 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNNs for Time Series Anomaly Detection: An Open-Source Framework and a Critical Evaluation
Mar 10, 2026There is growing interest in applying graph-based methods to Time Series Anomaly Detection (TSAD), particularly Graph Neural Networks (GNNs), as they naturally model dependencies among multivariate signals. GNNs are typically used as backbones in score-based TSAD pipelines, where anomalies are identified through reconstruction or prediction errors followed by thresholding. However, and despite promising results, the field still lacks standardized frameworks for evaluation and suffers from persistent issues with metric design and interpretation. We thus present an open-source framework for TSAD using GNNs, designed to support reproducible experimentation across datasets, graph structures, and evaluation strategies. Built with flexibility and extensibility in mind, the framework facilitates systematic comparisons between TSAD models and enables in-depth analysis of performance and interpretability. Using this tool, we evaluate several GNN-based architectures alongside baseline models across two real-world datasets with contrasting structural characteristics. Our results show that GNNs not only improve detection performance but also offer significant gains in interpretability, an especially valuable feature for practical diagnosis. We also find that attention-based GNNs offer robustness when graph structure is uncertain or inferred. In addition, we reflect on common evaluation practices in TSAD, showing how certain metrics and thresholding strategies can obscure meaningful comparisons. Overall, this work contributes both practical tools and critical insights to advance the development and evaluation of graph-based TSAD systems.
Weighted Random Dot Product Graphs
May 07, 2025



Modeling of intricate relational patterns has become a cornerstone of contemporary statistical research and related data science fields. Networks, represented as graphs, offer a natural framework for this analysis. This paper extends the Random Dot Product Graph (RDPG) model to accommodate weighted graphs, markedly broadening the model's scope to scenarios where edges exhibit heterogeneous weight distributions. We propose a nonparametric weighted (W)RDPG model that assigns a sequence of latent positions to each node. Inner products of these nodal vectors specify the moments of their incident edge weights' distribution via moment-generating functions. In this way, and unlike prior art, the WRDPG can discriminate between weight distributions that share the same mean but differ in other higher-order moments. We derive statistical guarantees for an estimator of the nodal's latent positions adapted from the workhorse adjacency spectral embedding, establishing its consistency and asymptotic normality. We also contribute a generative framework that enables sampling of graphs that adhere to a (prescribed or data-fitted) WRDPG, facilitating, e.g., the analysis and testing of observed graph metrics using judicious reference distributions. The paper is organized to formalize the model's definition, the estimation (or nodal embedding) process and its guarantees, as well as the methodologies for generating weighted graphs, all complemented by illustrative and reproducible examples showcasing the WRDPG's effectiveness in various network analytic applications.
LASE: Learned Adjacency Spectral Embeddings
Dec 23, 2024We put forth a principled design of a neural architecture to learn nodal Adjacency Spectral Embeddings (ASE) from graph inputs. By bringing to bear the gradient descent (GD) method and leveraging the principle of algorithm unrolling, we truncate and re-interpret each GD iteration as a layer in a graph neural network (GNN) that is trained to approximate the ASE. Accordingly, we call the resulting embeddings and our parametric model Learned ASE (LASE), which is interpretable, parameter efficient, robust to inputs with unobserved edges, and offers controllable complexity during inference. LASE layers combine Graph Convolutional Network (GCN) and fully-connected Graph Attention Network (GAT) modules, which is intuitively pleasing since GCN-based local aggregations alone are insufficient to express the sought graph eigenvectors. We propose several refinements to the unrolled LASE architecture (such as sparse attention in the GAT module and decoupled layerwise parameters) that offer favorable approximation error versus computation tradeoffs; even outperforming heavily-optimized eigendecomposition routines from scientific computing libraries. Because LASE is a differentiable function with respect to its parameters as well as its graph input, we can seamlessly integrate it as a trainable module within a larger (semi-)supervised graph representation learning pipeline. The resulting end-to-end system effectively learns ``discriminative ASEs'' that exhibit competitive performance in supervised link prediction and node classification tasks, outperforming a GNN even when the latter is endowed with open loop, meaning task-agnostic, precomputed spectral positional encodings.
Gradient-Based Spectral Embeddings of Random Dot Product Graphs
Jul 25, 2023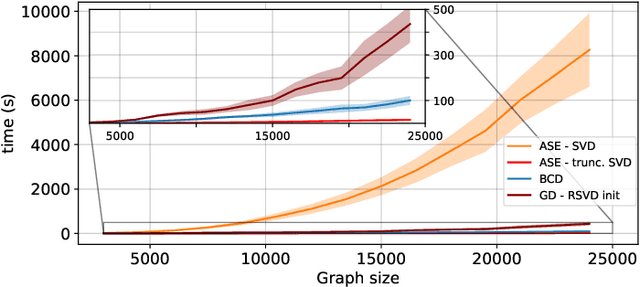



The Random Dot Product Graph (RDPG) is a generative model for relational data, where nodes are represented via latent vectors in low-dimensional Euclidean space. RDPGs crucially postulate that edge formation probabilities are given by the dot product of the corresponding latent positions. Accordingly, the embedding task of estimating these vectors from an observed graph is typically posed as a low-rank matrix factorization problem. The workhorse Adjacency Spectral Embedding (ASE) enjoys solid statistical properties, but it is formally solving a surrogate problem and can be computationally intensive. In this paper, we bring to bear recent advances in non-convex optimization and demonstrate their impact to RDPG inference. We advocate first-order gradient descent methods to better solve the embedding problem, and to organically accommodate broader network embedding applications of practical relevance. Notably, we argue that RDPG embeddings of directed graphs loose interpretability unless the factor matrices are constrained to have orthogonal columns. We thus develop a novel feasible optimization method in the resulting manifold. The effectiveness of the graph representation learning framework is demonstrated on reproducible experiments with both synthetic and real network data. Our open-source algorithm implementations are scalable, and unlike the ASE they are robust to missing edge data and can track slowly-varying latent positions from streaming graphs.
Online Change Point Detection for Weighted and Directed Random Dot Product Graphs
Jan 26, 2022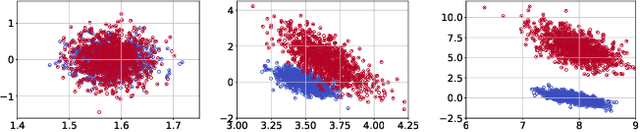
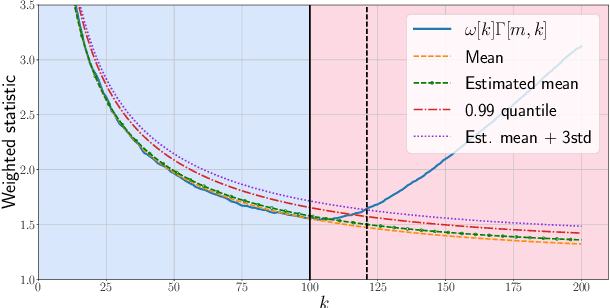
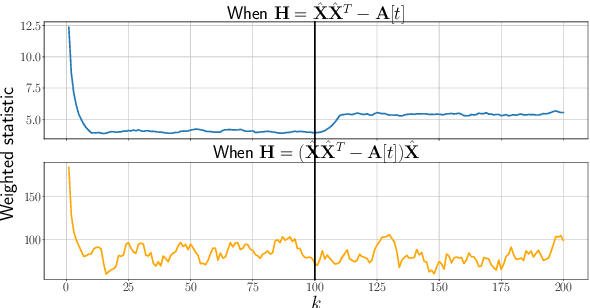
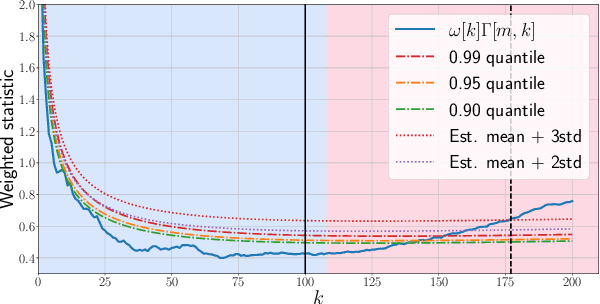
Given a sequence of random (directed and weighted) graphs, we address the problem of online monitoring and detection of changes in the underlying data distribution. Our idea is to endow sequential change-point detection (CPD) techniques with a graph representation learning substrate based on the versatile Random Dot Product Graph (RDPG) model. We consider efficient, online updates of a judicious monitoring function, which quantifies the discrepancy between the streaming graph observations and the nominal RDPG. This reference distribution is inferred via spectral embeddings of the first few graphs in the sequence. We characterize the distribution of this running statistic to select thresholds that guarantee error-rate control, and under simplifying approximations we offer insights on the algorithm's detection resolution and delay. The end result is a lightweight online CPD algorithm, that is also explainable by virtue of the well-appreciated interpretability of RDPG embeddings. This is in stark contrast with most existing graph CPD approaches, which either rely on extensive computation, or they store and process the entire observed time series. An apparent limitation of the RDPG model is its suitability for undirected and unweighted graphs only, a gap we aim to close here to broaden the scope of the CPD framework. Unlike previous proposals, our non-parametric RDPG model for weighted graphs does not require a priori specification of the weights' distribution to perform inference and estimation. This network modeling contribution is of independent interest beyond CPD. We offer an open-source implementation of the novel online CPD algorithm for weighted and direct graphs, whose effectiveness and efficiency are demonstrated via (reproducible) synthetic and real network data experiments.
Re-Weighted $\ell_1$ Algorithms within the Lagrange Duality Framework: Bringing Interpretability to Weights
Jun 21, 2019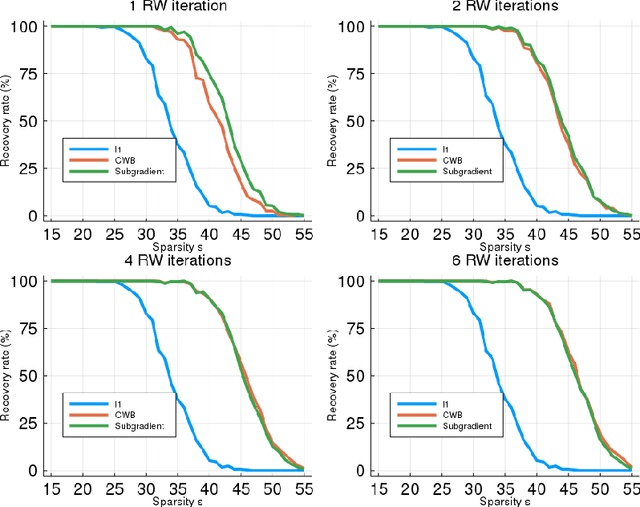
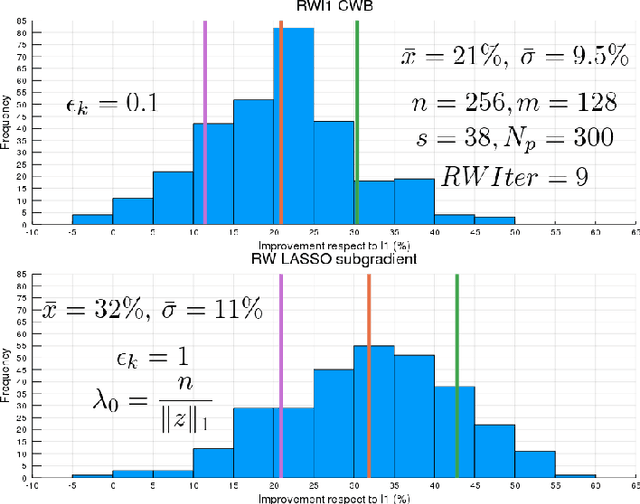
We consider an important problem in signal processing, which consists in finding the sparsest solution of a linear system $\Phi x=b$. This problem has applications in several areas, but is NP-hard in general. Usually an alternative convex problem is considered, based on minimizing the (weighted) $\ell_{1}$ norm. For this alternative to be useful, weights should be chosen as to obtain a solution of the original NP-hard problem. A well known algorithm for this is the Re-Weighted $\ell_{1}$, proposed by Cand\`es, Wakin and Boyd. In this article we introduce a new methodology for updating the weights of a Re-Weighted $\ell_{1}$ algorithm, based on identifying these weights as Lagrange multipliers. This is then translated into an algorithm with performance comparable to the usual methodology, but allowing an interpretation of the weights as Lagrange multipliers. The methodology may also be used for a noisy linear system, obtaining in this case a Re-Weighted LASSO algorithm, with a promising performance according to the experimental results.
Graph Matching: Relax at Your Own Risk
Jan 10, 2015
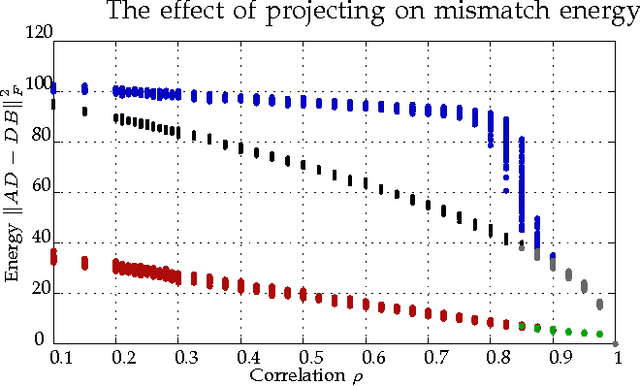
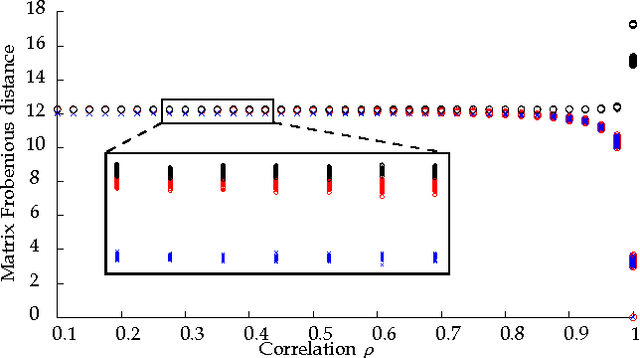
Graph matching---aligning a pair of graphs to minimize their edge disagreements---has received wide-spread attention from both theoretical and applied communities over the past several decades, including combinatorics, computer vision, and connectomics. Its attention can be partially attributed to its computational difficulty. Although many heuristics have previously been proposed in the literature to approximately solve graph matching, very few have any theoretical support for their performance. A common technique is to relax the discrete problem to a continuous problem, therefore enabling practitioners to bring gradient-descent-type algorithms to bear. We prove that an indefinite relaxation (when solved exactly) almost always discovers the optimal permutation, while a common convex relaxation almost always fails to discover the optimal permutation. These theoretical results suggest that initializing the indefinite algorithm with the convex optimum might yield improved practical performance. Indeed, experimental results illuminate and corroborate these theoretical findings, demonstrating that excellent results are achieved in both benchmark and real data problems by amalgamating the two approaches.
Robust Multimodal Graph Matching: Sparse Coding Meets Graph Matching
Nov 25, 2013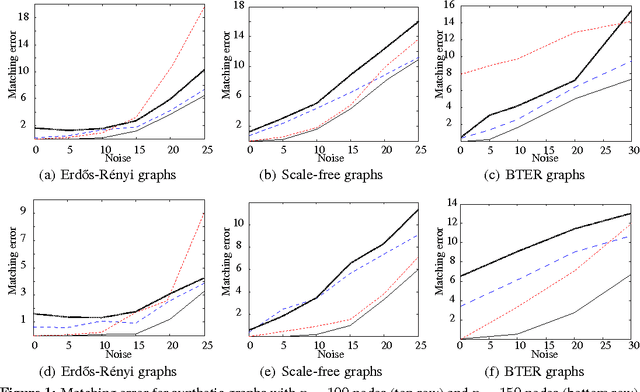
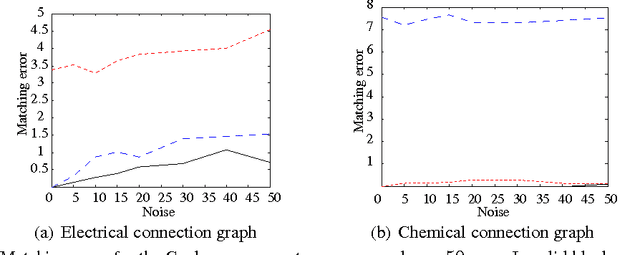
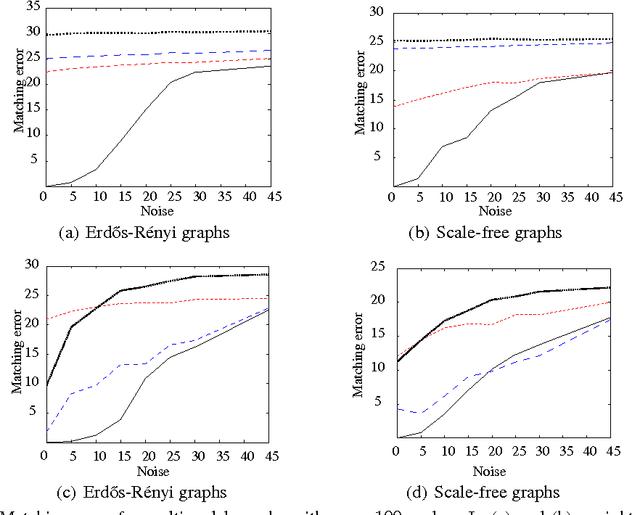
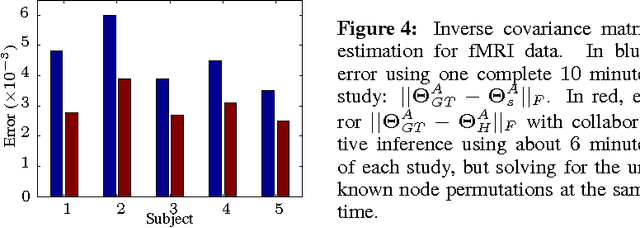
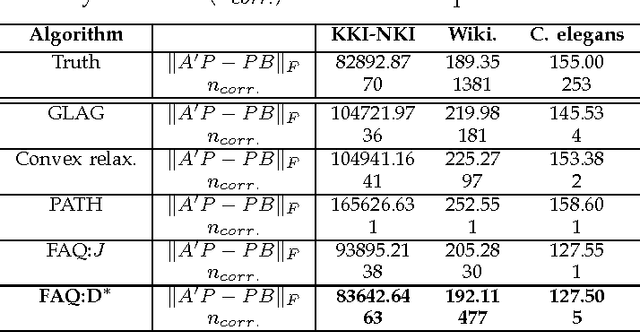
Graph matching is a challenging problem with very important applications in a wide range of fields, from image and video analysis to biological and biomedical problems. We propose a robust graph matching algorithm inspired in sparsity-related techniques. We cast the problem, resembling group or collaborative sparsity formulations, as a non-smooth convex optimization problem that can be efficiently solved using augmented Lagrangian techniques. The method can deal with weighted or unweighted graphs, as well as multimodal data, where different graphs represent different types of data. The proposed approach is also naturally integrated with collaborative graph inference techniques, solving general network inference problems where the observed variables, possibly coming from different modalities, are not in correspondence. The algorithm is tested and compared with state-of-the-art graph matching techniques in both synthetic and real graphs. We also present results on multimodal graphs and applications to collaborative inference of brain connectivity from alignment-free functional magnetic resonance imaging (fMRI) data. The code is publicly available.
A new framework for optimal classifier design
Sep 12, 2013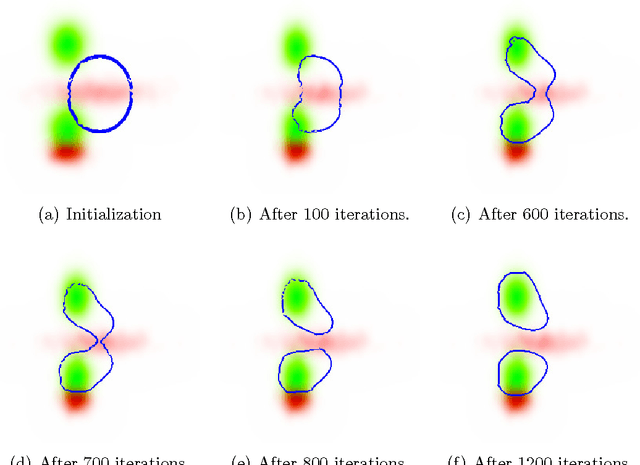
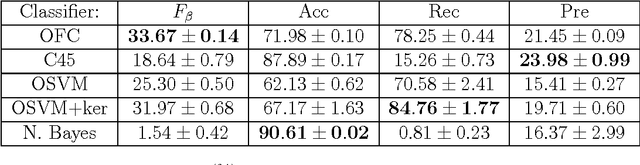
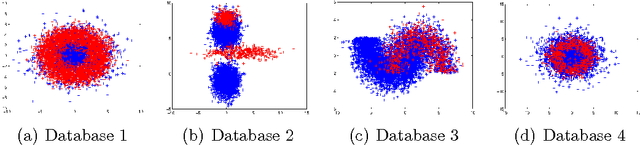
The use of alternative measures to evaluate classifier performance is gaining attention, specially for imbalanced problems. However, the use of these measures in the classifier design process is still unsolved. In this work we propose a classifier designed specifically to optimize one of these alternative measures, namely, the so-called F-measure. Nevertheless, the technique is general, and it can be used to optimize other evaluation measures. An algorithm to train the novel classifier is proposed, and the numerical scheme is tested with several databases, showing the optimality and robustness of the presented classifier.
A Complete System for Candidate Polyps Detection in Virtual Colonoscopy
Sep 28, 2012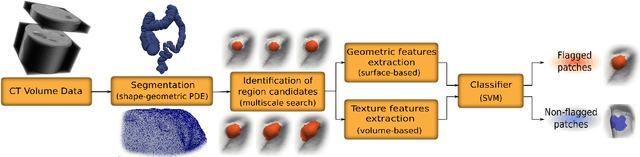

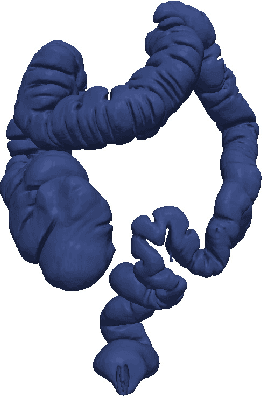
Computer tomographic colonography, combined with computer-aided detection, is a promising emerging technique for colonic polyp analysis. We present a complete pipeline for polyp detection, starting with a simple colon segmentation technique that enhances polyps, followed by an adaptive-scale candidate polyp delineation and classification based on new texture and geometric features that consider both the information in the candidate polyp location and its immediate surrounding area. The proposed system is tested with ground truth data, including flat and small polyps which are hard to detect even with optical colonoscopy. For polyps larger than 6mm in size we achieve 100% sensitivity with just 0.9 false positives per case, and for polyps larger than 3mm in size we achieve 93% sensitivity with 2.8 false positives per case.