 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Motion Deblurring with Pixel-Wise Kernel Estimation via Kernel Prediction Networks
Aug 05, 2023In recent years, the removal of motion blur in photographs has seen impressive progress in the hands of deep learning-based methods, trained to map directly from blurry to sharp images. For this reason, approaches that explicitly use a forward degradation model received significantly less attention. However, a well-defined specification of the blur genesis, as an intermediate step, promotes the generalization and explainability of the method. Towards this goal, we propose a learning-based motion deblurring method based on dense non-uniform motion blur estimation followed by a non-blind deconvolution approach. Specifically, given a blurry image, a first network estimates the dense per-pixel motion blur kernels using a lightweight representation composed of a set of image-adaptive basis motion kernels and the corresponding mixing coefficients. Then, a second network trained jointly with the first one, unrolls a non-blind deconvolution method using the motion kernel field estimated by the first network. The model-driven aspect is further promoted by training the networks on sharp/blurry pairs synthesized according to a convolution-based, non-uniform motion blur degradation model. Qualitative and quantitative evaluation shows that the kernel prediction network produces accurate motion blur estimates, and that the deblurring pipeline leads to restorations of real blurred images that are competitive or superior to those obtained with existing end-to-end deep learning-based methods. Code and trained models are available at https://github.com/GuillermoCarbajal/J-MKPD/.
Rethinking Motion Deblurring Training: A Segmentation-Based Method for Simulating Non-Uniform Motion Blurred Images
Sep 26, 2022


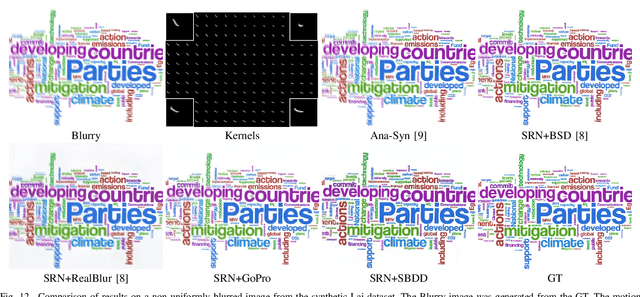
Successful training of end-to-end deep networks for real motion deblurring requires datasets of sharp/blurred image pairs that are realistic and diverse enough to achieve generalization to real blurred images. Obtaining such datasets remains a challenging task. In this paper, we first review the limitations of existing deblurring benchmark datasets from the perspective of generalization to blurry images in the wild. Secondly, we propose an efficient procedural methodology to generate sharp/blurred image pairs, based on a simple yet effective model for the formation of blurred images. This allows generating virtually unlimited realistic and diverse training pairs. We demonstrate the effectiveness of the proposed dataset by training existing deblurring architectures on the simulated pairs and evaluating them across four standard datasets of real blurred images. We observed superior generalization performance for the ultimate task of deblurring real motion-blurred photos of dynamic scenes when training with the proposed method.
Event-based Image Deblurring with Dynamic Motion Awareness
Aug 24, 2022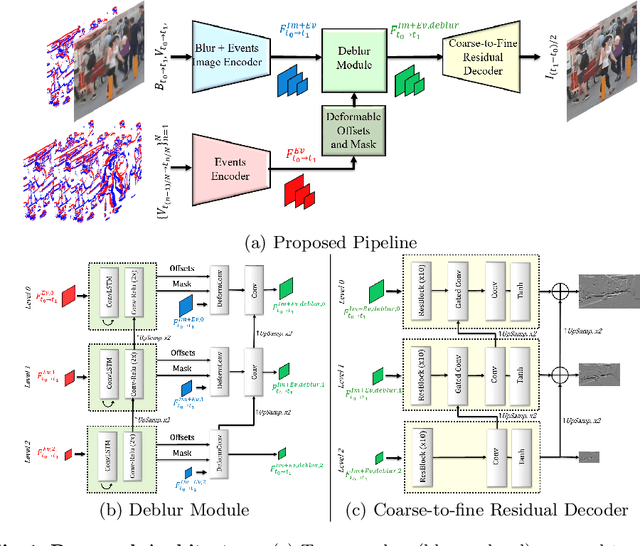

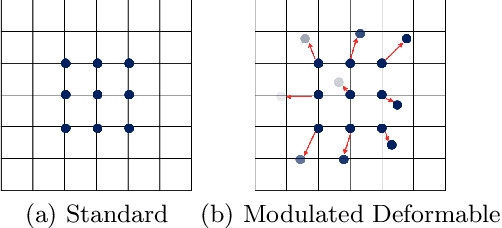

Non-uniform image deblurring is a challenging task due to the lack of temporal and textural information in the blurry image itself. Complementary information from auxiliary sensors such event sensors are being explored to address these limitations. The latter can record changes in a logarithmic intensity asynchronously, called events, with high temporal resolution and high dynamic range. Current event-based deblurring methods combine the blurry image with events to jointly estimate per-pixel motion and the deblur operator. In this paper, we argue that a divide-and-conquer approach is more suitable for this task. To this end, we propose to use modulated deformable convolutions, whose kernel offsets and modulation masks are dynamically estimated from events to encode the motion in the scene, while the deblur operator is learned from the combination of blurry image and corresponding events. Furthermore, we employ a coarse-to-fine multi-scale reconstruction approach to cope with the inherent sparsity of events in low contrast regions. Importantly, we introduce the first dataset containing pairs of real RGB blur images and related events during the exposure time. Our results show better overall robustness when using events, with improvements in PSNR by up to 1.57dB on synthetic data and 1.08 dB on real event data.
An Analysis of Generative Methods for Multiple Image Inpainting
May 04, 2022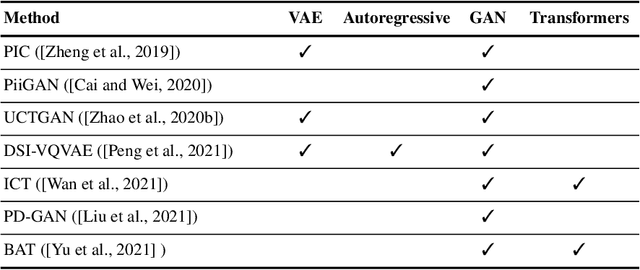
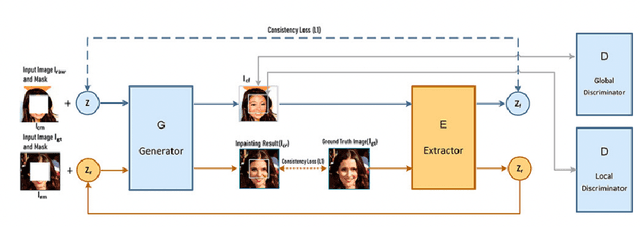
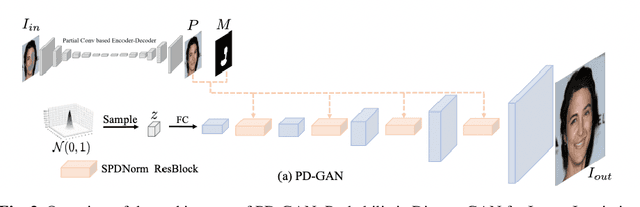
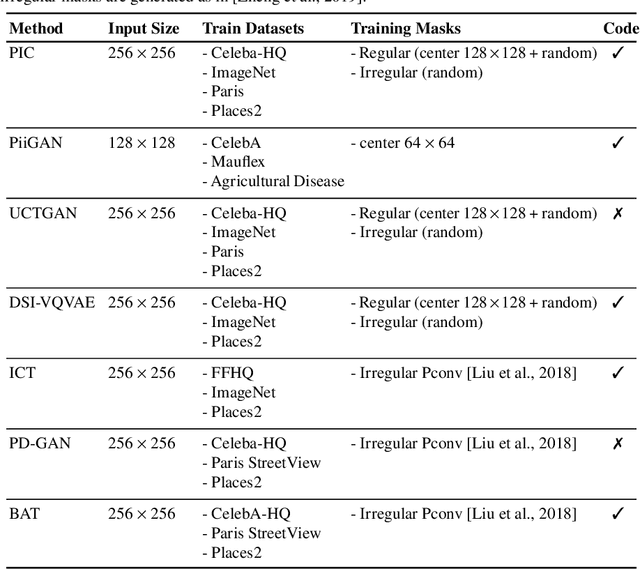
Image inpainting refers to the restoration of an image with missing regions in a way that is not detectable by the observer. The inpainting regions can be of any size and shape. This is an ill-posed inverse problem that does not have a unique solution. In this work, we focus on learning-based image completion methods for multiple and diverse inpainting which goal is to provide a set of distinct solutions for a given damaged image. These methods capitalize on the probabilistic nature of certain generative models to sample various solutions that coherently restore the missing content. Along the chapter, we will analyze the underlying theory and analyze the recent proposals for multiple inpainting. To investigate the pros and cons of each method, we present quantitative and qualitative comparisons, on common datasets, regarding both the quality and the diversity of the set of inpainted solutions. Our analysis allows us to identify the most successful generative strategies in both inpainting quality and inpainting diversity. This task is closely related to the learning of an accurate probability distribution of images. Depending on the dataset in use, the challenges that entail the training of such a model will be discussed through the analysis.
Analysis of Different Losses for Deep Learning Image Colorization
Apr 06, 2022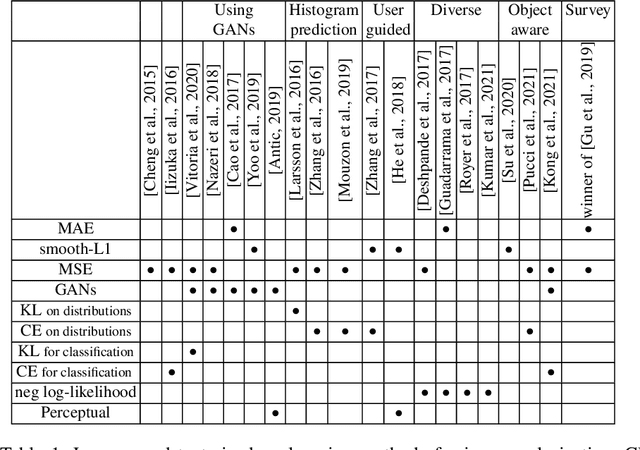
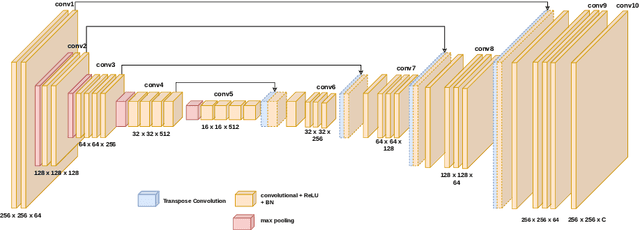
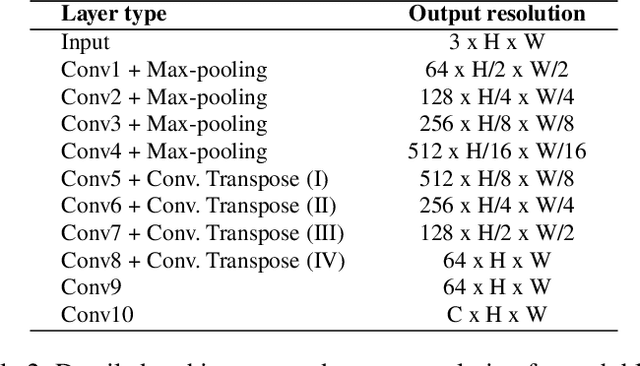

Image colorization aims to add color information to a grayscale image in a realistic way. Recent methods mostly rely on deep learning strategies. While learning to automatically colorize an image, one can define well-suited objective functions related to the desired color output. Some of them are based on a specific type of error between the predicted image and ground truth one, while other losses rely on the comparison of perceptual properties. But, is the choice of the objective function that crucial, i.e., does it play an important role in the results? In this chapter, we aim to answer this question by analyzing the impact of the loss function on the estimated colorization results. To that goal, we review the different losses and evaluation metrics that are used in the literature. We then train a baseline network with several of the reviewed objective functions: classic L1 and L2 losses, as well as more complex combinations such as Wasserstein GAN and VGG-based LPIPS loss. Quantitative results show that the models trained with VGG-based LPIPS provide overall slightly better results for most evaluation metrics. Qualitative results exhibit more vivid colors when with Wasserstein GAN plus the L2 loss or again with the VGG-based LPIPS. Finally, the convenience of quantitative user studies is also discussed to overcome the difficulty of properly assessing on colorized images, notably for the case of old archive photographs where no ground truth is available.
Influence of Color Spaces for Deep Learning Image Colorization
Apr 06, 2022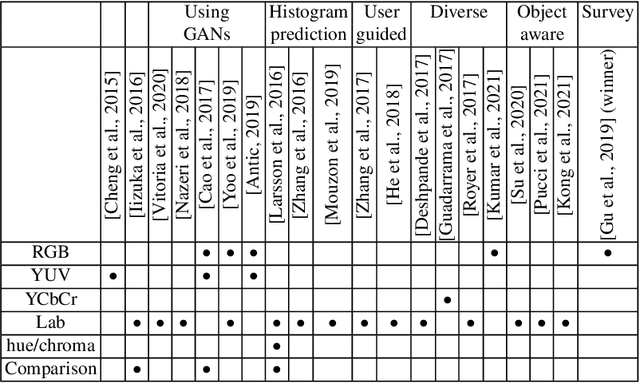

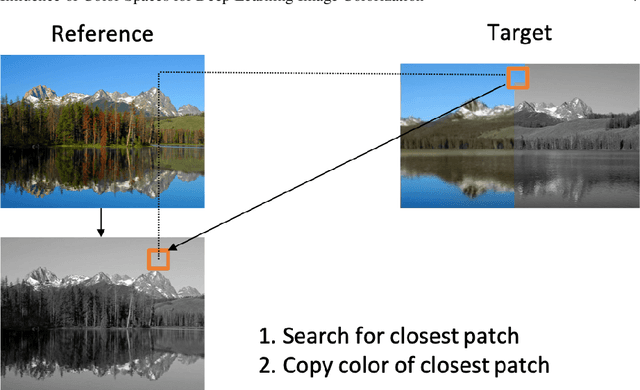
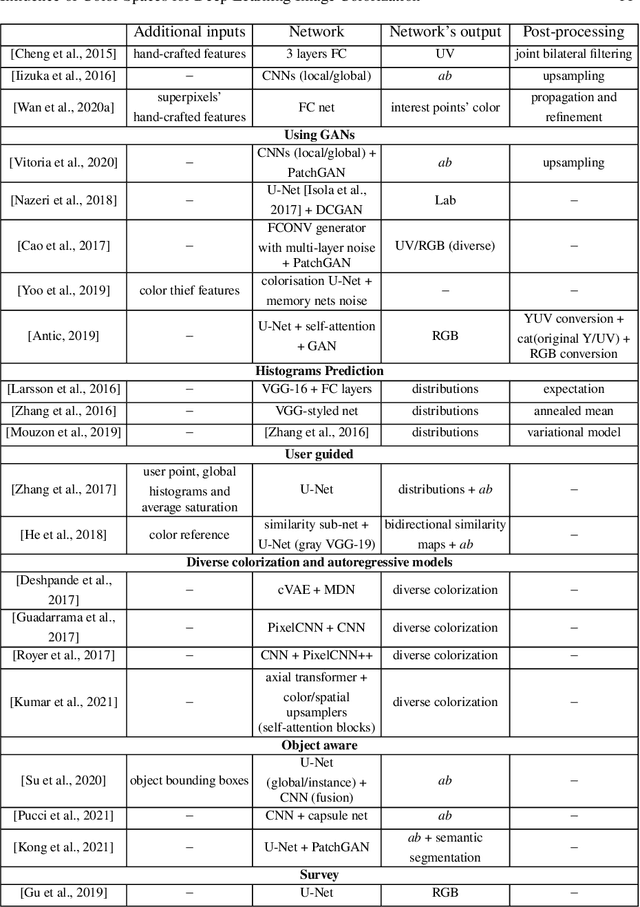
Colorization is a process that converts a grayscale image into a color one that looks as natural as possible. Over the years this task has received a lot of attention. Existing colorization methods rely on different color spaces: RGB, YUV, Lab, etc. In this chapter, we aim to study their influence on the results obtained by training a deep neural network, to answer the question: "Is it crucial to correctly choose the right color space in deep-learning based colorization?". First, we briefly summarize the literature and, in particular, deep learning-based methods. We then compare the results obtained with the same deep neural network architecture with RGB, YUV and Lab color spaces. Qualitative and quantitative analysis do not conclude similarly on which color space is better. We then show the importance of carefully designing the architecture and evaluation protocols depending on the types of images that are being processed and their specificities: strong/small contours, few/many objects, recent/archive images.
Automatic Flare Spot Artifact Detection and Removal in Photographs
Mar 07, 2021


Flare spot is one type of flare artifact caused by a number of conditions, frequently provoked by one or more high-luminance sources within or close to the camera field of view. When light rays coming from a high-luminance source reach the front element of a camera, it can produce intra-reflections within camera elements that emerge at the film plane forming non-image information or flare on the captured image. Even though preventive mechanisms are used, artifacts can appear. In this paper, we propose a robust computational method to automatically detect and remove flare spot artifacts. Our contribution is threefold: firstly, we propose a characterization which is based on intrinsic properties that a flare spot is likely to satisfy; secondly, we define a new confidence measure able to select flare spots among the candidates; and, finally, a method to accurately determine the flare region is given. Then, the detected artifacts are removed by using exemplar-based inpainting. We show that our algorithm achieve top-tier quantitative and qualitative performance.
* Journal of Mathematical Imaging and Vision, 2019
Single Image Non-uniform Blur Kernel Estimation via Adaptive Basis Decomposition
Feb 01, 2021
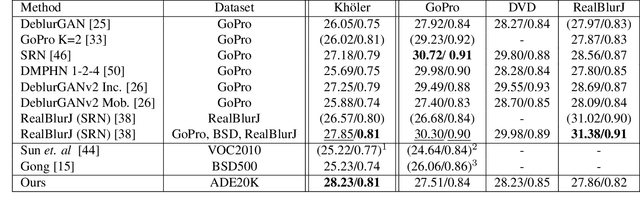

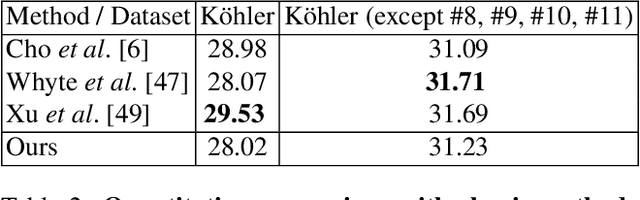
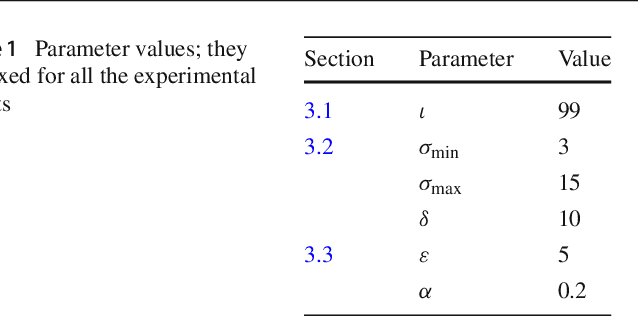
Characterizing and removing motion blur caused by camera shake or object motion remains an important task for image restoration. In recent years, removal of motion blur in photographs has seen impressive progress in the hands of deep learning-based methods, trained to map directly from blurry to sharp images. Characterization of motion blur, on the other hand, has received less attention and progress in model-based methods for restoration lags behind that of data-driven end-to-end approaches. In this paper, we propose a general, non-parametric model for dense non-uniform motion blur estimation. Given a blurry image, we estimate a set of adaptive basis kernels as well as the mixing coefficients at pixel level, producing a per-pixel map of motion blur. This rich but efficient forward model of the degradation process allows the utilization of existing tools for solving inverse problems. We show that our method overcomes the limitations of existing non-uniform motion blur estimation and that it contributes to bridging the gap between model-based and data-driven approaches for deblurring real photographs.
ChromaGAN: An Adversarial Approach for Picture Colorization
Jul 23, 2019
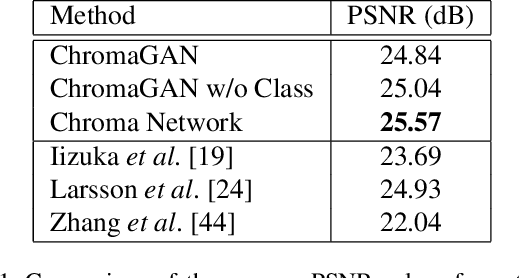


The colorization of grayscale images is an ill-posed problem, with multiple correct solutions. In this paper, an adversarial learning approach is proposed. A generator network is used to infer the chromaticity of a given grayscale image. The same network also performs a semantic classification of the image. This network is framed in an adversarial model that learns to colorize by incorporating perceptual and semantic understanding of color and class distributions. The model is trained via a fully self-supervised strategy. Qualitative and quantitative results show the capacity of the proposed method to colorize images in a realistic way, achieving top-tier performances relative to the state-of-the-art.
Semantic Image Inpainting Through Improved Wasserstein Generative Adversarial Networks
Dec 03, 2018
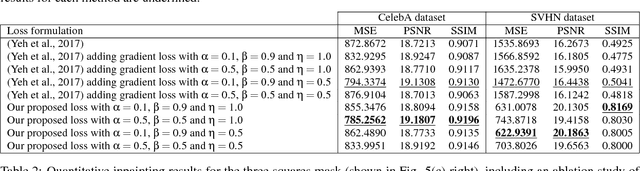

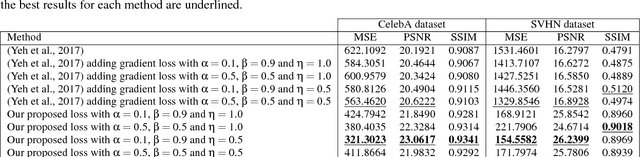
Image inpainting is the task of filling-in missing regions of a damaged or incomplete image. In this work we tackle this problem not only by using the available visual data but also by incorporating image semantics through the use of generative models. Our contribution is twofold: First, we learn a data latent space by training an improved version of the Wasserstein generative adversarial network, for which we incorporate a new generator and discriminator architecture. Second, the learned semantic information is combined with a new optimization loss for inpainting whose minimization infers the missing content conditioned by the available data. It takes into account powerful contextual and perceptual content inherent in the image itself. The benefits include the ability to recover large regions by accumulating semantic information even it is not fully present in the damaged image. Experiments show that the presented method obtains qualitative and quantitative top-tier results in different experimental situations and also achieves accurate photo-realism comparable to state-of-the-art works.