 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactored Agents: Decoupling In-Context Learning and Memorization for Robust Tool Use
Apr 02, 2025In this paper, we propose a novel factored agent architecture designed to overcome the limitations of traditional single-agent systems in agentic AI. Our approach decomposes the agent into two specialized components: (1) a large language model (LLM) that serves as a high level planner and in-context learner, which may use dynamically available information in user prompts, (2) a smaller language model which acts as a memorizer of tool format and output. This decoupling addresses prevalent issues in monolithic designs, including malformed, missing, and hallucinated API fields, as well as suboptimal planning in dynamic environments. Empirical evaluations demonstrate that our factored architecture significantly improves planning accuracy and error resilience, while elucidating the inherent trade-off between in-context learning and static memorization. These findings suggest that a factored approach is a promising pathway for developing more robust and adaptable agentic AI systems.
SLoG-Net: Algorithm Unrolling for Source Localization on Graphs
Dec 31, 2024We present a novel model-based deep learning solution for the inverse problem of localizing sources of network diffusion. Starting from first graph signal processing (GSP) principles, we show that the problem reduces to joint (blind) estimation of the forward diffusion filter and a sparse input signal that encodes the source locations. Despite the bilinear nature of the observations in said blind deconvolution task, by requiring invertibility of the diffusion filter we are able to formulate a convex optimization problem and solve it using the alternating-direction method of multipliers (ADMM). We then unroll and truncate the novel ADMM iterations to arrive at a parameterized neural network architecture for Source Localization on Graphs (SLoG-Net), that we train in an end-to-end fashion using labeled data. This supervised learning approach offers several advantages such as interpretability, parameter efficiency, and controllable complexity during inference. Our reproducible numerical experiments corroborate that SLoG-Net exhibits performance on par with the iterative ADMM baseline, but with markedly faster inference times and without needing to manually tune step-size or penalty parameters. Overall, our approach combines the best of both worlds by incorporating the inductive biases of a GSP model-based solution within a data-driven, trainable deep learning architecture for blind deconvolution of graph signals.
Blind Deconvolution of Graph Signals: Robustness to Graph Perturbations
Dec 19, 2024We study blind deconvolution of signals defined on the nodes of an undirected graph. Although observations are bilinear functions of both unknowns, namely the forward convolutional filter coefficients and the graph signal input, a filter invertibility requirement along with input sparsity allow for an efficient linear programming reformulation. Unlike prior art that relied on perfect knowledge of the graph eigenbasis, here we derive stable recovery conditions in the presence of small graph perturbations. We also contribute a provably convergent robust algorithm, which alternates between blind deconvolution of graph signals and eigenbasis denoising in the Stiefel manifold. Reproducible numerical tests showcase the algorithm's robustness under several graph eigenbasis perturbation models.
Blind Deconvolution on Graphs: Exact and Stable Recovery
Sep 18, 2024


We study a blind deconvolution problem on graphs, which arises in the context of localizing a few sources that diffuse over networks. While the observations are bilinear functions of the unknown graph filter coefficients and sparse input signals, a mild requirement on invertibility of the diffusion filter enables an efficient convex relaxation leading to a linear programming formulation that can be tackled with off-the-shelf solvers. Under the Bernoulli-Gaussian model for the inputs, we derive sufficient exact recovery conditions in the noise-free setting. A stable recovery result is then established, ensuring the estimation error remains manageable even when the observations are corrupted by a small amount of noise. Numerical tests with synthetic and real-world network data illustrate the merits of the proposed algorithm, its robustness to noise as well as the benefits of leveraging multiple signals to aid the (blind) localization of sources of diffusion. At a fundamental level, the results presented here broaden the scope of classical blind deconvolution of (spatio-)temporal signals to irregular graph domains.
Open RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



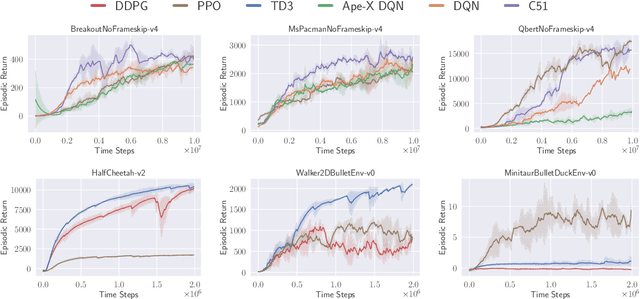
In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.
CleanRL: High-quality Single-file Implementations of Deep Reinforcement Learning Algorithms
Nov 16, 2021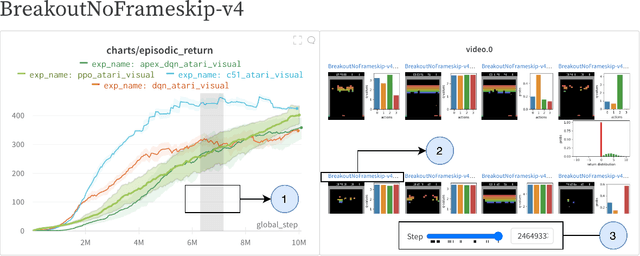
CleanRL is an open-source library that provides high-quality single-file implementations of Deep Reinforcement Learning algorithms. It provides a simpler yet scalable developing experience by having a straightforward codebase and integrating production tools to help interact and scale experiments. In CleanRL, we put all details of an algorithm into a single file, making these performance-relevant details easier to recognize. Additionally, an experiment tracking feature is available to help log metrics, hyperparameters, videos of an agent's gameplay, dependencies, and more to the cloud. Despite succinct implementations, we have also designed tools to help scale, at one point orchestrating experiments on more than 2000 machines simultaneously via Docker and cloud providers. Finally, we have ensured the quality of the implementations by benchmarking against a variety of environments. The source code of CleanRL can be found at https://github.com/vwxyzjn/cleanrl
Rotation, Translation, and Cropping for Zero-Shot Generalization
Jan 27, 2020
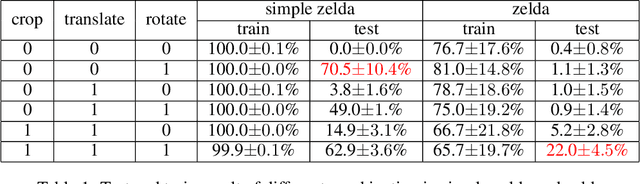


Deep Reinforcement Learning (DRL) has shown impressive performance on domains with visual inputs, in particular various games. However, the agent is usually trained on a fixed environment, e.g. a fixed number of levels. A growing mass of evidence suggests that these trained models fail to generalize to even slight variations of the environments they were trained on. This paper advances the hypothesis that the lack of generalization is partly due to the input representation, and explores how rotation, cropping and translation could increase generality. We show that a cropped, translated and rotated observation can get better generalization on unseen levels of a two-dimensional arcade game. The generality of the agent is evaluated on a set of human-designed levels.