 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHROMA: Detecting AI-Generated Images through Inter-Channel Color-Space Correlations
Jun 07, 2026The rapid adoption of diffusion and large-scale generative models has made it increasingly challenging to distinguish synthetic imagery from real photographs. While automated detectors have been proposed, their generalization to unseen generators remains brittle. To address this limitation, we investigate inter-channel color correlations, a lightweight and underexploited forensic cue. We first demonstrate that LPIPS, a widely used perceptual metric, exhibits inconsistent responses to perturbations that selectively alter channel dependence across different color-space parameterizations, indicating that cross-channel statistics are not uniformly constrained by common perceptual training objectives. Motivated by this, we analyze the distributions of pairwise inter-channel correlation features across multiple color spaces. Our analysis reveals systematic, generator-specific differences in these distributions, with RGB and Lab color spaces providing the most apparent separation between real and generated images. Building on this, we introduce Chroma, a detector of AI-generated images which augments standard RGB inputs with inter-channel correlation maps and employs a fixed CNN backbone trained with a modest computational budget. We assess its robustness under both single-generator training and a limited multi-generator supervision regime, where only a few samples from additional generators are available. Across a standard benchmark protocol, correlation-augmented inputs improve real-vs-generated discrimination and robustness, yielding performance competitive with recent detectors while maintaining a simple architecture and training procedure. Code is available at https://github.com/JPSoteloSilva/CHROMA
SPHERE-JEPA: Spherical Prediction with Homogeneous Embeddings
May 26, 2026A fundamental open question in self-supervised learning (SSL) is the explicit characterization of the optimal geometry of the learned representations. Recently, LeJEPA identified isotropic Gaussian embeddings as optimal for minimizing downstream prediction risk in Euclidean spaces. However, the corresponding problem for distributions supported on lower-dimensional manifolds, such as the hypersphere, remains unexplored. In this work, we demonstrate that extending this minimax analysis to smooth distributions on Riemannian manifolds fundamentally changes the optimal solution. We show that, under a worst-case formulation, both k-nearest neighbors and kernel ridge regression induce hyperspherical uniformity. More precisely, we show that uniform distributions on manifolds are optimal for k-nearest neighbors, and that the uniform distribution on the sphere is optimal for kernel ridge regression with both the exponential dot-product kernel and the linear kernel. This theoretical insight reveals a fundamental limitation of Gaussian embeddings: their non-uniform density induces anisotropic k-NN neighborhoods, severely biasing the estimator. To correct this, we introduce SPHERE-JEPA, a theoretically grounded SSL framework. We adapt LeJEPA's Cram{é}r-Wold projection mechanism to enforce hyperspherical uniformity rather than a Gaussian prior. Empirically, SPHERE-JEPA yields significant improvements, boosting texture retrieval mAP by over 6%, while consistently matching or outperforming LeJEPA on standard benchmarks-including a +1.8% linear probing gain on ImageNet-1K (ViT-B/14).
Deep S2P: Integrating Learning Based Stereo Matching Into the Satellite Stereo Pipeline
Mar 23, 2026Digital Surface Model generation from satellite imagery is a core task in Earth observation and is commonly addressed using classical stereoscopic matching algorithms in satellite pipelines as in the Satellite Stereo Pipeline (S2P). While recent learning-based stereo matchers achieve state-of-the-art performance on standard benchmarks, their integration into operational satellite pipelines remains challenging due to differences in viewing geometry and disparity assumptions. In this work, we integrate several modern learning-based stereo matchers, including StereoAnywhere, MonSter, Foundation Stereo, and a satellite fine-tuned variant of MonSter, into the Satellite Stereo Pipeline, adapting the rectification stage to enforce compatible disparity polarity and range. We release the corresponding code to enable reproducible use of these methods in large-scale Earth observation workflows. Experiments on satellite imagery show consistent improvements over classical cost-volume-based approaches in terms of Digital Surface Model accuracy, although commonly used metrics such as mean absolute error exhibit saturation effects. Qualitative results reveal substantially improved geometric detail and sharper structures, highlighting the need for evaluation strategies that better reflect perceptual and structural fidelity. At the same time, performance over challenging surface types such as vegetation remains limited across all evaluated models, indicating open challenges for learning-based stereo in natural environments.
Diachronic Stereo Matching for Multi-Date Satellite Imagery
Jan 30, 2026Recent advances in image-based satellite 3D reconstruction have progressed along two complementary directions. On one hand, multi-date approaches using NeRF or Gaussian-splatting jointly model appearance and geometry across many acquisitions, achieving accurate reconstructions on opportunistic imagery with numerous observations. On the other hand, classical stereoscopic reconstruction pipelines deliver robust and scalable results for simultaneous or quasi-simultaneous image pairs. However, when the two images are captured months apart, strong seasonal, illumination, and shadow changes violate standard stereoscopic assumptions, causing existing pipelines to fail. This work presents the first Diachronic Stereo Matching method for satellite imagery, enabling reliable 3D reconstruction from temporally distant pairs. Two advances make this possible: (1) fine-tuning a state-of-the-art deep stereo network that leverages monocular depth priors, and (2) exposing it to a dataset specifically curated to include a diverse set of diachronic image pairs. In particular, we start from a pretrained MonSter model, trained initially on a mix of synthetic and real datasets such as SceneFlow and KITTI, and fine-tune it on a set of stereo pairs derived from the DFC2019 remote sensing challenge. This dataset contains both synchronic and diachronic pairs under diverse seasonal and illumination conditions. Experiments on multi-date WorldView-3 imagery demonstrate that our approach consistently surpasses classical pipelines and unadapted deep stereo models on both synchronic and diachronic settings. Fine-tuning on temporally diverse images, together with monocular priors, proves essential for enabling 3D reconstruction from previously incompatible acquisition dates. Left image (winter) Right image (autumn) DSM geometry Ours (1.23 m) Zero-shot (3.99 m) LiDAR GT Figure 1. Output geometry for a winter-autumn image pair from Omaha (OMA 331 test scene). Our method recovers accurate geometry despite the diachronic nature of the pair, exhibiting strong appearance changes, which cause existing zero-shot methods to fail. Missing values due to perspective shown in black. Mean altitude error in parentheses; lower is better.
Blur2seq: Blind Deblurring and Camera Trajectory Estimation from a Single Camera Motion-blurred Image
Oct 23, 2025Motion blur caused by camera shake, particularly under large or rotational movements, remains a major challenge in image restoration. We propose a deep learning framework that jointly estimates the latent sharp image and the underlying camera motion trajectory from a single blurry image. Our method leverages the Projective Motion Blur Model (PMBM), implemented efficiently using a differentiable blur creation module compatible with modern networks. A neural network predicts a full 3D rotation trajectory, which guides a model-based restoration network trained end-to-end. This modular architecture provides interpretability by revealing the camera motion that produced the blur. Moreover, this trajectory enables the reconstruction of the sequence of sharp images that generated the observed blurry image. To further refine results, we optimize the trajectory post-inference via a reblur loss, improving consistency between the blurry input and the restored output. Extensive experiments show that our method achieves state-of-the-art performance on both synthetic and real datasets, particularly in cases with severe or spatially variant blur, where end-to-end deblurring networks struggle. Code and trained models are available at https://github.com/GuillermoCarbajal/Blur2Seq/
Graph Contrastive Learning for Connectome Classification
Feb 07, 2025With recent advancements in non-invasive techniques for measuring brain activity, such as magnetic resonance imaging (MRI), the study of structural and functional brain networks through graph signal processing (GSP) has gained notable prominence. GSP stands as a key tool in unraveling the interplay between the brain's function and structure, enabling the analysis of graphs defined by the connections between regions of interest -- referred to as connectomes in this context. Our work represents a further step in this direction by exploring supervised contrastive learning methods within the realm of graph representation learning. The main objective of this approach is to generate subject-level (i.e., graph-level) vector representations that bring together subjects sharing the same label while separating those with different labels. These connectome embeddings are derived from a graph neural network Encoder-Decoder architecture, which jointly considers structural and functional connectivity. By leveraging data augmentation techniques, the proposed framework achieves state-of-the-art performance in a gender classification task using Human Connectome Project data. More broadly, our connectome-centric methodological advances support the promising prospect of using GSP to discover more about brain function, with potential impact to understanding heterogeneity in the neurodegeneration for precision medicine and diagnosis.
PhotoHolmes: a Python library for forgery detection in digital images
Dec 19, 2024In this paper, we introduce PhotoHolmes, an open-source Python library designed to easily run and benchmark forgery detection methods on digital images. The library includes implementations of popular and state-of-the-art methods, dataset integration tools, and evaluation metrics. Utilizing the Benchmark tool in PhotoHolmes, users can effortlessly compare various methods. This facilitates an accurate and reproducible comparison between their own methods and those in the existing literature. Furthermore, PhotoHolmes includes a command-line interface (CLI) to easily run the methods implemented in the library on any suspicious image. As such, image forgery methods become more accessible to the community. The library has been built with extensibility and modularity in mind, which makes adding new methods, datasets and metrics to the library a straightforward process. The source code is available at https://github.com/photoholmes/photoholmes.
Deep-TEMPEST: Using Deep Learning to Eavesdrop on HDMI from its Unintended Electromagnetic Emanations
Jul 12, 2024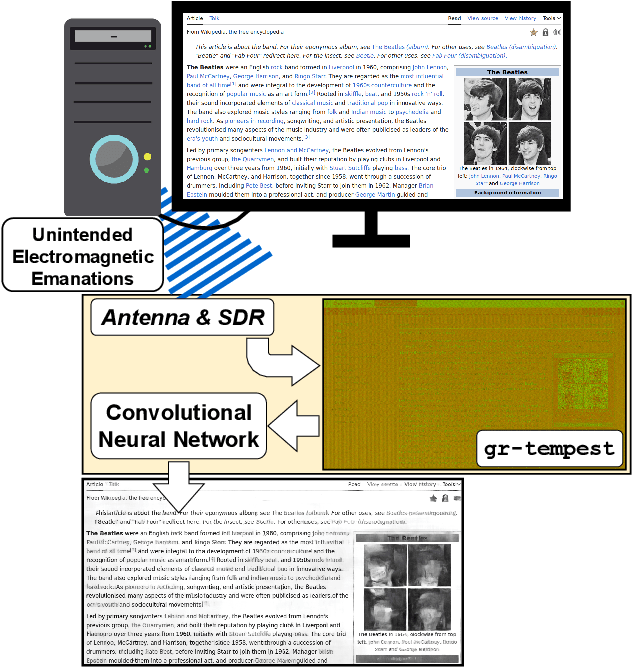
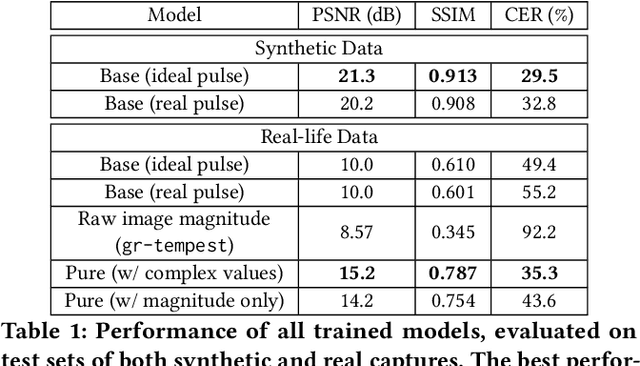
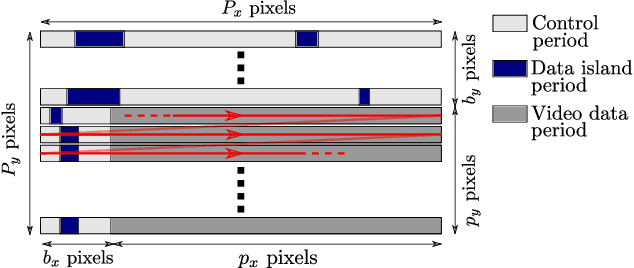
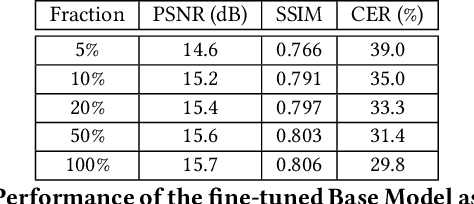
In this work, we address the problem of eavesdropping on digital video displays by analyzing the electromagnetic waves that unintentionally emanate from the cables and connectors, particularly HDMI. This problem is known as TEMPEST. Compared to the analog case (VGA), the digital case is harder due to a 10-bit encoding that results in a much larger bandwidth and non-linear mapping between the observed signal and the pixel's intensity. As a result, eavesdropping systems designed for the analog case obtain unclear and difficult-to-read images when applied to digital video. The proposed solution is to recast the problem as an inverse problem and train a deep learning module to map the observed electromagnetic signal back to the displayed image. However, this approach still requires a detailed mathematical analysis of the signal, firstly to determine the frequency at which to tune but also to produce training samples without actually needing a real TEMPEST setup. This saves time and avoids the need to obtain these samples, especially if several configurations are being considered. Our focus is on improving the average Character Error Rate in text, and our system improves this rate by over 60 percentage points compared to previous available implementations. The proposed system is based on widely available Software Defined Radio and is fully open-source, seamlessly integrated into the popular GNU Radio framework. We also share the dataset we generated for training, which comprises both simulated and over 1000 real captures. Finally, we discuss some countermeasures to minimize the potential risk of being eavesdropped by systems designed based on similar principles.
Diffusion models meet image counter-forensics
Nov 22, 2023

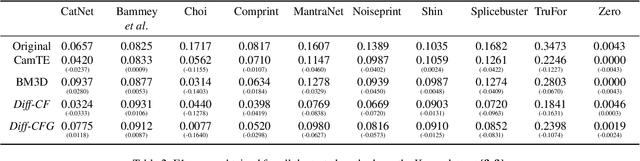

From its acquisition in the camera sensors to its storage, different operations are performed to generate the final image. This pipeline imprints specific traces into the image to form a natural watermark. Tampering with an image disturbs these traces; these disruptions are clues that are used by most methods to detect and locate forgeries. In this article, we assess the capabilities of diffusion models to erase the traces left by forgers and, therefore, deceive forensics methods. Such an approach has been recently introduced for adversarial purification, achieving significant performance. We show that diffusion purification methods are well suited for counter-forensics tasks. Such approaches outperform already existing counter-forensics techniques both in deceiving forensics methods and in preserving the natural look of the purified images. The source code is publicly available at https://github.com/mtailanian/diff-cf.
Blind Motion Deblurring with Pixel-Wise Kernel Estimation via Kernel Prediction Networks
Aug 05, 2023In recent years, the removal of motion blur in photographs has seen impressive progress in the hands of deep learning-based methods, trained to map directly from blurry to sharp images. For this reason, approaches that explicitly use a forward degradation model received significantly less attention. However, a well-defined specification of the blur genesis, as an intermediate step, promotes the generalization and explainability of the method. Towards this goal, we propose a learning-based motion deblurring method based on dense non-uniform motion blur estimation followed by a non-blind deconvolution approach. Specifically, given a blurry image, a first network estimates the dense per-pixel motion blur kernels using a lightweight representation composed of a set of image-adaptive basis motion kernels and the corresponding mixing coefficients. Then, a second network trained jointly with the first one, unrolls a non-blind deconvolution method using the motion kernel field estimated by the first network. The model-driven aspect is further promoted by training the networks on sharp/blurry pairs synthesized according to a convolution-based, non-uniform motion blur degradation model. Qualitative and quantitative evaluation shows that the kernel prediction network produces accurate motion blur estimates, and that the deblurring pipeline leads to restorations of real blurred images that are competitive or superior to those obtained with existing end-to-end deep learning-based methods. Code and trained models are available at https://github.com/GuillermoCarbajal/J-MKPD/.