 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcomitant DAG Learning: On the Roles of Noise Adaptivity, Sparsity, and Non-negativity
May 22, 2026Directed acyclic graphs (DAGs) constitute a central modeling tool to enable principled reasoning about cause-effect interactions in complex systems. However, since the causal structure underlying a group of variables is often unknown and interventions may be infeasible or ethically challenging to implement, there is a need to address the task of inferring DAGs from observational data. However, most classical structure identification approaches face two key obstacles: the combinatorial challenge of enforcing acyclicity, which severely limits scalability, and identifiability challenges arising from latent confounding or heterogeneous noise. This tutorial offers an overview of recent signal processing and optimization advances that address these issues by recasting DAG structure learning as a continuous, score-based estimation problem over adjacency matrices. We begin with a didactic introduction to structural equation models and the formulation of causal graph recovery, followed by a historical survey of score-based methods ranging from early combinatorial search schemes and greedy heuristics to modern continuous frameworks that leverage smooth characterizations of acyclicity. Building on this foundation, we describe concomitant DAG estimation methods that jointly infer sparse causal structure and exogenous noise levels, improving robustness under heteroscedasticity and distribution shifts by rendering the estimator noise adaptive. All in all, the tutorial introduces readers to challenges and opportunities for signal processing research at the crossroads of causal inference, high-dimensional statistics, and scalable graph learning, while outlining emerging directions including online, nonlinear, and neural causal discovery.
Exploiting Non-Negativity in DAG Structure Learning
May 19, 2026This work addresses the problem of learning directed acyclic graphs (DAGs) from nodal observations generated by a linear structural equation model. DAG learning is a central task in signal processing, machine learning, and causal inference, but it remains challenging because acyclicity is a global combinatorial property. Continuous acyclicity constraints have led to important algorithmic advances by replacing the discrete DAG constraint with smooth equality constraints. However, existing formulations still involve difficult non-convex optimization landscapes and may suffer from degenerate first-order optimality conditions. Here, we restrict attention to DAGs with non-negative edge weights and exploit this additional structure to obtain a simpler characterization of acyclicity. Building on this characterization, we formulate a regularized non-negative DAG learning problem and develop an algorithm based on the method of multipliers. We further analyze the benign optimization landscape induced by non-negativity. In the population regime, we show that the true DAG is the unique global minimizer of the proposed augmented-Lagrangian formulation; moreover, the landscape contains no spurious interior stationary points, and the true DAG is the only acyclic KKT point. Numerical experiments on synthetic and real-world data show that the proposed method improves over state-of-the-art continuous DAG-learning alternatives.
Task-driven Heterophilic Graph Structure Learning
Dec 29, 2025Graph neural networks (GNNs) often struggle to learn discriminative node representations for heterophilic graphs, where connected nodes tend to have dissimilar labels and feature similarity provides weak structural cues. We propose frequency-guided graph structure learning (FgGSL), an end-to-end graph inference framework that jointly learns homophilic and heterophilic graph structures along with a spectral encoder. FgGSL employs a learnable, symmetric, feature-driven masking function to infer said complementary graphs, which are processed using pre-designed low- and high-pass graph filter banks. A label-based structural loss explicitly promotes the recovery of homophilic and heterophilic edges, enabling task-driven graph structure learning. We derive stability bounds for the structural loss and establish robustness guarantees for the filter banks under graph perturbations. Experiments on six heterophilic benchmarks demonstrate that FgGSL consistently outperforms state-of-the-art GNNs and graph rewiring methods, highlighting the benefits of combining frequency information with supervised topology inference.
Dirichlet Meets Horvitz and Thompson: Estimating Homophily in Large Networks via Sampling
Dec 18, 2025

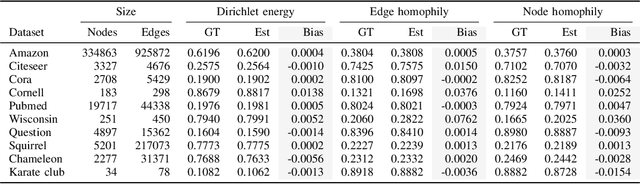
Assessing homophily in large-scale networks is central to understanding structural regularities in graphs, and thus inform the choice of models (such as graph neural networks) adopted to learn from network data. Evaluation of smoothness metrics requires access to the entire network topology and node features, which may be impractical in several large-scale, dynamic, resource-limited, or privacy-constrained settings. In this work, we propose a sampling-based framework to estimate homophily via the Dirichlet energy (Laplacian-based total variation) of graph signals, leveraging the Horvitz-Thompson (HT) estimator for unbiased inference from partial graph observations. The Dirichlet energy is a so-termed total (of squared nodal feature deviations) over graph edges; hence, estimable under general network sampling designs for which edge-inclusion probabilities can be analytically derived and used as weights in the proposed HT estimator. We establish that the Dirichlet energy can be consistently estimated from sampled graphs, and empirically study other heterophily measures as well. Experiments on several heterophilic benchmark datasets demonstrate the effectiveness of the proposed HT estimators in reliably capturing homophilic structure (or lack thereof) from sampled network measurements.
BUILD with Precision: Bottom-Up Inference of Linear DAGs
Dec 18, 2025Learning the structure of directed acyclic graphs (DAGs) from observational data is a central problem in causal discovery, statistical signal processing, and machine learning. Under a linear Gaussian structural equation model (SEM) with equal noise variances, the problem is identifiable and we show that the ensemble precision matrix of the observations exhibits a distinctive structure that facilitates DAG recovery. Exploiting this property, we propose BUILD (Bottom-Up Inference of Linear DAGs), a deterministic stepwise algorithm that identifies leaf nodes and their parents, then prunes the leaves by removing incident edges to proceed to the next step, exactly reconstructing the DAG from the true precision matrix. In practice, precision matrices must be estimated from finite data, and ill-conditioning may lead to error accumulation across BUILD steps. As a mitigation strategy, we periodically re-estimate the precision matrix (with less variables as leaves are pruned), trading off runtime for enhanced robustness. Reproducible results on challenging synthetic benchmarks demonstrate that BUILD compares favorably to state-of-the-art DAG learning algorithms, while offering an explicit handle on complexity.
Topology Identification and Inference over Graphs
Dec 11, 2025
Topology identification and inference of processes evolving over graphs arise in timely applications involving brain, transportation, financial, power, as well as social and information networks. This chapter provides an overview of graph topology identification and statistical inference methods for multidimensional relational data. Approaches for undirected links connecting graph nodes are outlined, going all the way from correlation metrics to covariance selection, and revealing ties with smooth signal priors. To account for directional (possibly causal) relations among nodal variables and address the limitations of linear time-invariant models in handling dynamic as well as nonlinear dependencies, a principled framework is surveyed to capture these complexities through judiciously selected kernels from a prescribed dictionary. Generalizations are also described via structural equations and vector autoregressions that can exploit attributes such as low rank, sparsity, acyclicity, and smoothness to model dynamic processes over possibly time-evolving topologies. It is argued that this approach supports both batch and online learning algorithms with convergence rate guarantees, is amenable to tensor (that is, multi-way array) formulations as well as decompositions that are well-suited for multidimensional network data, and can seamlessly leverage high-order statistical information.
Non-negative DAG Learning from Time-Series Data
Dec 08, 2025This work aims to learn the directed acyclic graph (DAG) that captures the instantaneous dependencies underlying a multivariate time series. The observed data follow a linear structural vector autoregressive model (SVARM) with both instantaneous and time-lagged dependencies, where the instantaneous structure is modeled by a DAG to reflect potential causal relationships. While recent continuous relaxation approaches impose acyclicity through smooth constraint functions involving powers of the adjacency matrix, they lead to non-convex optimization problems that are challenging to solve. In contrast, we assume that the underlying DAG has only non-negative edge weights, and leverage this additional structure to impose acyclicity via a convex constraint. This enables us to cast the problem of non-negative DAG recovery from multivariate time-series data as a convex optimization problem in abstract form, which we solve using the method of multipliers. Crucially, the convex formulation guarantees global optimality of the solution. Finally, we assess the performance of the proposed method on synthetic time-series data, where it outperforms existing alternatives.
Disentangling Neurodegeneration with Brain Age Gap Prediction Models: A Graph Signal Processing Perspective
Oct 14, 2025Neurodegeneration, characterized by the progressive loss of neuronal structure or function, is commonly assessed in clinical practice through reductions in cortical thickness or brain volume, as visualized by structural MRI. While informative, these conventional approaches lack the statistical sophistication required to fully capture the spatially correlated and heterogeneous nature of neurodegeneration, which manifests both in healthy aging and in neurological disorders. To address these limitations, brain age gap has emerged as a promising data-driven biomarker of brain health. The brain age gap prediction (BAGP) models estimate the difference between a person's predicted brain age from neuroimaging data and their chronological age. The resulting brain age gap serves as a compact biomarker of brain health, with recent studies demonstrating its predictive utility for disease progression and severity. However, practical adoption of BAGP models is hindered by their methodological obscurities and limited generalizability across diverse clinical populations. This tutorial article provides an overview of BAGP and introduces a principled framework for this application based on recent advancements in graph signal processing (GSP). In particular, we focus on graph neural networks (GNNs) and introduce the coVariance neural network (VNN), which leverages the anatomical covariance matrices derived from structural MRI. VNNs offer strong theoretical grounding and operational interpretability, enabling robust estimation of brain age gap predictions. By integrating perspectives from GSP, machine learning, and network neuroscience, this work clarifies the path forward for reliable and interpretable BAGP models and outlines future research directions in personalized medicine.
Directed Acyclic Graph Convolutional Networks
Jun 13, 2025Directed acyclic graphs (DAGs) are central to science and engineering applications including causal inference, scheduling, and neural architecture search. In this work, we introduce the DAG Convolutional Network (DCN), a novel graph neural network (GNN) architecture designed specifically for convolutional learning from signals supported on DAGs. The DCN leverages causal graph filters to learn nodal representations that account for the partial ordering inherent to DAGs, a strong inductive bias does not present in conventional GNNs. Unlike prior art in machine learning over DAGs, DCN builds on formal convolutional operations that admit spectral-domain representations. We further propose the Parallel DCN (PDCN), a model that feeds input DAG signals to a parallel bank of causal graph-shift operators and processes these DAG-aware features using a shared multilayer perceptron. This way, PDCN decouples model complexity from graph size while maintaining satisfactory predictive performance. The architectures' permutation equivariance and expressive power properties are also established. Comprehensive numerical tests across several tasks, datasets, and experimental conditions demonstrate that (P)DCN compares favorably with state-of-the-art baselines in terms of accuracy, robustness, and computational efficiency. These results position (P)DCN as a viable framework for deep learning from DAG-structured data that is designed from first (graph) signal processing principles.
Unlearning Algorithmic Biases over Graphs
May 20, 2025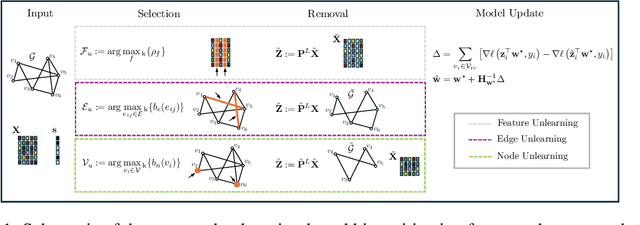
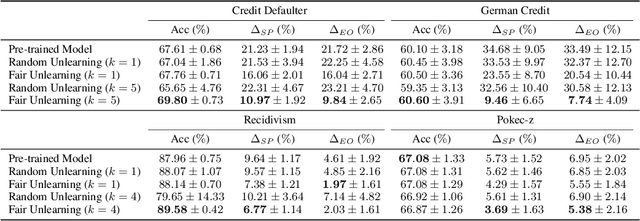
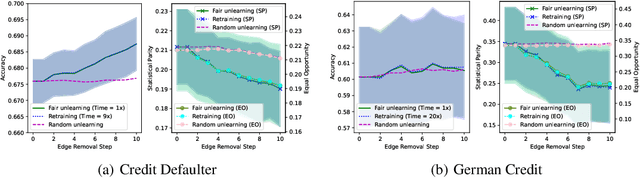

The growing enforcement of the right to be forgotten regulations has propelled recent advances in certified (graph) unlearning strategies to comply with data removal requests from deployed machine learning (ML) models. Motivated by the well-documented bias amplification predicament inherent to graph data, here we take a fresh look at graph unlearning and leverage it as a bias mitigation tool. Given a pre-trained graph ML model, we develop a training-free unlearning procedure that offers certifiable bias mitigation via a single-step Newton update on the model weights. This way, we contribute a computationally lightweight alternative to the prevalent training- and optimization-based fairness enhancement approaches, with quantifiable performance guarantees. We first develop a novel fairness-aware nodal feature unlearning strategy along with refined certified unlearning bounds for this setting, whose impact extends beyond the realm of graph unlearning. We then design structural unlearning methods endowed with principled selection mechanisms over nodes and edges informed by rigorous bias analyses. Unlearning these judiciously selected elements can mitigate algorithmic biases with minimal impact on downstream utility (e.g., node classification accuracy). Experimental results over real networks corroborate the bias mitigation efficacy of our unlearning strategies, and delineate markedly favorable utility-complexity trade-offs relative to retraining from scratch using augmented graph data obtained via removals.