 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to estimate carbon footprint when training deep learning models? A guide and review
Jun 14, 2023Machine learning and deep learning models have become essential in the recent fast development of artificial intelligence in many sectors of the society. It is now widely acknowledge that the development of these models has an environmental cost that has been analyzed in many studies. Several online and software tools have been developed to track energy consumption while training machine learning models. In this paper, we propose a comprehensive introduction and comparison of these tools for AI practitioners wishing to start estimating the environmental impact of their work. We review the specific vocabulary, the technical requirements for each tool, and provide some advice on how and when to use these tools.
A patch-based architecture for multi-label classification from single label annotations
Sep 14, 2022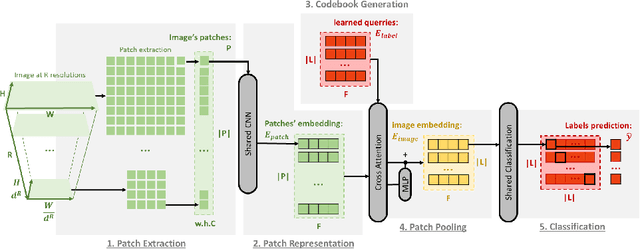
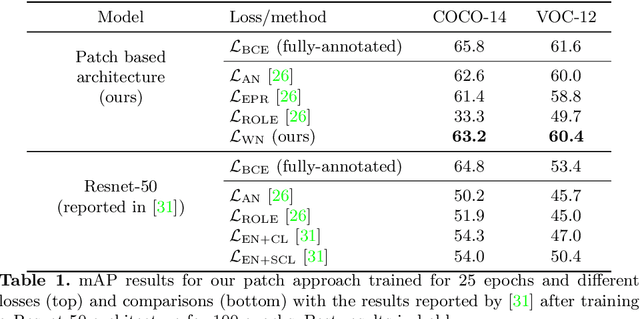
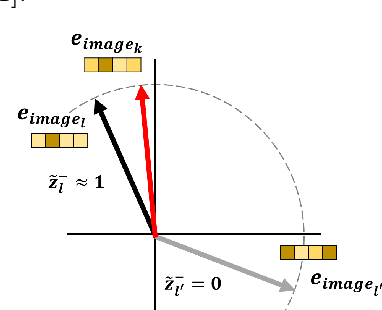

In this paper, we propose a patch-based architecture for multi-label classification problems where only a single positive label is observed in images of the dataset. Our contributions are twofold. First, we introduce a light patch architecture based on the attention mechanism. Next, leveraging on patch embedding self-similarities, we provide a novel strategy for estimating negative examples and deal with positive and unlabeled learning problems. Experiments demonstrate that our architecture can be trained from scratch, whereas pre-training on similar databases is required for related methods from the literature.
Analysis of Different Losses for Deep Learning Image Colorization
Apr 06, 2022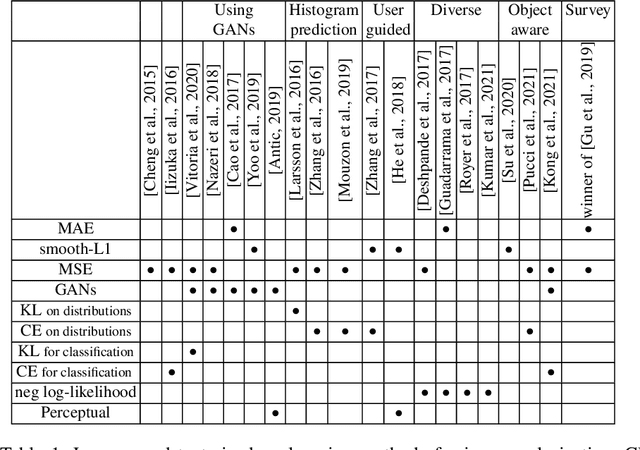
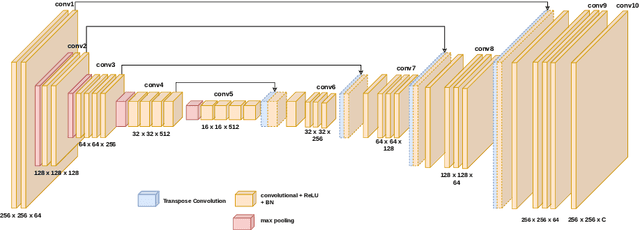
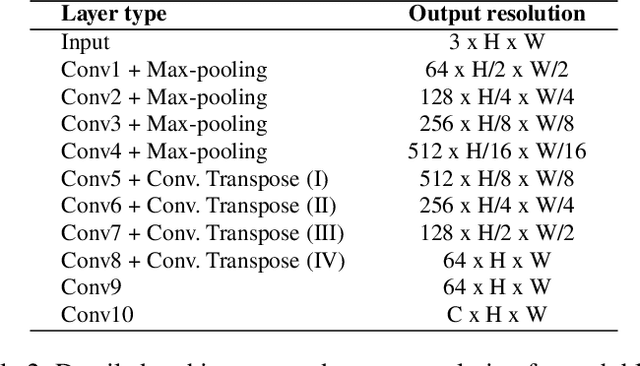

Image colorization aims to add color information to a grayscale image in a realistic way. Recent methods mostly rely on deep learning strategies. While learning to automatically colorize an image, one can define well-suited objective functions related to the desired color output. Some of them are based on a specific type of error between the predicted image and ground truth one, while other losses rely on the comparison of perceptual properties. But, is the choice of the objective function that crucial, i.e., does it play an important role in the results? In this chapter, we aim to answer this question by analyzing the impact of the loss function on the estimated colorization results. To that goal, we review the different losses and evaluation metrics that are used in the literature. We then train a baseline network with several of the reviewed objective functions: classic L1 and L2 losses, as well as more complex combinations such as Wasserstein GAN and VGG-based LPIPS loss. Quantitative results show that the models trained with VGG-based LPIPS provide overall slightly better results for most evaluation metrics. Qualitative results exhibit more vivid colors when with Wasserstein GAN plus the L2 loss or again with the VGG-based LPIPS. Finally, the convenience of quantitative user studies is also discussed to overcome the difficulty of properly assessing on colorized images, notably for the case of old archive photographs where no ground truth is available.
Influence of Color Spaces for Deep Learning Image Colorization
Apr 06, 2022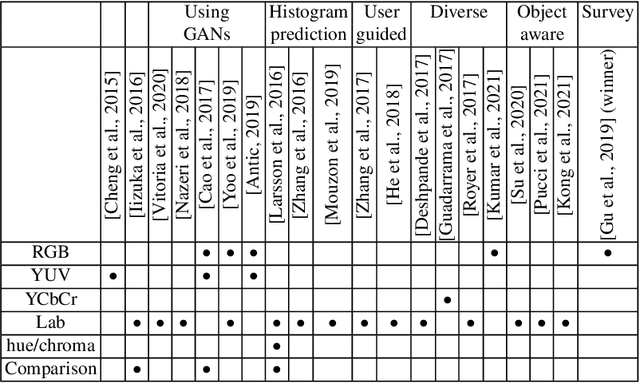

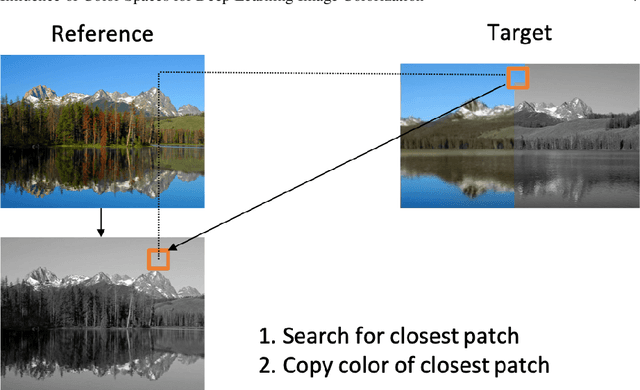
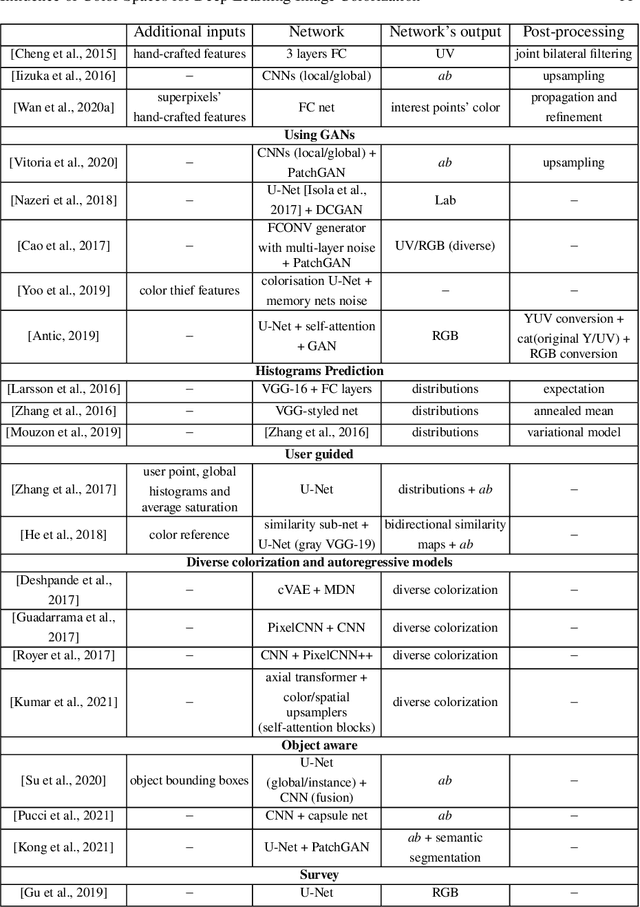
Colorization is a process that converts a grayscale image into a color one that looks as natural as possible. Over the years this task has received a lot of attention. Existing colorization methods rely on different color spaces: RGB, YUV, Lab, etc. In this chapter, we aim to study their influence on the results obtained by training a deep neural network, to answer the question: "Is it crucial to correctly choose the right color space in deep-learning based colorization?". First, we briefly summarize the literature and, in particular, deep learning-based methods. We then compare the results obtained with the same deep neural network architecture with RGB, YUV and Lab color spaces. Qualitative and quantitative analysis do not conclude similarly on which color space is better. We then show the importance of carefully designing the architecture and evaluation protocols depending on the types of images that are being processed and their specificities: strong/small contours, few/many objects, recent/archive images.
Unraveling the hidden environmental impacts of AI solutions for environment
Oct 22, 2021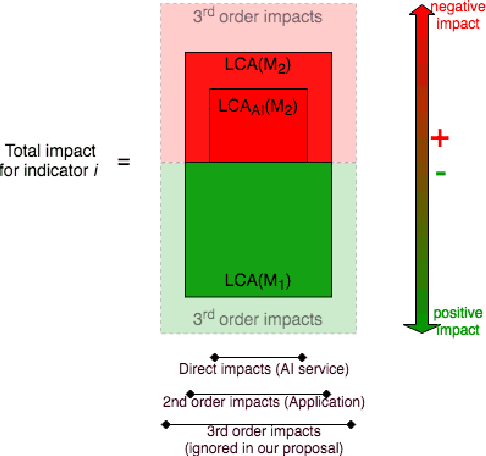
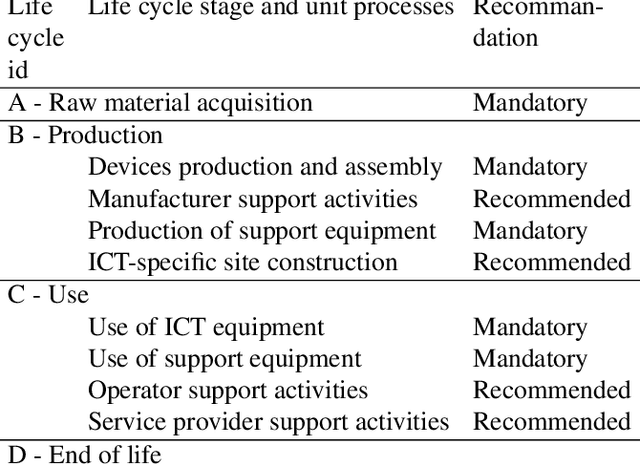


In the past ten years artificial intelligence has encountered such dramatic progress that it is seen now as a tool of choice to solve environmental issues and in the first place greenhouse gas emissions (GHG). At the same time the deep learning community began to realize that training models with more and more parameters required a lot of energy and as a consequence GHG emissions. To our knowledge, questioning the complete environmental impacts of AI methods for environment ("AI for green"), and not only GHG, has never been addressed directly. In this article we propose to study the possible negative impact of "AI for green" 1) by reviewing first the different types of AI impacts 2) by presenting the different methodologies used to assess those impacts, in particular life cycle assessment and 3) by discussing how to assess the environmental usefulness of a general AI service.
3D Object Detection and Pose Estimation of Unseen Objects in Color Images with Local Surface Embeddings
Oct 08, 2020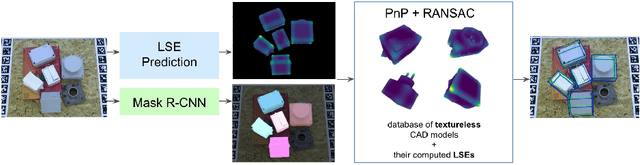

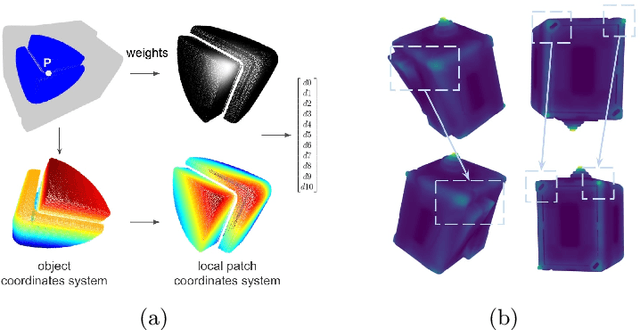

We present an approach for detecting and estimating the 3D poses of objects in images that requires only an untextured CAD model and no training phase for new objects. Our approach combines Deep Learning and 3D geometry: It relies on an embedding of local 3D geometry to match the CAD models to the input images. For points at the surface of objects, this embedding can be computed directly from the CAD model; for image locations, we learn to predict it from the image itself. This establishes correspondences between 3D points on the CAD model and 2D locations of the input images. However, many of these correspondences are ambiguous as many points may have similar local geometries. We show that we can use Mask-RCNN in a class-agnostic way to detect the new objects without retraining and thus drastically limit the number of possible correspondences. We can then robustly estimate a 3D pose from these discriminative correspondences using a RANSAC- like algorithm. We demonstrate the performance of this approach on the T-LESS dataset, by using a small number of objects to learn the embedding and testing it on the other objects. Our experiments show that our method is on par or better than previous methods.
Multi-task deep learning for image segmentation using recursive approximation tasks
May 26, 2020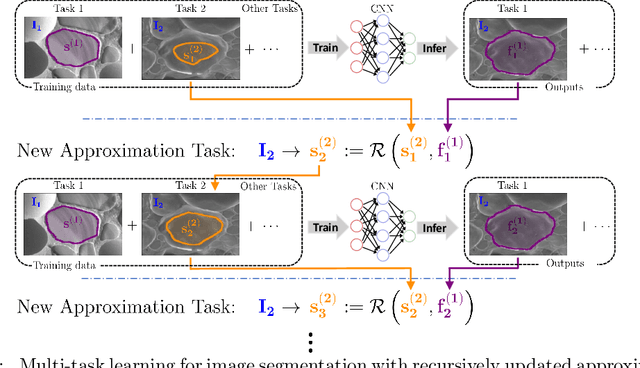
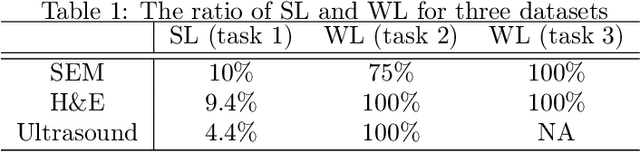
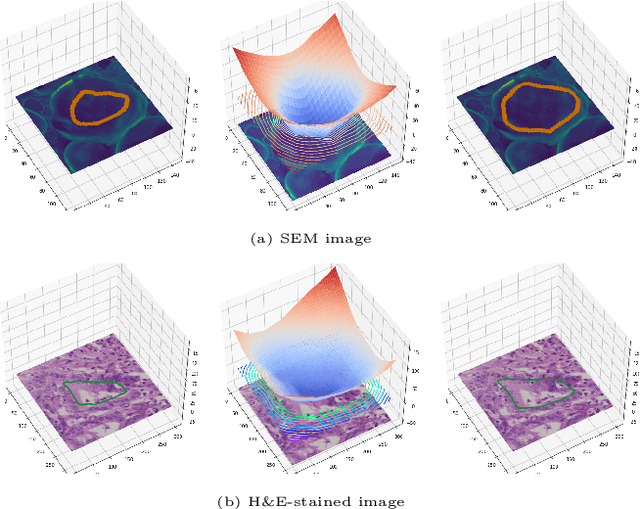

Fully supervised deep neural networks for segmentation usually require a massive amount of pixel-level labels which are manually expensive to create. In this work, we develop a multi-task learning method to relax this constraint. We regard the segmentation problem as a sequence of approximation subproblems that are recursively defined and in increasing levels of approximation accuracy. The subproblems are handled by a framework that consists of 1) a segmentation task that learns from pixel-level ground truth segmentation masks of a small fraction of the images, 2) a recursive approximation task that conducts partial object regions learning and data-driven mask evolution starting from partial masks of each object instance, and 3) other problem oriented auxiliary tasks that are trained with sparse annotations and promote the learning of dedicated features. Most training images are only labeled by (rough) partial masks, which do not contain exact object boundaries, rather than by their full segmentation masks. During the training phase, the approximation task learns the statistics of these partial masks, and the partial regions are recursively increased towards object boundaries aided by the learned information from the segmentation task in a fully data-driven fashion. The network is trained on an extremely small amount of precisely segmented images and a large set of coarse labels. Annotations can thus be obtained in a cheap way. We demonstrate the efficiency of our approach in three applications with microscopy images and ultrasound images.
Variational Osmosis for Non-linear Image Fusion
Oct 04, 2019



We propose a new variational model for nonlinear image fusion. Our approach incorporates the osmosis model proposed in Vogel et al. (2013) and Weickert et al. (2013) as an energy term in a variational model. The osmosis energy is known to realize visually plausible image data fusion. As a consequence, our method is invariant to multiplicative brightness changes. On the practical side, it requires minimal supervision and parameter tuning and can encode prior information on the structure of the images to be fused. We develop a primal-dual algorithm for solving this new image fusion model and we apply the resulting minimisation scheme to multi-modal image fusion for face fusion, colour transfer and some cultural heritage conservation challenges. Visual comparison to state-of-the-art proves the quality and flexibility of our method.
LU-Net: An Efficient Network for 3D LiDAR Point Cloud Semantic Segmentation Based on End-to-End-Learned 3D Features and U-Net
Aug 30, 2019
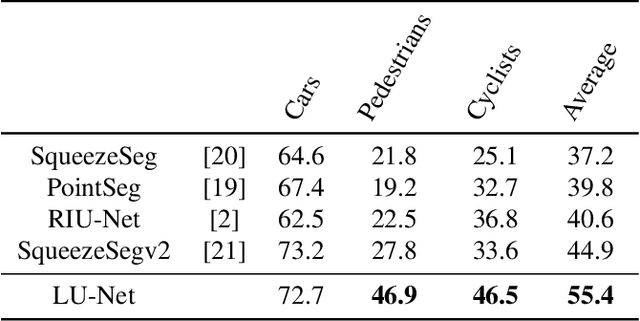

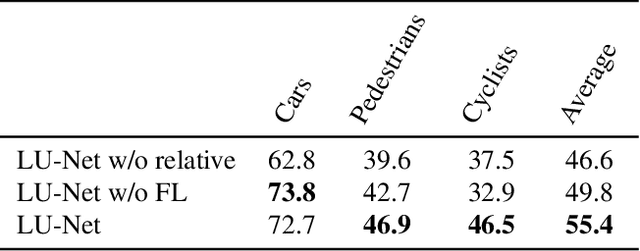
We propose LU-Net -- for LiDAR U-Net, a new method for the semantic segmentation of a 3D LiDAR point cloud. Instead of applying some global 3D segmentation method such as PointNet, we propose an end-to-end architecture for LiDAR point cloud semantic segmentation that efficiently solves the problem as an image processing problem. We first extract high-level 3D features for each point given its 3D neighbors. Then, these features are projected into a 2D multichannel range-image by considering the topology of the sensor. Thanks to these learned features and this projection, we can finally perform the segmentation using a simple U-Net segmentation network, which performs very well while being very efficient. In this way, we can exploit both the 3D nature of the data and the specificity of the LiDAR sensor. This approach outperforms the state-of-the-art by a large margin on the KITTI dataset, as our experiments show. Moreover, this approach operates at 24fps on a single GPU. This is above the acquisition rate of common LiDAR sensors which makes it suitable for real-time applications.
A multi-task U-net for segmentation with lazy labels
Jun 20, 2019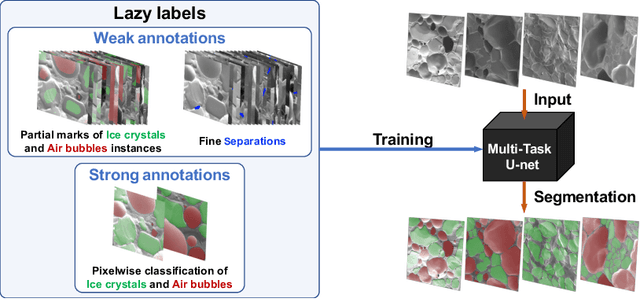
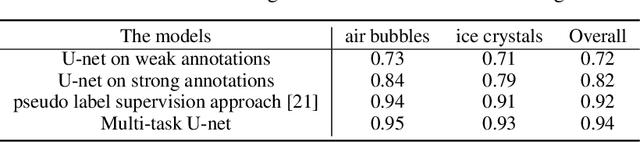


The need for labour intensive pixel-wise annotation is a major limitation of many fully supervised learning methods for image segmentation. In this paper, we propose a deep convolutional neural network for multi-class segmentation that circumvents this problem by being trainable on coarse data labels combined with only a very small number of images with pixel-wise annotations. We call this new labelling strategy 'lazy' labels. Image segmentation is then stratified into three connected tasks: rough detection of class instances, separation of wrongly connected objects without a clear boundary, and pixel-wise segmentation to find the accurate boundaries of each object. These problems are integrated into a multitask learning framework and the model is trained end-to-end in a semi-supervised fashion. The method is applied on a dataset of food microscopy images. We show that the model gives accurate segmentation results even if exact boundary labels are missing for a majority of the annotated data. This allows more flexibility and efficiency for training deep neural networks that are data hungry in a practical setting where manual annotation is expensive, by collecting more lazy (rough) annotations than precisely segmented images.