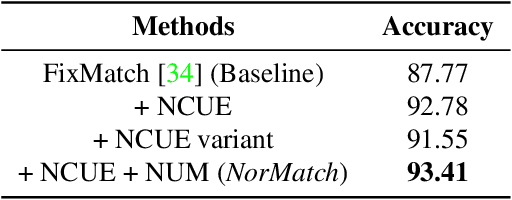
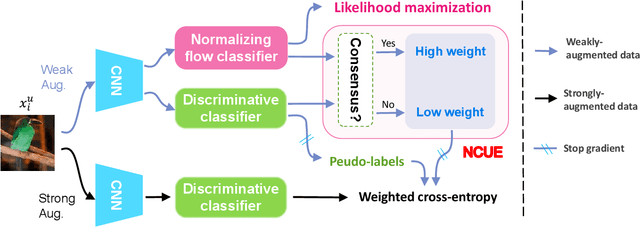

Semi-Supervised Learning (SSL) aims to learn a model using a tiny labeled set and massive amounts of unlabeled data. To better exploit the unlabeled data the latest SSL methods use pseudo-labels predicted from a single discriminative classifier. However, the generated pseudo-labels are inevitably linked to inherent confirmation bias and noise which greatly affects the model performance. In this work we introduce a new framework for SSL named NorMatch. Firstly, we introduce a new uncertainty estimation scheme based on normalizing flows, as an auxiliary classifier, to enforce highly certain pseudo-labels yielding a boost of the discriminative classifiers. Secondly, we introduce a threshold-free sample weighting strategy to exploit better both high and low confidence pseudo-labels. Furthermore, we utilize normalizing flows to model, in an unsupervised fashion, the distribution of unlabeled data. This modelling assumption can further improve the performance of generative classifiers via unlabeled data, and thus, implicitly contributing to training a better discriminative classifier. We demonstrate, through numerical and visual results, that NorMatch achieves state-of-the-art performance on several datasets.
TrafficCAM: A Versatile Dataset for Traffic Flow Segmentation
Nov 17, 2022



Traffic flow analysis is revolutionising traffic management. Qualifying traffic flow data, traffic control bureaus could provide drivers with real-time alerts, advising the fastest routes and therefore optimising transportation logistics and reducing congestion. The existing traffic flow datasets have two major limitations. They feature a limited number of classes, usually limited to one type of vehicle, and the scarcity of unlabelled data. In this paper, we introduce a new benchmark traffic flow image dataset called TrafficCAM. Our dataset distinguishes itself by two major highlights. Firstly, TrafficCAM provides both pixel-level and instance-level semantic labelling along with a large range of types of vehicles and pedestrians. It is composed of a large and diverse set of video sequences recorded in streets from eight Indian cities with stationary cameras. Secondly, TrafficCAM aims to establish a new benchmark for developing fully-supervised tasks, and importantly, semi-supervised learning techniques. It is the first dataset that provides a vast amount of unlabelled data, helping to better capture traffic flow qualification under a low cost annotation requirement. More precisely, our dataset has 4,402 image frames with semantic and instance annotations along with 59,944 unlabelled image frames. We validate our new dataset through a large and comprehensive range of experiments on several state-of-the-art approaches under four different settings: fully-supervised semantic and instance segmentation, and semi-supervised semantic and instance segmentation tasks. Our benchmark dataset will be released.
Image reconstruction in light-sheet microscopy: spatially varying deconvolution and mixed noise
Aug 08, 2021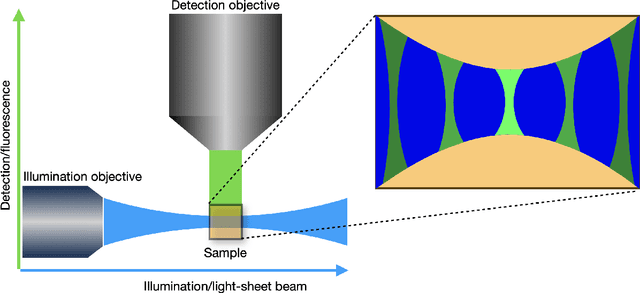
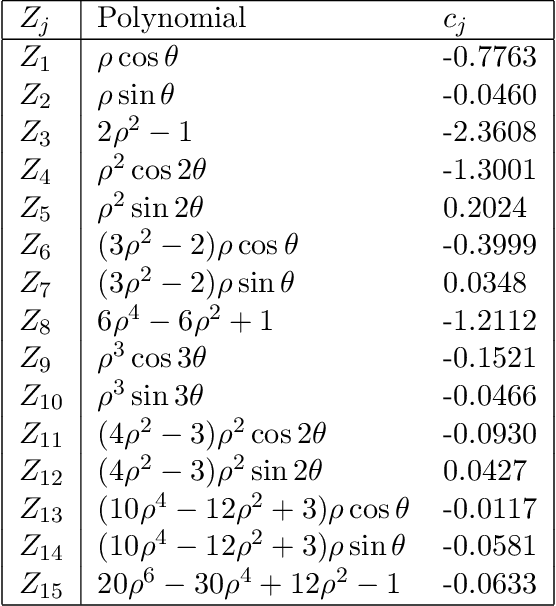

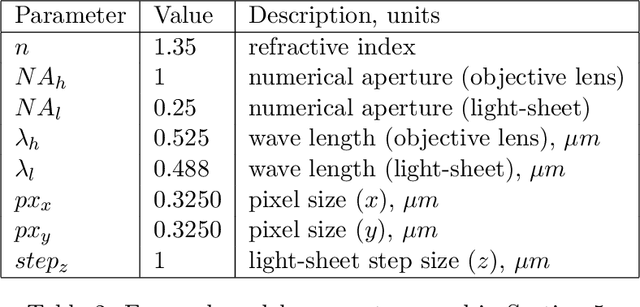
We study the problem of deconvolution for light-sheet microscopy, where the data is corrupted by spatially varying blur and a combination of Poisson and Gaussian noise. The spatial variation of the point spread function (PSF) of a light-sheet microscope is determined by the interaction between the excitation sheet and the detection objective PSF. First, we introduce a model of the image formation process that incorporates this interaction, therefore capturing the main characteristics of this imaging modality. Then, we formulate a variational model that accounts for the combination of Poisson and Gaussian noise through a data fidelity term consisting of the infimal convolution of the single noise fidelities, first introduced in L. Calatroni et al. "Infimal convolution of data discrepancies for mixed noise removal", SIAM Journal on Imaging Sciences 10.3 (2017), 1196-1233. We establish convergence rates in a Bregman distance under a source condition for the infimal convolution fidelity and a discrepancy principle for choosing the value of the regularisation parameter. The inverse problem is solved by applying the primal-dual hybrid gradient (PDHG) algorithm in a novel way. Finally, numerical experiments performed on both simulated and real data show superior reconstruction results in comparison with other methods.