 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperpixel Anything: A general object-based framework for accurate yet regular superpixel segmentation
Sep 16, 2025Superpixels are widely used in computer vision to simplify image representation and reduce computational complexity. While traditional methods rely on low-level features, deep learning-based approaches leverage high-level features but also tend to sacrifice regularity of superpixels to capture complex objects, leading to accurate but less interpretable segmentations. In this work, we introduce SPAM (SuperPixel Anything Model), a versatile framework for segmenting images into accurate yet regular superpixels. We train a model to extract image features for superpixel generation, and at inference, we leverage a large-scale pretrained model for semantic-agnostic segmentation to ensure that superpixels align with object masks. SPAM can handle any prior high-level segmentation, resolving uncertainty regions, and is able to interactively focus on specific objects. Comprehensive experiments demonstrate that SPAM qualitatively and quantitatively outperforms state-of-the-art methods on segmentation tasks, making it a valuable and robust tool for various applications. Code and pre-trained models are available here: https://github.com/waldo-j/spam.
Handling Multiple Hypotheses in Coarse-to-Fine Dense Image Matching
Sep 10, 2025Dense image matching aims to find a correspondent for every pixel of a source image in a partially overlapping target image. State-of-the-art methods typically rely on a coarse-to-fine mechanism where a single correspondent hypothesis is produced per source location at each scale. In challenging cases -- such as at depth discontinuities or when the target image is a strong zoom-in of the source image -- the correspondents of neighboring source locations are often widely spread and predicting a single correspondent hypothesis per source location at each scale may lead to erroneous matches. In this paper, we investigate the idea of predicting multiple correspondent hypotheses per source location at each scale instead. We consider a beam search strategy to propagat multiple hypotheses at each scale and propose integrating these multiple hypotheses into cross-attention layers, resulting in a novel dense matching architecture called BEAMER. BEAMER learns to preserve and propagate multiple hypotheses across scales, making it significantly more robust than state-of-the-art methods, especially at depth discontinuities or when the target image is a strong zoom-in of the source image.
FLAIRBrainSeg: Fine-grained brain segmentation using FLAIR MRI only
Apr 04, 2025This paper introduces a novel method for brain segmentation using only FLAIR MRIs, specifically targeting cases where access to other imaging modalities is limited. By leveraging existing automatic segmentation methods, we train a network to approximate segmentations, typically obtained from T1-weighted MRIs. Our method, called FLAIRBrainSeg, produces segmentations of 132 structures and is robust to multiple sclerosis lesions. Experiments on both in-domain and out-of-domain datasets demonstrate that our method outperforms modality-agnostic approaches based on image synthesis, the only currently available alternative for performing brain parcellation using FLAIR MRI alone. This technique holds promise for scenarios where T1-weighted MRIs are unavailable and offers a valuable alternative for clinicians and researchers in need of reliable anatomical segmentation.
Ultra-high resolution multimodal MRI dense labelled holistic brain atlas
Jan 28, 2025



In this paper, we introduce holiAtlas, a holistic, multimodal and high-resolution human brain atlas. This atlas covers different levels of details of the human brain anatomy, from the organ to the substructure level, using a new dense labelled protocol generated from the fusion of multiple local protocols at different scales. This atlas has been constructed averaging images and segmentations of 75 healthy subjects from the Human Connectome Project database. Specifically, MR images of T1, T2 and WMn (White Matter nulled) contrasts at 0.125 $mm^{3}$ resolution that were nonlinearly registered and averaged using symmetric group-wise normalisation to construct the atlas. At the finest level, the holiAtlas protocol has 350 different labels derived from 10 different delineation protocols. These labels were grouped at different scales to provide a holistic view of the brain at different levels in a coherent and consistent manner. This multiscale and multimodal atlas can be used for the development of new ultra-high resolution segmentation methods that can potentially leverage the early detection of neurological disorders.
Superpixel Segmentation: A Long-Lasting Ill-Posed Problem
Nov 10, 2024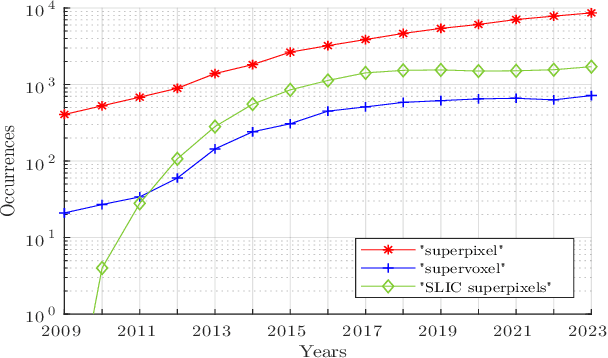
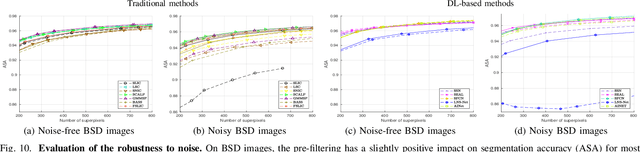
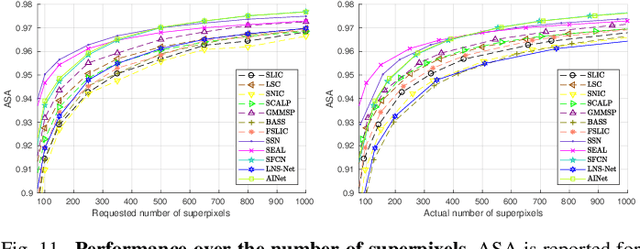

For many years, image over-segmentation into superpixels has been essential to computer vision pipelines, by creating homogeneous and identifiable regions of similar sizes. Such constrained segmentation problem would require a clear definition and specific evaluation criteria. However, the validation framework for superpixel methods, typically viewed as standard object segmentation, has rarely been thoroughly studied. In this work, we first take a step back to show that superpixel segmentation is fundamentally an ill-posed problem, due to the implicit regularity constraint on the shape and size of superpixels. We also demonstrate through a novel comprehensive study that the literature suffers from only evaluating certain aspects, sometimes incorrectly and with inappropriate metrics. Concurrently, recent deep learning-based superpixel methods mainly focus on the object segmentation task at the expense of regularity. In this ill-posed context, we show that we can achieve competitive results using a recent architecture like the Segment Anything Model (SAM), without dedicated training for the superpixel segmentation task. This leads to rethinking superpixel segmentation and the necessary properties depending on the targeted downstream task.
Deep Spherical Superpixels
Jul 24, 2024Over the years, the use of superpixel segmentation has become very popular in various applications, serving as a preprocessing step to reduce data size by adapting to the content of the image, regardless of its semantic content. While the superpixel segmentation of standard planar images, captured with a 90{\deg} field of view, has been extensively studied, there has been limited focus on dedicated methods to omnidirectional or spherical images, captured with a 360{\deg} field of view. In this study, we introduce the first deep learning-based superpixel segmentation approach tailored for omnidirectional images called DSS (for Deep Spherical Superpixels). Our methodology leverages on spherical CNN architectures and the differentiable K-means clustering paradigm for superpixels, to generate superpixels that follow the spherical geometry. Additionally, we propose to use data augmentation techniques specifically designed for 360{\deg} images, enabling our model to efficiently learn from a limited set of annotated omnidirectional data. Our extensive validation across two datasets demonstrates that taking into account the inherent circular geometry of such images into our framework improves the segmentation performance over traditional and deep learning-based superpixel methods. Our code is available online.
Are Semi-Dense Detector-Free Methods Good at Matching Local Features?
Feb 13, 2024



Semi-dense detector-free approaches (SDF), such as LoFTR, are currently among the most popular image matching methods. While SDF methods are trained to establish correspondences between two images, their performances are almost exclusively evaluated using relative pose estimation metrics. Thus, the link between their ability to establish correspondences and the quality of the resulting estimated pose has thus far received little attention. This paper is a first attempt to study this link. We start with proposing a novel structured attention-based image matching architecture (SAM). It allows us to show a counter-intuitive result on two datasets (MegaDepth and HPatches): on the one hand SAM either outperforms or is on par with SDF methods in terms of pose/homography estimation metrics, but on the other hand SDF approaches are significantly better than SAM in terms of matching accuracy. We then propose to limit the computation of the matching accuracy to textured regions, and show that in this case SAM often surpasses SDF methods. Our findings highlight a strong correlation between the ability to establish accurate correspondences in textured regions and the accuracy of the resulting estimated pose/homography. Our code will be made available.
Analysis of Different Losses for Deep Learning Image Colorization
Apr 06, 2022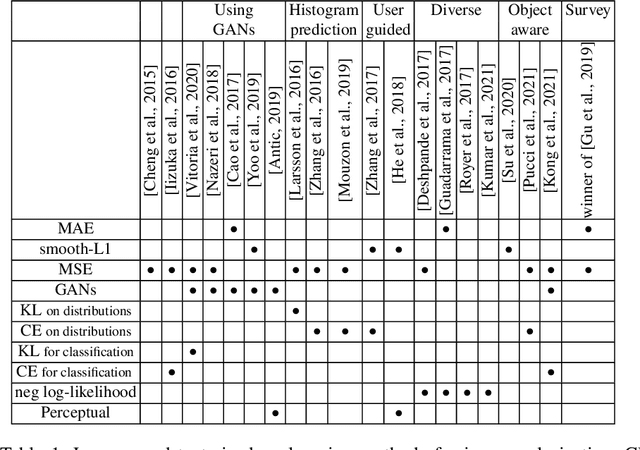
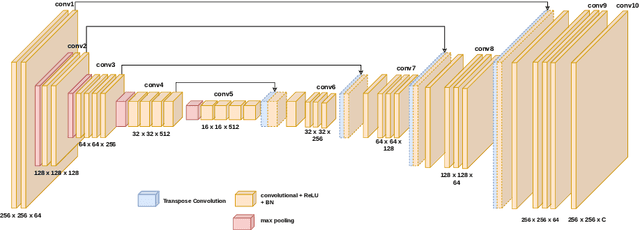
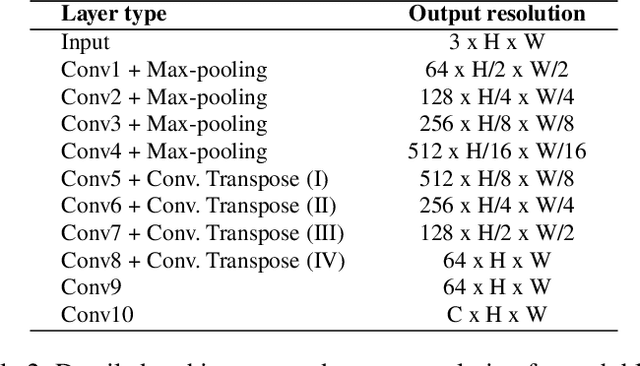

Image colorization aims to add color information to a grayscale image in a realistic way. Recent methods mostly rely on deep learning strategies. While learning to automatically colorize an image, one can define well-suited objective functions related to the desired color output. Some of them are based on a specific type of error between the predicted image and ground truth one, while other losses rely on the comparison of perceptual properties. But, is the choice of the objective function that crucial, i.e., does it play an important role in the results? In this chapter, we aim to answer this question by analyzing the impact of the loss function on the estimated colorization results. To that goal, we review the different losses and evaluation metrics that are used in the literature. We then train a baseline network with several of the reviewed objective functions: classic L1 and L2 losses, as well as more complex combinations such as Wasserstein GAN and VGG-based LPIPS loss. Quantitative results show that the models trained with VGG-based LPIPS provide overall slightly better results for most evaluation metrics. Qualitative results exhibit more vivid colors when with Wasserstein GAN plus the L2 loss or again with the VGG-based LPIPS. Finally, the convenience of quantitative user studies is also discussed to overcome the difficulty of properly assessing on colorized images, notably for the case of old archive photographs where no ground truth is available.
Influence of Color Spaces for Deep Learning Image Colorization
Apr 06, 2022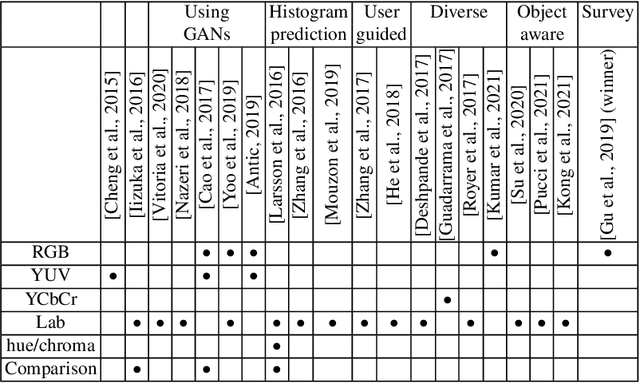

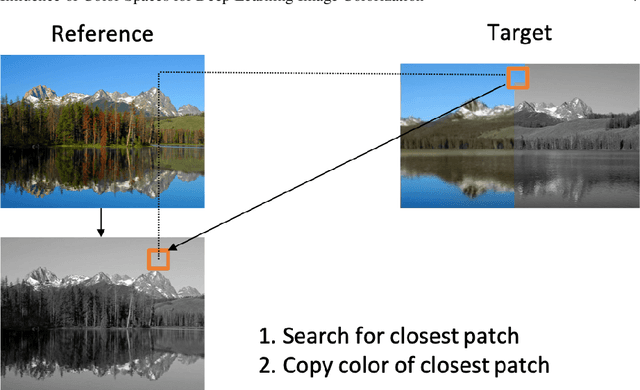
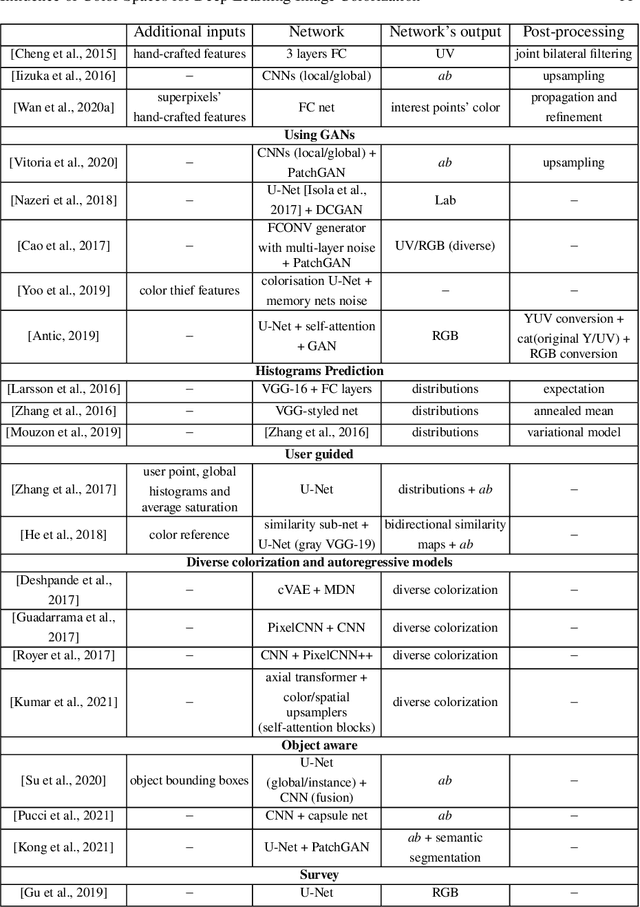
Colorization is a process that converts a grayscale image into a color one that looks as natural as possible. Over the years this task has received a lot of attention. Existing colorization methods rely on different color spaces: RGB, YUV, Lab, etc. In this chapter, we aim to study their influence on the results obtained by training a deep neural network, to answer the question: "Is it crucial to correctly choose the right color space in deep-learning based colorization?". First, we briefly summarize the literature and, in particular, deep learning-based methods. We then compare the results obtained with the same deep neural network architecture with RGB, YUV and Lab color spaces. Qualitative and quantitative analysis do not conclude similarly on which color space is better. We then show the importance of carefully designing the architecture and evaluation protocols depending on the types of images that are being processed and their specificities: strong/small contours, few/many objects, recent/archive images.
Generalized Shortest Path-based Superpixels for Accurate Segmentation of Spherical Images
Apr 15, 2020
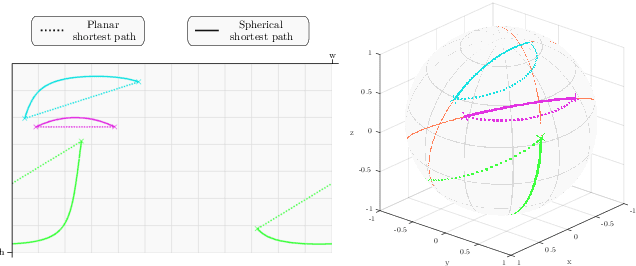

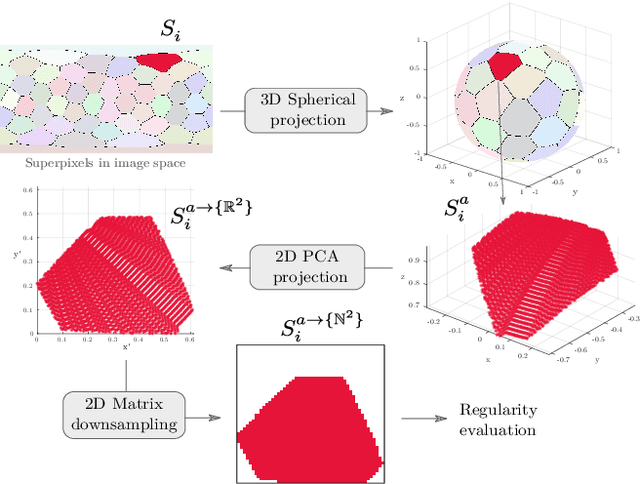
Most of existing superpixel methods are designed to segment standard planar images as pre-processing for computer vision pipelines. Nevertheless, the increasing number of applications based on wide angle capture devices, mainly generating 360{\deg} spherical images, have enforced the need for dedicated superpixel approaches. In this paper, we introduce a new superpixel method for spherical images called SphSPS (for Spherical Shortest Path-based Superpixels). Our approach respects the spherical geometry and generalizes the notion of shortest path between a pixel and a superpixel center on the 3D spherical acquisition space. We show that the feature information on such path can be efficiently integrated into our clustering framework and jointly improves the respect of object contours and the shape regularity. To relevantly evaluate this last aspect in the spherical space, we also generalize a planar global regularity metric. Finally, the proposed SphSPS method obtains significantly better performances than both planar and spherical recent superpixel approaches on the reference 360{\deg} spherical panorama segmentation dataset.