 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Graphical Lasso: A Robust Scheme for Non-Stationary Mean Data
Mar 25, 2025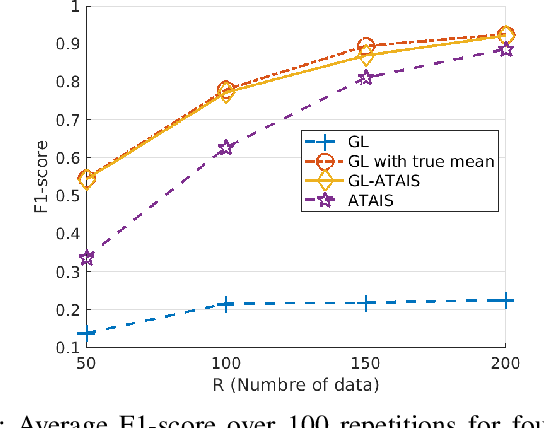
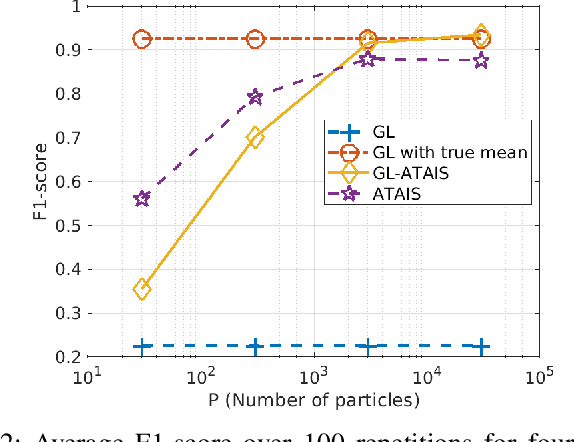
This work addresses the problem of graph learning from data following a Gaussian Graphical Model (GGM) with a time-varying mean. Graphical Lasso (GL), the standard method for estimating sparse precision matrices, assumes that the observed data follows a zero-mean Gaussian distribution. However, this assumption is often violated in real-world scenarios where the mean evolves over time due to external influences, trends, or regime shifts. When the mean is not properly accounted for, applying GL directly can lead to estimating a biased precision matrix, hence hindering the graph learning task. To overcome this limitation, we propose Graphical Lasso with Adaptive Targeted Adaptive Importance Sampling (GL-ATAIS), an iterative method that jointly estimates the time-varying mean and the precision matrix. Our approach integrates Bayesian inference with frequentist estimation, leveraging importance sampling to obtain an estimate of the mean while using a regularized maximum likelihood estimator to infer the precision matrix. By iteratively refining both estimates, GL-ATAIS mitigates the bias introduced by time-varying means, leading to more accurate graph recovery. Our numerical evaluation demonstrates the impact of properly accounting for time-dependent means and highlights the advantages of GL-ATAIS over standard GL in recovering the true graph structure.
Neural lasso: a unifying approach of lasso and neural networks
Sep 07, 2023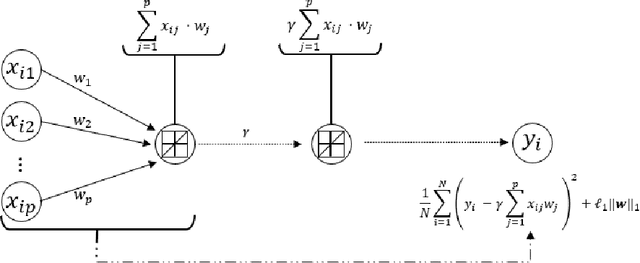
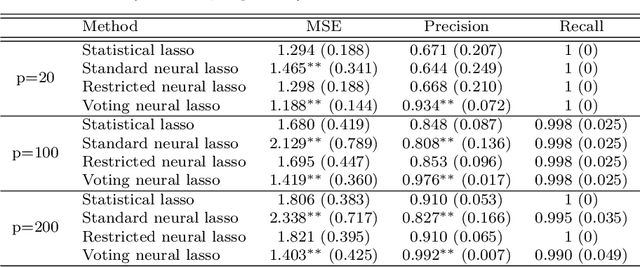
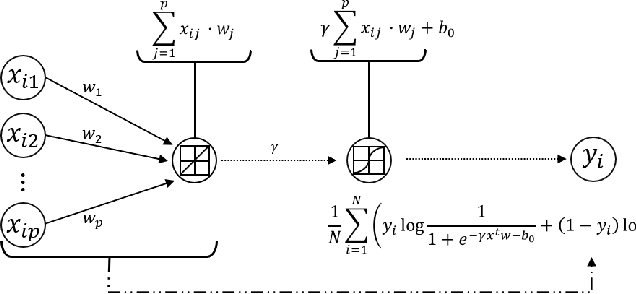
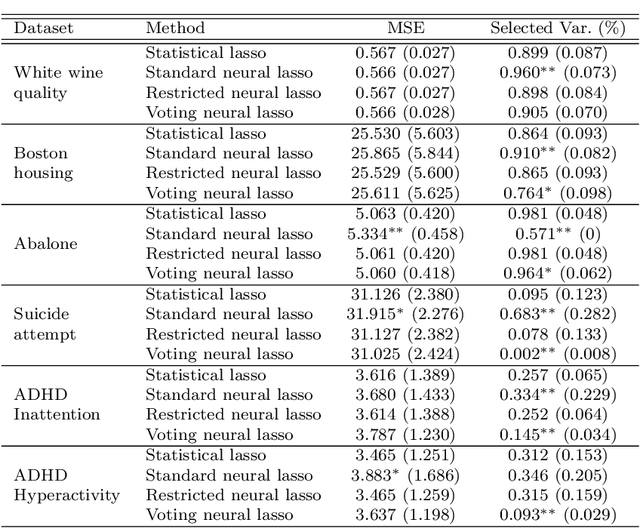
In recent years, there is a growing interest in combining techniques attributed to the areas of Statistics and Machine Learning in order to obtain the benefits of both approaches. In this article, the statistical technique lasso for variable selection is represented through a neural network. It is observed that, although both the statistical approach and its neural version have the same objective function, they differ due to their optimization. In particular, the neural version is usually optimized in one-step using a single validation set, while the statistical counterpart uses a two-step optimization based on cross-validation. The more elaborated optimization of the statistical method results in more accurate parameter estimation, especially when the training set is small. For this reason, a modification of the standard approach for training neural networks, that mimics the statistical framework, is proposed. During the development of the above modification, a new optimization algorithm for identifying the significant variables emerged. Experimental results, using synthetic and real data sets, show that this new optimization algorithm achieves better performance than any of the three previous optimization approaches.