 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNorMatch: Matching Normalizing Flows with Discriminative Classifiers for Semi-Supervised Learning
Nov 17, 2022
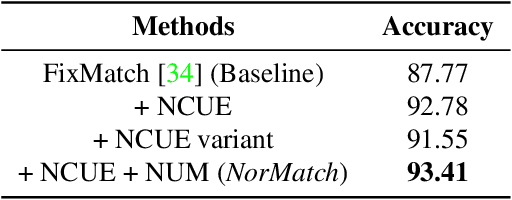
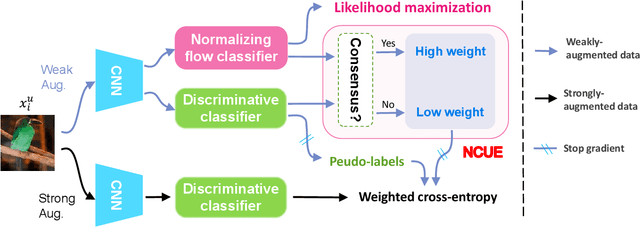

Semi-Supervised Learning (SSL) aims to learn a model using a tiny labeled set and massive amounts of unlabeled data. To better exploit the unlabeled data the latest SSL methods use pseudo-labels predicted from a single discriminative classifier. However, the generated pseudo-labels are inevitably linked to inherent confirmation bias and noise which greatly affects the model performance. In this work we introduce a new framework for SSL named NorMatch. Firstly, we introduce a new uncertainty estimation scheme based on normalizing flows, as an auxiliary classifier, to enforce highly certain pseudo-labels yielding a boost of the discriminative classifiers. Secondly, we introduce a threshold-free sample weighting strategy to exploit better both high and low confidence pseudo-labels. Furthermore, we utilize normalizing flows to model, in an unsupervised fashion, the distribution of unlabeled data. This modelling assumption can further improve the performance of generative classifiers via unlabeled data, and thus, implicitly contributing to training a better discriminative classifier. We demonstrate, through numerical and visual results, that NorMatch achieves state-of-the-art performance on several datasets.
TrafficCAM: A Versatile Dataset for Traffic Flow Segmentation
Nov 17, 2022



Traffic flow analysis is revolutionising traffic management. Qualifying traffic flow data, traffic control bureaus could provide drivers with real-time alerts, advising the fastest routes and therefore optimising transportation logistics and reducing congestion. The existing traffic flow datasets have two major limitations. They feature a limited number of classes, usually limited to one type of vehicle, and the scarcity of unlabelled data. In this paper, we introduce a new benchmark traffic flow image dataset called TrafficCAM. Our dataset distinguishes itself by two major highlights. Firstly, TrafficCAM provides both pixel-level and instance-level semantic labelling along with a large range of types of vehicles and pedestrians. It is composed of a large and diverse set of video sequences recorded in streets from eight Indian cities with stationary cameras. Secondly, TrafficCAM aims to establish a new benchmark for developing fully-supervised tasks, and importantly, semi-supervised learning techniques. It is the first dataset that provides a vast amount of unlabelled data, helping to better capture traffic flow qualification under a low cost annotation requirement. More precisely, our dataset has 4,402 image frames with semantic and instance annotations along with 59,944 unlabelled image frames. We validate our new dataset through a large and comprehensive range of experiments on several state-of-the-art approaches under four different settings: fully-supervised semantic and instance segmentation, and semi-supervised semantic and instance segmentation tasks. Our benchmark dataset will be released.
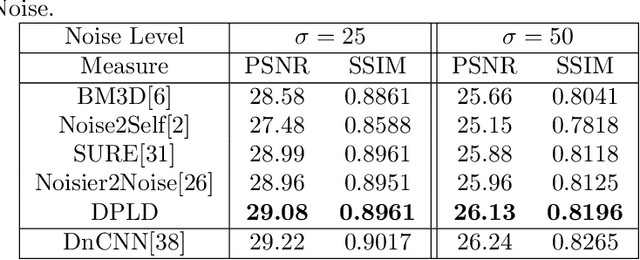
Deep Variation Prior: Joint Image Denoising and Noise Variance Estimation without Clean Data
Sep 19, 2022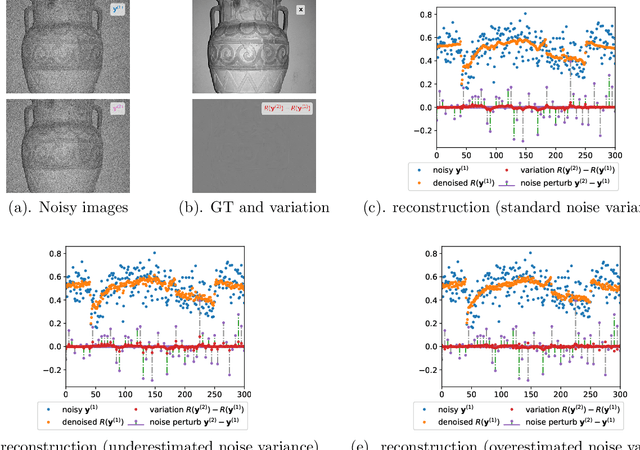
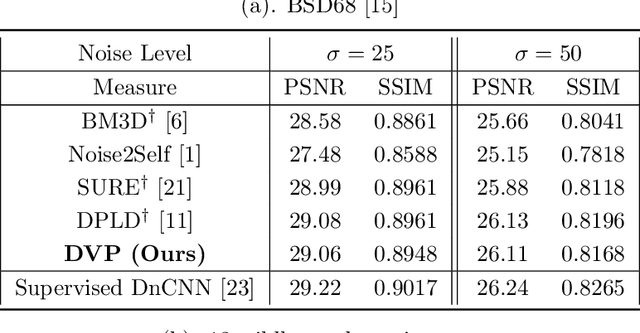
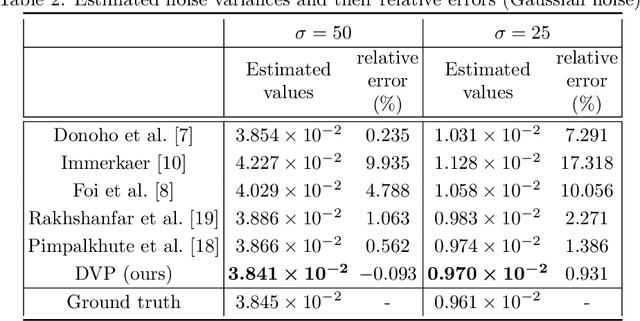

With recent deep learning based approaches showing promising results in removing noise from images, the best denoising performance has been reported in a supervised learning setup that requires a large set of paired noisy images and ground truth for training. The strong data requirement can be mitigated by unsupervised learning techniques, however, accurate modelling of images or noise variance is still crucial for high-quality solutions. The learning problem is ill-posed for unknown noise distributions. This paper investigates the tasks of image denoising and noise variance estimation in a single, joint learning framework. To address the ill-posedness of the problem, we present deep variation prior (DVP), which states that the variation of a properly learnt denoiser with respect to the change of noise satisfies some smoothness properties, as a key criterion for good denoisers. Building upon DVP, an unsupervised deep learning framework, that simultaneously learns a denoiser and estimates noise variances, is developed. Our method does not require any clean training images or an external step of noise estimation, and instead, approximates the minimum mean squared error denoisers using only a set of noisy images. With the two underlying tasks being considered in a single framework, we allow them to be optimised for each other. The experimental results show a denoising quality comparable to that of supervised learning and accurate noise variance estimates.
A Three-Stage Self-Training Framework for Semi-Supervised Semantic Segmentation
Dec 01, 2020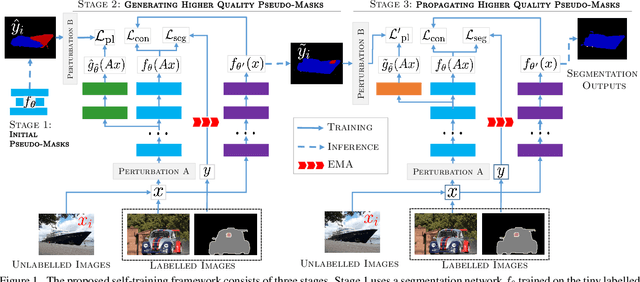
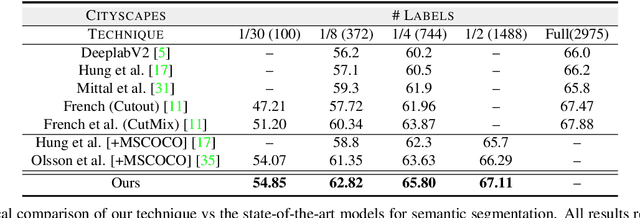
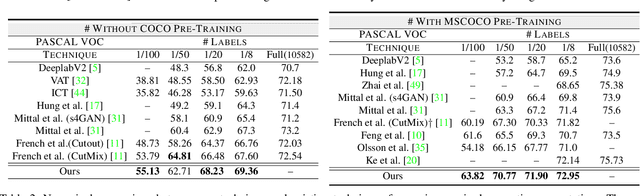

Semantic segmentation has been widely investigated in the community, in which the state of the art techniques are based on supervised models. Those models have reported unprecedented performance at the cost of requiring a large set of high quality segmentation masks. To obtain such annotations is highly expensive and time consuming, in particular, in semantic segmentation where pixel-level annotations are required. In this work, we address this problem by proposing a holistic solution framed as a three-stage self-training framework for semi-supervised semantic segmentation. The key idea of our technique is the extraction of the pseudo-masks statistical information to decrease uncertainty in the predicted probability whilst enforcing segmentation consistency in a multi-task fashion. We achieve this through a three-stage solution. Firstly, we train a segmentation network to produce rough pseudo-masks which predicted probability is highly uncertain. Secondly, we then decrease the uncertainty of the pseudo-masks using a multi-task model that enforces consistency whilst exploiting the rich statistical information of the data. We compare our approach with existing methods for semi-supervised semantic segmentation and demonstrate its state-of-the-art performance with extensive experiments.
Unsupervised Image Restoration Using Partially Linear Denoisers
Aug 14, 2020

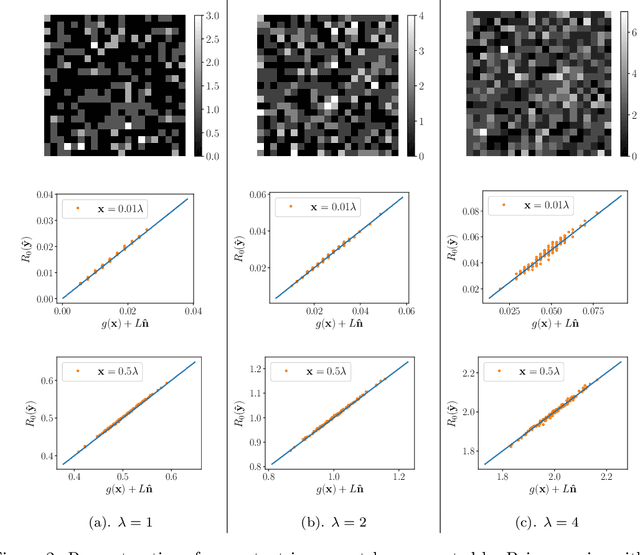
Deep neural network based methods are the state of the art in various image restoration problems. Standard supervised learning frameworks require a set of noisy measurement and clean image pairs for which a distance between the output of the restoration model and the ground truth, clean images is minimized. The ground truth images, however, are often unavailable or very expensive to acquire in real-world applications. We circumvent this problem by proposing a class of structured denoisers that can be decomposed as the sum of a nonlinear image-dependent mapping, a linear noise-dependent term and a small residual term. We show that these denoisers can be trained with only noisy images under the condition that the noise has zero mean and known variance. The exact distribution of the noise, however, is not assumed to be known. We show the superiority of our approach for image denoising, and demonstrate its extension to solving other restoration problems such as blind deblurring where the ground truth is not available. Our method outperforms some recent unsupervised and self-supervised deep denoising models that do not require clean images for their training. For blind deblurring problems, the method, using only one noisy and blurry observation per image, reaches a quality not far away from its fully supervised counterparts on a benchmark dataset.
iUNets: Fully invertible U-Nets with Learnable Up- and Downsampling
Jun 12, 2020
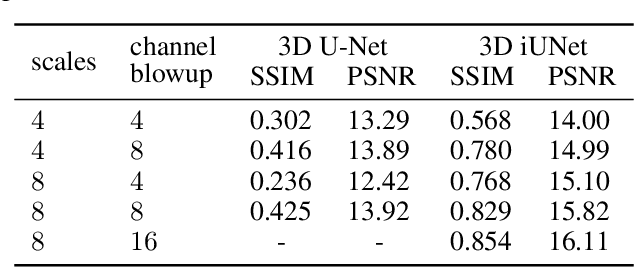
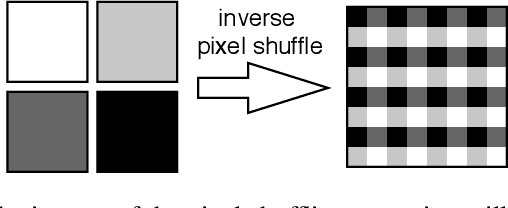
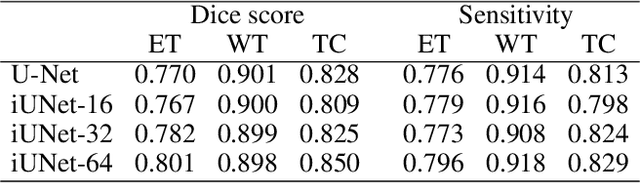
U-Nets have been established as a standard architecture for image-to-image learning problems such as segmentation and inverse problems in imaging. For large-scale data, as it for example appears in 3D medical imaging, the U-Net however has prohibitive memory requirements. Here, we present a new fully-invertible U-Net-based architecture called the iUNet, which employs novel learnable and invertible up- and downsampling operations, thereby making the use of memory-efficient backpropagation possible. This allows us to train deeper and larger networks in practice, under the same GPU memory restrictions. Due to its invertibility, the iUNet can furthermore be used for constructing normalizing flows.
Multi-task deep learning for image segmentation using recursive approximation tasks
May 26, 2020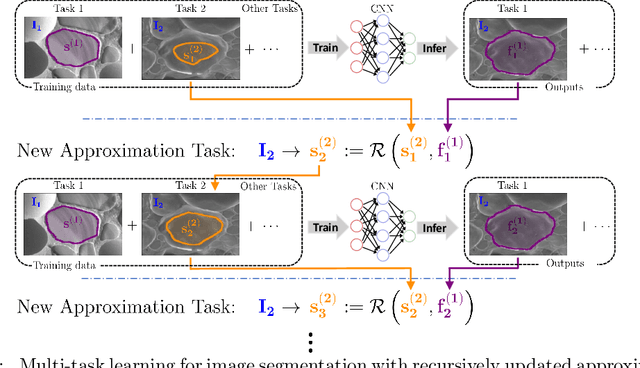
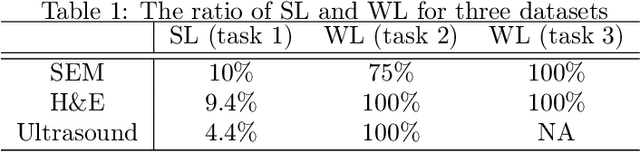
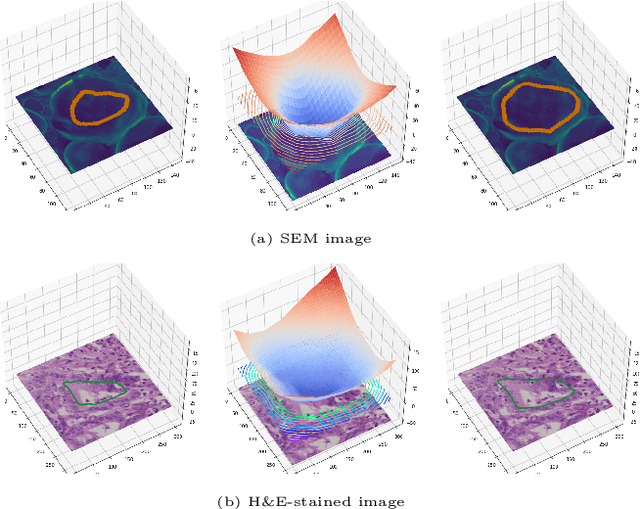

Fully supervised deep neural networks for segmentation usually require a massive amount of pixel-level labels which are manually expensive to create. In this work, we develop a multi-task learning method to relax this constraint. We regard the segmentation problem as a sequence of approximation subproblems that are recursively defined and in increasing levels of approximation accuracy. The subproblems are handled by a framework that consists of 1) a segmentation task that learns from pixel-level ground truth segmentation masks of a small fraction of the images, 2) a recursive approximation task that conducts partial object regions learning and data-driven mask evolution starting from partial masks of each object instance, and 3) other problem oriented auxiliary tasks that are trained with sparse annotations and promote the learning of dedicated features. Most training images are only labeled by (rough) partial masks, which do not contain exact object boundaries, rather than by their full segmentation masks. During the training phase, the approximation task learns the statistics of these partial masks, and the partial regions are recursively increased towards object boundaries aided by the learned information from the segmentation task in a fully data-driven fashion. The network is trained on an extremely small amount of precisely segmented images and a large set of coarse labels. Annotations can thus be obtained in a cheap way. We demonstrate the efficiency of our approach in three applications with microscopy images and ultrasound images.
A multi-task U-net for segmentation with lazy labels
Jun 20, 2019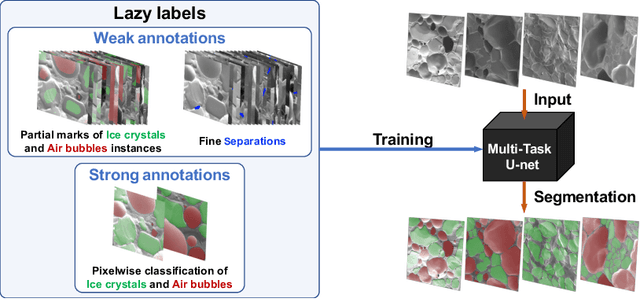
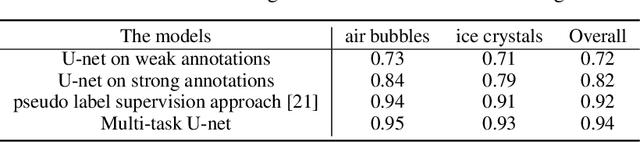


The need for labour intensive pixel-wise annotation is a major limitation of many fully supervised learning methods for image segmentation. In this paper, we propose a deep convolutional neural network for multi-class segmentation that circumvents this problem by being trainable on coarse data labels combined with only a very small number of images with pixel-wise annotations. We call this new labelling strategy 'lazy' labels. Image segmentation is then stratified into three connected tasks: rough detection of class instances, separation of wrongly connected objects without a clear boundary, and pixel-wise segmentation to find the accurate boundaries of each object. These problems are integrated into a multitask learning framework and the model is trained end-to-end in a semi-supervised fashion. The method is applied on a dataset of food microscopy images. We show that the model gives accurate segmentation results even if exact boundary labels are missing for a majority of the annotated data. This allows more flexibility and efficiency for training deep neural networks that are data hungry in a practical setting where manual annotation is expensive, by collecting more lazy (rough) annotations than precisely segmented images.