 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcomitant DAG Learning: On the Roles of Noise Adaptivity, Sparsity, and Non-negativity
May 22, 2026Directed acyclic graphs (DAGs) constitute a central modeling tool to enable principled reasoning about cause-effect interactions in complex systems. However, since the causal structure underlying a group of variables is often unknown and interventions may be infeasible or ethically challenging to implement, there is a need to address the task of inferring DAGs from observational data. However, most classical structure identification approaches face two key obstacles: the combinatorial challenge of enforcing acyclicity, which severely limits scalability, and identifiability challenges arising from latent confounding or heterogeneous noise. This tutorial offers an overview of recent signal processing and optimization advances that address these issues by recasting DAG structure learning as a continuous, score-based estimation problem over adjacency matrices. We begin with a didactic introduction to structural equation models and the formulation of causal graph recovery, followed by a historical survey of score-based methods ranging from early combinatorial search schemes and greedy heuristics to modern continuous frameworks that leverage smooth characterizations of acyclicity. Building on this foundation, we describe concomitant DAG estimation methods that jointly infer sparse causal structure and exogenous noise levels, improving robustness under heteroscedasticity and distribution shifts by rendering the estimator noise adaptive. All in all, the tutorial introduces readers to challenges and opportunities for signal processing research at the crossroads of causal inference, high-dimensional statistics, and scalable graph learning, while outlining emerging directions including online, nonlinear, and neural causal discovery.
Exploiting Non-Negativity in DAG Structure Learning
May 19, 2026This work addresses the problem of learning directed acyclic graphs (DAGs) from nodal observations generated by a linear structural equation model. DAG learning is a central task in signal processing, machine learning, and causal inference, but it remains challenging because acyclicity is a global combinatorial property. Continuous acyclicity constraints have led to important algorithmic advances by replacing the discrete DAG constraint with smooth equality constraints. However, existing formulations still involve difficult non-convex optimization landscapes and may suffer from degenerate first-order optimality conditions. Here, we restrict attention to DAGs with non-negative edge weights and exploit this additional structure to obtain a simpler characterization of acyclicity. Building on this characterization, we formulate a regularized non-negative DAG learning problem and develop an algorithm based on the method of multipliers. We further analyze the benign optimization landscape induced by non-negativity. In the population regime, we show that the true DAG is the unique global minimizer of the proposed augmented-Lagrangian formulation; moreover, the landscape contains no spurious interior stationary points, and the true DAG is the only acyclic KKT point. Numerical experiments on synthetic and real-world data show that the proposed method improves over state-of-the-art continuous DAG-learning alternatives.
BUILD with Precision: Bottom-Up Inference of Linear DAGs
Dec 18, 2025Learning the structure of directed acyclic graphs (DAGs) from observational data is a central problem in causal discovery, statistical signal processing, and machine learning. Under a linear Gaussian structural equation model (SEM) with equal noise variances, the problem is identifiable and we show that the ensemble precision matrix of the observations exhibits a distinctive structure that facilitates DAG recovery. Exploiting this property, we propose BUILD (Bottom-Up Inference of Linear DAGs), a deterministic stepwise algorithm that identifies leaf nodes and their parents, then prunes the leaves by removing incident edges to proceed to the next step, exactly reconstructing the DAG from the true precision matrix. In practice, precision matrices must be estimated from finite data, and ill-conditioning may lead to error accumulation across BUILD steps. As a mitigation strategy, we periodically re-estimate the precision matrix (with less variables as leaves are pruned), trading off runtime for enhanced robustness. Reproducible results on challenging synthetic benchmarks demonstrate that BUILD compares favorably to state-of-the-art DAG learning algorithms, while offering an explicit handle on complexity.
Non-negative DAG Learning from Time-Series Data
Dec 08, 2025This work aims to learn the directed acyclic graph (DAG) that captures the instantaneous dependencies underlying a multivariate time series. The observed data follow a linear structural vector autoregressive model (SVARM) with both instantaneous and time-lagged dependencies, where the instantaneous structure is modeled by a DAG to reflect potential causal relationships. While recent continuous relaxation approaches impose acyclicity through smooth constraint functions involving powers of the adjacency matrix, they lead to non-convex optimization problems that are challenging to solve. In contrast, we assume that the underlying DAG has only non-negative edge weights, and leverage this additional structure to impose acyclicity via a convex constraint. This enables us to cast the problem of non-negative DAG recovery from multivariate time-series data as a convex optimization problem in abstract form, which we solve using the method of multipliers. Crucially, the convex formulation guarantees global optimality of the solution. Finally, we assess the performance of the proposed method on synthetic time-series data, where it outperforms existing alternatives.
Precision Neural Networks: Joint Graph And Relational Learning
Sep 18, 2025CoVariance Neural Networks (VNNs) perform convolutions on the graph determined by the covariance matrix of the data, which enables expressive and stable covariance-based learning. However, covariance matrices are typically dense, fail to encode conditional independence, and are often precomputed in a task-agnostic way, which may hinder performance. To overcome these limitations, we study Precision Neural Networks (PNNs), i.e., VNNs on the precision matrix -- the inverse covariance. The precision matrix naturally encodes statistical independence, often exhibits sparsity, and preserves the covariance spectral structure. To make precision estimation task-aware, we formulate an optimization problem that jointly learns the network parameters and the precision matrix, and solve it via alternating optimization, by sequentially updating the network weights and the precision estimate. We theoretically bound the distance between the estimated and true precision matrices at each iteration, and demonstrate the effectiveness of joint estimation compared to two-step approaches on synthetic and real-world data.
Directed Acyclic Graph Convolutional Networks
Jun 13, 2025Directed acyclic graphs (DAGs) are central to science and engineering applications including causal inference, scheduling, and neural architecture search. In this work, we introduce the DAG Convolutional Network (DCN), a novel graph neural network (GNN) architecture designed specifically for convolutional learning from signals supported on DAGs. The DCN leverages causal graph filters to learn nodal representations that account for the partial ordering inherent to DAGs, a strong inductive bias does not present in conventional GNNs. Unlike prior art in machine learning over DAGs, DCN builds on formal convolutional operations that admit spectral-domain representations. We further propose the Parallel DCN (PDCN), a model that feeds input DAG signals to a parallel bank of causal graph-shift operators and processes these DAG-aware features using a shared multilayer perceptron. This way, PDCN decouples model complexity from graph size while maintaining satisfactory predictive performance. The architectures' permutation equivariance and expressive power properties are also established. Comprehensive numerical tests across several tasks, datasets, and experimental conditions demonstrate that (P)DCN compares favorably with state-of-the-art baselines in terms of accuracy, robustness, and computational efficiency. These results position (P)DCN as a viable framework for deep learning from DAG-structured data that is designed from first (graph) signal processing principles.
Adapting to Heterophilic Graph Data with Structure-Guided Neighbor Discovery
Jun 10, 2025Graph Neural Networks (GNNs) often struggle with heterophilic data, where connected nodes may have dissimilar labels, as they typically assume homophily and rely on local message passing. To address this, we propose creating alternative graph structures by linking nodes with similar structural attributes (e.g., role-based or global), thereby fostering higher label homophily on these new graphs. We theoretically prove that GNN performance can be improved by utilizing graphs with fewer false positive edges (connections between nodes of different classes) and that considering multiple graph views increases the likelihood of finding such beneficial structures. Building on these insights, we introduce Structure-Guided GNN (SG-GNN), an architecture that processes the original graph alongside the newly created structural graphs, adaptively learning to weigh their contributions. Extensive experiments on various benchmark datasets, particularly those with heterophilic characteristics, demonstrate that our SG-GNN achieves state-of-the-art or highly competitive performance, highlighting the efficacy of exploiting structural information to guide GNNs.
Enhancing Graphical Lasso: A Robust Scheme for Non-Stationary Mean Data
Mar 25, 2025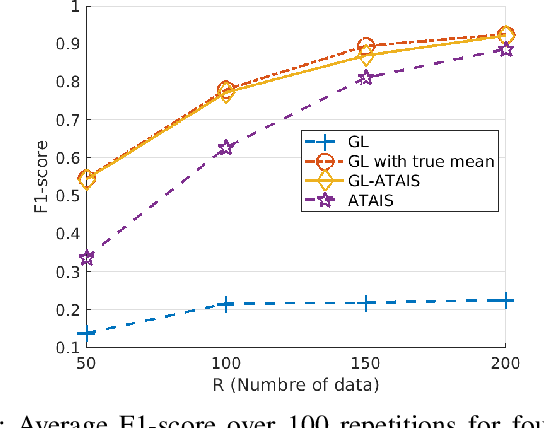
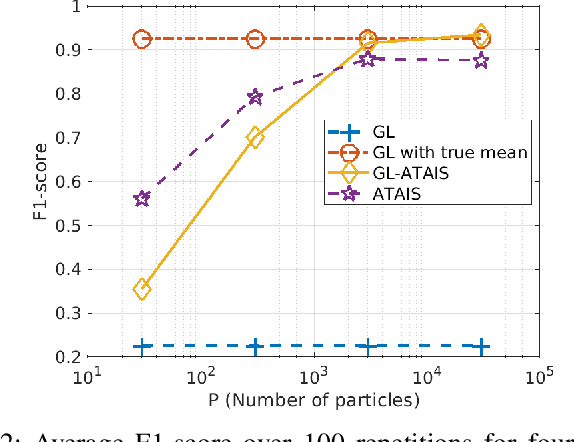
This work addresses the problem of graph learning from data following a Gaussian Graphical Model (GGM) with a time-varying mean. Graphical Lasso (GL), the standard method for estimating sparse precision matrices, assumes that the observed data follows a zero-mean Gaussian distribution. However, this assumption is often violated in real-world scenarios where the mean evolves over time due to external influences, trends, or regime shifts. When the mean is not properly accounted for, applying GL directly can lead to estimating a biased precision matrix, hence hindering the graph learning task. To overcome this limitation, we propose Graphical Lasso with Adaptive Targeted Adaptive Importance Sampling (GL-ATAIS), an iterative method that jointly estimates the time-varying mean and the precision matrix. Our approach integrates Bayesian inference with frequentist estimation, leveraging importance sampling to obtain an estimate of the mean while using a regularized maximum likelihood estimator to infer the precision matrix. By iteratively refining both estimates, GL-ATAIS mitigates the bias introduced by time-varying means, leading to more accurate graph recovery. Our numerical evaluation demonstrates the impact of properly accounting for time-dependent means and highlights the advantages of GL-ATAIS over standard GL in recovering the true graph structure.
Structure-Guided Input Graph for GNNs facing Heterophily
Dec 02, 2024Graph Neural Networks (GNNs) have emerged as a promising tool to handle data exhibiting an irregular structure. However, most GNN architectures perform well on homophilic datasets, where the labels of neighboring nodes are likely to be the same. In recent years, an increasing body of work has been devoted to the development of GNN architectures for heterophilic datasets, where labels do not exhibit this low-pass behavior. In this work, we create a new graph in which nodes are connected if they share structural characteristics, meaning a higher chance of sharing their labels, and then use this new graph in the GNN architecture. To do this, we compute the k-nearest neighbors graph according to distances between structural features, which are either (i) role-based, such as degree, or (ii) global, such as centrality measures. Experiments show that the labels are smoother in this newly defined graph and that the performance of GNN architectures improves when using this alternative structure.
Online Learning Of Expanding Graphs
Sep 13, 2024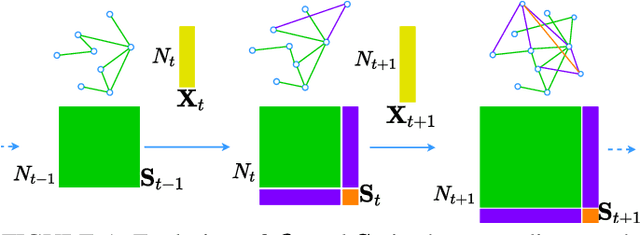
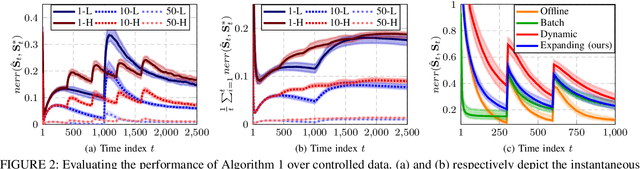
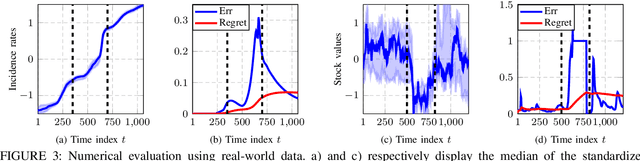
This paper addresses the problem of online network topology inference for expanding graphs from a stream of spatiotemporal signals. Online algorithms for dynamic graph learning are crucial in delay-sensitive applications or when changes in topology occur rapidly. While existing works focus on inferring the connectivity within a fixed set of nodes, in practice, the graph can grow as new nodes join the network. This poses additional challenges like modeling temporal dynamics involving signals and graphs of different sizes. This growth also increases the computational complexity of the learning process, which may become prohibitive. To the best of our knowledge, this is the first work to tackle this setting. We propose a general online algorithm based on projected proximal gradient descent that accounts for the increasing graph size at each iteration. Recursively updating the sample covariance matrix is a key aspect of our approach. We introduce a strategy that enables different types of updates for nodes that just joined the network and for previously existing nodes. To provide further insights into the proposed method, we specialize it in Gaussian Markov random field settings, where we analyze the computational complexity and characterize the dynamic cumulative regret. Finally, we demonstrate the effectiveness of the proposed approach using both controlled experiments and real-world datasets from epidemic and financial networks.