 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotation, Translation, and Cropping for Zero-Shot Generalization
Paper and Code

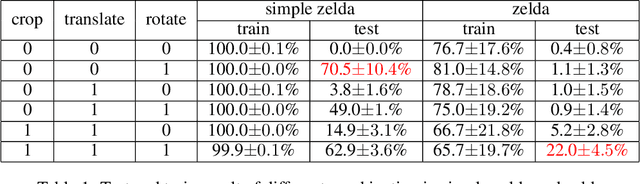


Deep Reinforcement Learning (DRL) has shown impressive performance on domains with visual inputs, in particular various games. However, the agent is usually trained on a fixed environment, e.g. a fixed number of levels. A growing mass of evidence suggests that these trained models fail to generalize to even slight variations of the environments they were trained on. This paper advances the hypothesis that the lack of generalization is partly due to the input representation, and explores how rotation, cropping and translation could increase generality. We show that a cropped, translated and rotated observation can get better generalization on unseen levels of a two-dimensional arcade game. The generality of the agent is evaluated on a set of human-designed levels.