 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut of the Room: Generalizing Event-Based Dynamic Motion Segmentation for Complex Scenes
Mar 07, 2024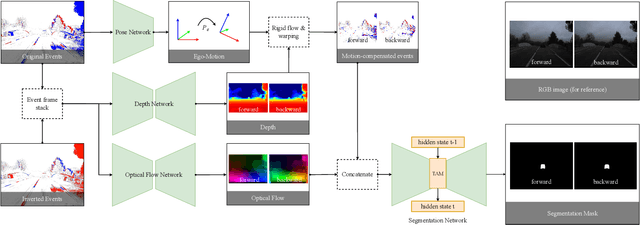
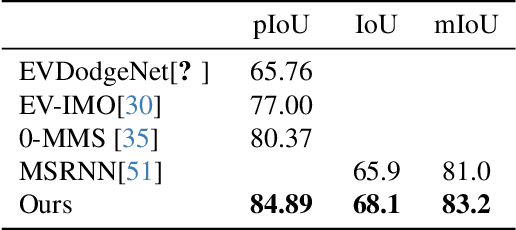
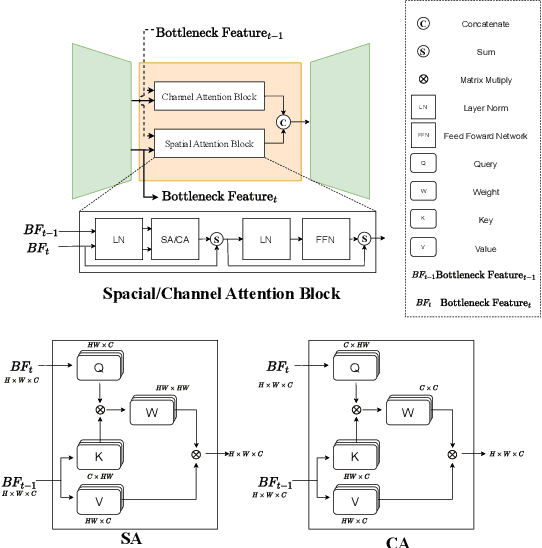
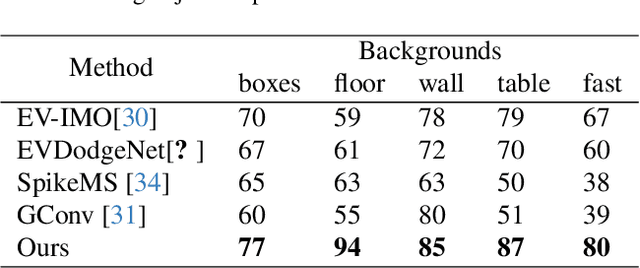
Rapid and reliable identification of dynamic scene parts, also known as motion segmentation, is a key challenge for mobile sensors. Contemporary RGB camera-based methods rely on modeling camera and scene properties however, are often under-constrained and fall short in unknown categories. Event cameras have the potential to overcome these limitations, but corresponding methods have only been demonstrated in smaller-scale indoor environments with simplified dynamic objects. This work presents an event-based method for class-agnostic motion segmentation that can successfully be deployed across complex large-scale outdoor environments too. To this end, we introduce a novel divide-and-conquer pipeline that combines: (a) ego-motion compensated events, computed via a scene understanding module that predicts monocular depth and camera pose as auxiliary tasks, and (b) optical flow from a dedicated optical flow module. These intermediate representations are then fed into a segmentation module that predicts motion segmentation masks. A novel transformer-based temporal attention module in the segmentation module builds correlations across adjacent 'frames' to get temporally consistent segmentation masks. Our method sets the new state-of-the-art on the classic EV-IMO benchmark (indoors), where we achieve improvements of 2.19 moving object IoU (2.22 mIoU) and 4.52 point IoU respectively, as well as on a newly-generated motion segmentation and tracking benchmark (outdoors) based on the DSEC event dataset, termed DSEC-MOTS, where we show improvement of 12.91 moving object IoU.
U-BEV: Height-aware Bird's-Eye-View Segmentation and Neural Map-based Relocalization
Oct 20, 2023



Efficient relocalization is essential for intelligent vehicles when GPS reception is insufficient or sensor-based localization fails. Recent advances in Bird's-Eye-View (BEV) segmentation allow for accurate estimation of local scene appearance and in turn, can benefit the relocalization of the vehicle. However, one downside of BEV methods is the heavy computation required to leverage the geometric constraints. This paper presents U-BEV, a U-Net inspired architecture that extends the current state-of-the-art by allowing the BEV to reason about the scene on multiple height layers before flattening the BEV features. We show that this extension boosts the performance of the U-BEV by up to 4.11 IoU. Additionally, we combine the encoded neural BEV with a differentiable template matcher to perform relocalization on neural SD-map data. The model is fully end-to-end trainable and outperforms transformer-based BEV methods of similar computational complexity by 1.7 to 2.8 mIoU and BEV-based relocalization by over 26% Recall Accuracy on the nuScenes dataset.
Event-based Image Deblurring with Dynamic Motion Awareness
Aug 24, 2022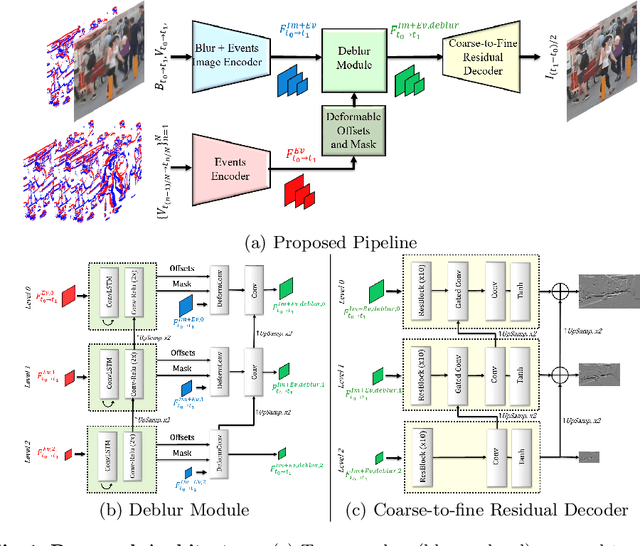

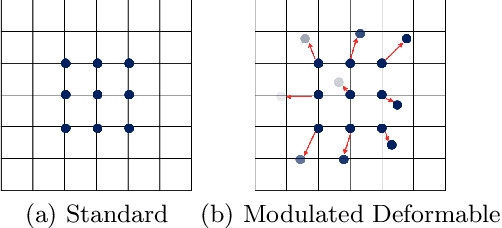

Non-uniform image deblurring is a challenging task due to the lack of temporal and textural information in the blurry image itself. Complementary information from auxiliary sensors such event sensors are being explored to address these limitations. The latter can record changes in a logarithmic intensity asynchronously, called events, with high temporal resolution and high dynamic range. Current event-based deblurring methods combine the blurry image with events to jointly estimate per-pixel motion and the deblur operator. In this paper, we argue that a divide-and-conquer approach is more suitable for this task. To this end, we propose to use modulated deformable convolutions, whose kernel offsets and modulation masks are dynamically estimated from events to encode the motion in the scene, while the deblur operator is learned from the combination of blurry image and corresponding events. Furthermore, we employ a coarse-to-fine multi-scale reconstruction approach to cope with the inherent sparsity of events in low contrast regions. Importantly, we introduce the first dataset containing pairs of real RGB blur images and related events during the exposure time. Our results show better overall robustness when using events, with improvements in PSNR by up to 1.57dB on synthetic data and 1.08 dB on real event data.
Time Lens++: Event-based Frame Interpolation with Parametric Non-linear Flow and Multi-scale Fusion
Mar 31, 2022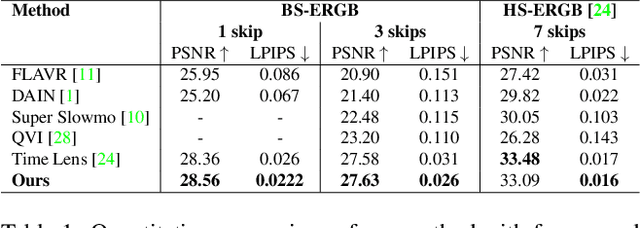
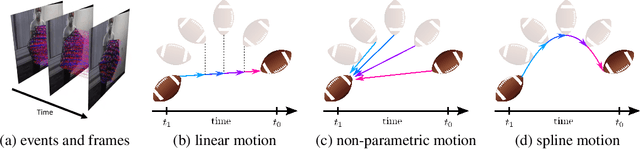
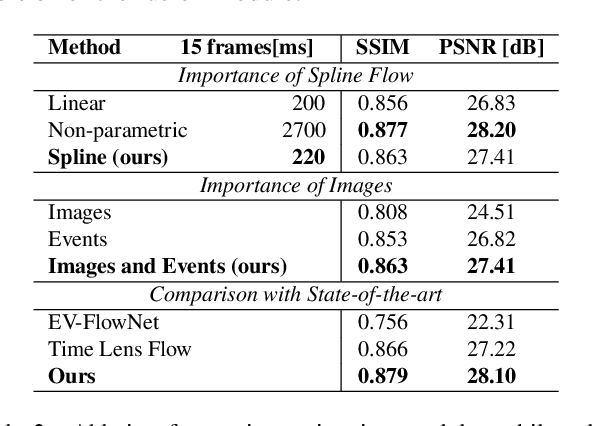
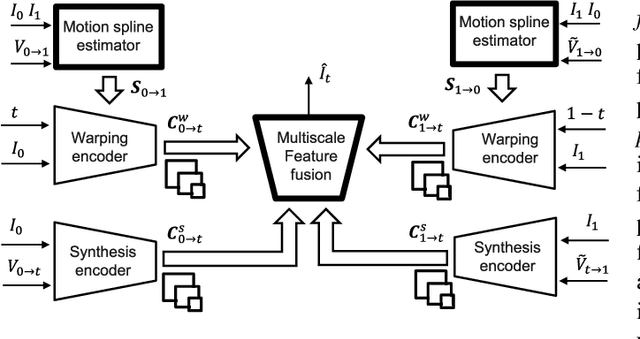
Recently, video frame interpolation using a combination of frame- and event-based cameras has surpassed traditional image-based methods both in terms of performance and memory efficiency. However, current methods still suffer from (i) brittle image-level fusion of complementary interpolation results, that fails in the presence of artifacts in the fused image, (ii) potentially temporally inconsistent and inefficient motion estimation procedures, that run for every inserted frame and (iii) low contrast regions that do not trigger events, and thus cause events-only motion estimation to generate artifacts. Moreover, previous methods were only tested on datasets consisting of planar and faraway scenes, which do not capture the full complexity of the real world. In this work, we address the above problems by introducing multi-scale feature-level fusion and computing one-shot non-linear inter-frame motion from events and images, which can be efficiently sampled for image warping. We also collect the first large-scale events and frames dataset consisting of more than 100 challenging scenes with depth variations, captured with a new experimental setup based on a beamsplitter. We show that our method improves the reconstruction quality by up to 0.2 dB in terms of PSNR and up to 15% in LPIPS score.
Multi-Bracket High Dynamic Range Imaging with Event Cameras
Mar 13, 2022



Modern high dynamic range (HDR) imaging pipelines align and fuse multiple low dynamic range (LDR) images captured at different exposure times. While these methods work well in static scenes, dynamic scenes remain a challenge since the LDR images still suffer from saturation and noise. In such scenarios, event cameras would be a valid complement, thanks to their higher temporal resolution and dynamic range. In this paper, we propose the first multi-bracket HDR pipeline combining a standard camera with an event camera. Our results show better overall robustness when using events, with improvements in PSNR by up to 5dB on synthetic data and up to 0.7dB on real-world data. We also introduce a new dataset containing bracketed LDR images with aligned events and HDR ground truth.