 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Silos: Modularity in intra-organizational communication networks during the Covid-19 pandemic
May 01, 2021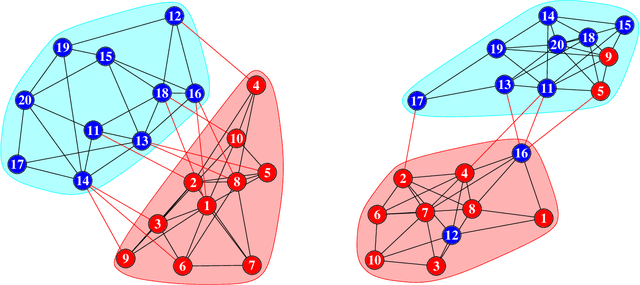

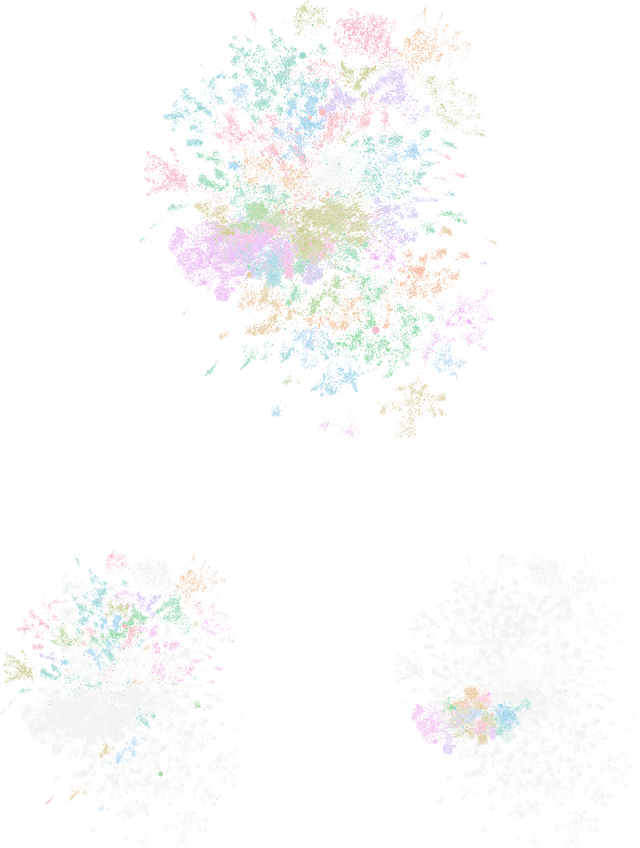
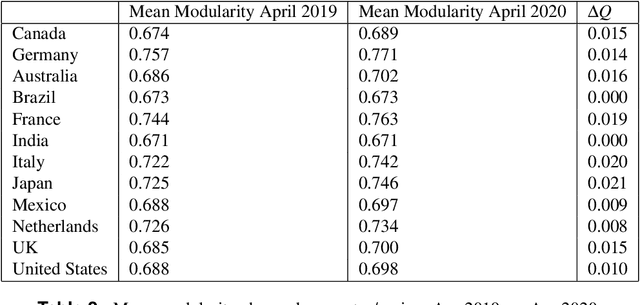
Workplace communications around the world were drastically altered by Covid-19, work-from-home orders, and the rise of remote work. We analyze aggregated, anonymized metadata from over 360 billion emails within over 4000 organizations worldwide to examine changes in network community structures from 2019 through 2020. We find that, during 2020, organizations around the world became more siloed, evidenced by increased modularity. This shift was concurrent with decreased stability, indicating that organizational siloes had less stable membership. We provide initial insights into the implications of these network changes -- which we term dynamic silos -- for organizational performance and innovation.
PACSET (Packed Serialized Trees): Reducing Inference Latency for Tree Ensemble Deployment
Nov 10, 2020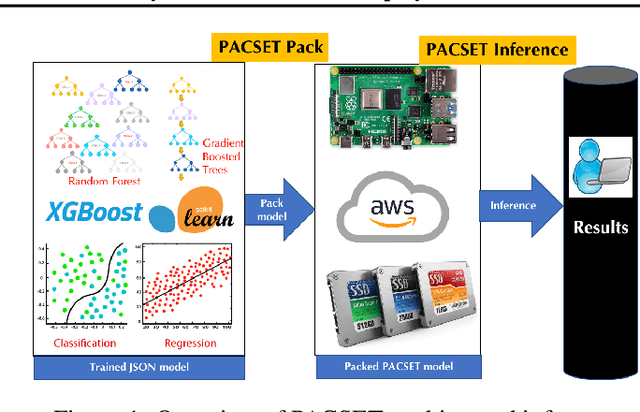


We present methods to serialize and deserialize tree ensembles that optimize inference latency when models are not already loaded into memory. This arises whenever models are larger than memory, but also systematically when models are deployed on low-resource devices, such as in the Internet of Things, or run as Web micro-services where resources are allocated on demand. Our packed serialized trees (PACSET) encode reference locality in the layout of a tree ensemble using principles from external memory algorithms. The layout interleaves correlated nodes across multiple trees, uses leaf cardinality to collocate the nodes on the most popular paths and is optimized for the I/O blocksize. The result is that each I/O yields a higher fraction of useful data, leading to a 2-6 times reduction in classification latency for interactive workloads.
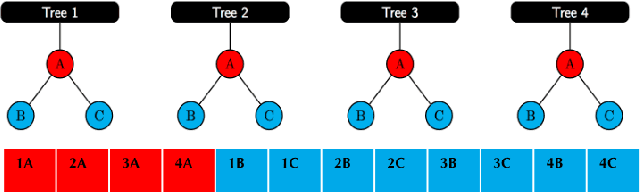
Vertex Classification on Weighted Networks
Jun 07, 2019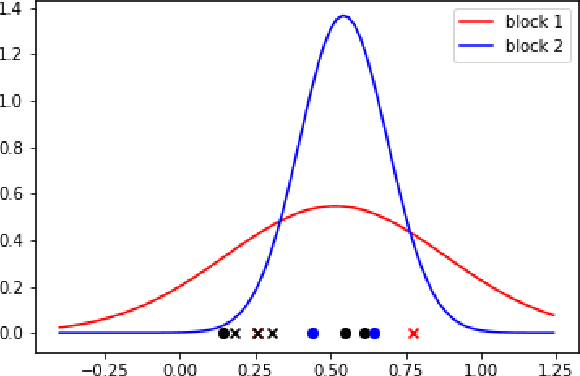

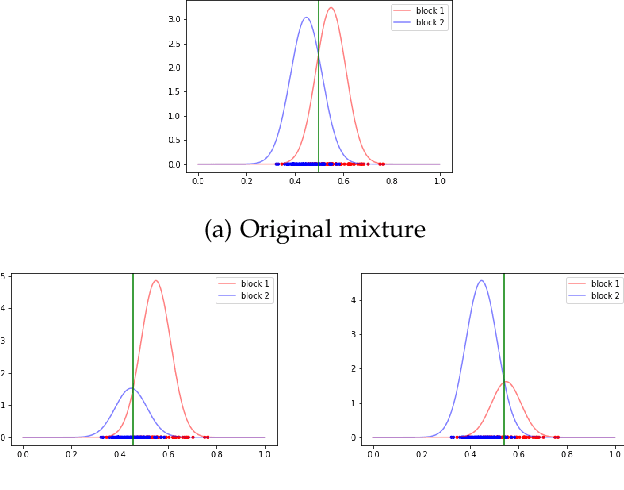
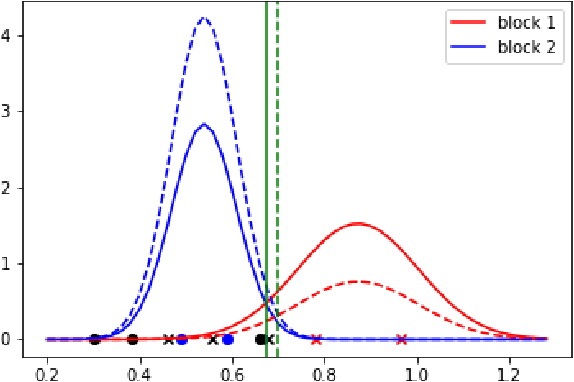
This paper proposes a discrimination technique for vertices in a weighted network. We assume that the edge weights and adjacencies in the network are conditionally independent and that both sources of information encode class membership information. In particular, we introduce a edge weight distribution matrix to the standard K-Block Stochastic Block Model to model weighted networks. This allows us to develop simple yet powerful extensions of classification techniques using the spectral embedding of the unweighted adjacency matrix. We consider two assumptions on the edge weight distributions and propose classification procedures in both settings. We show the effectiveness of the proposed classifiers by comparing them to quadratic discriminant analysis following the spectral embedding of a transformed weighted network. Moreover, we discuss and show how the methods perform when the edge weights do not encode class membership information.
Robust Vertex Classification
Apr 22, 2015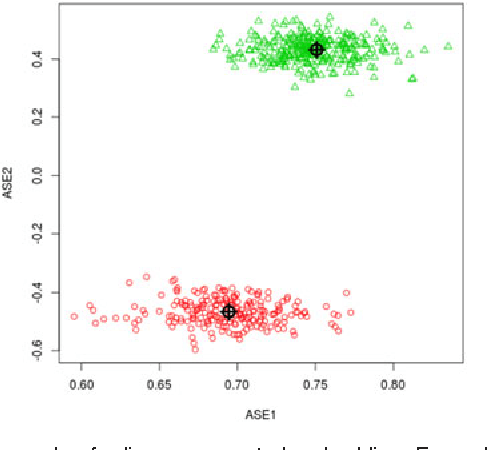
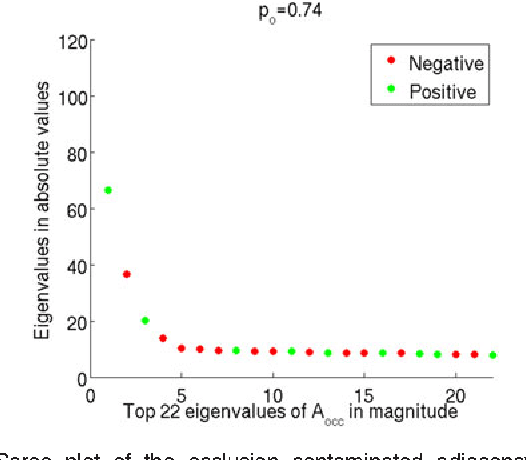
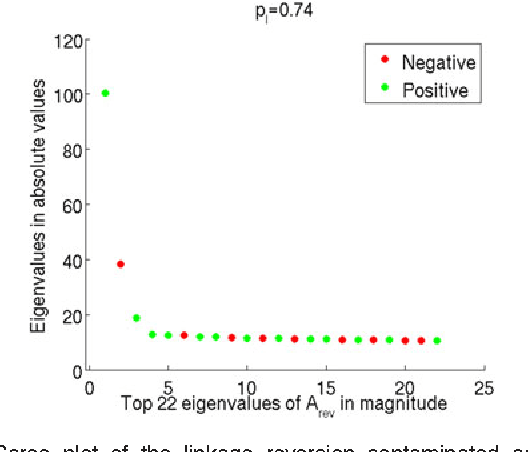
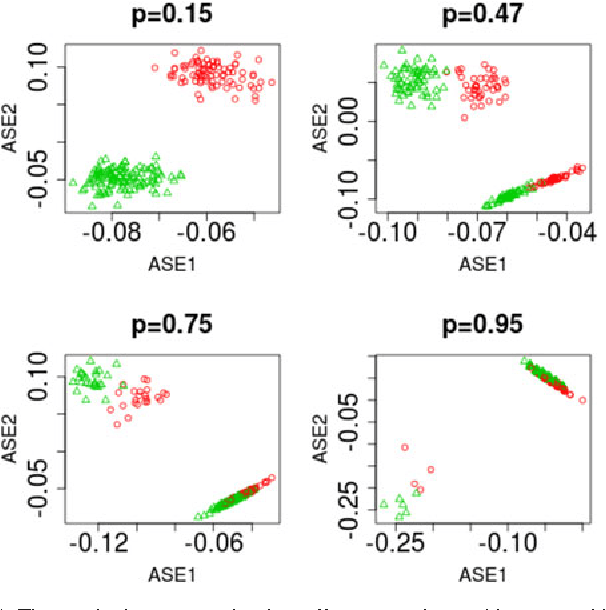
For random graphs distributed according to stochastic blockmodels, a special case of latent position graphs, adjacency spectral embedding followed by appropriate vertex classification is asymptotically Bayes optimal; but this approach requires knowledge of and critically depends on the model dimension. In this paper, we propose a sparse representation vertex classifier which does not require information about the model dimension. This classifier represents a test vertex as a sparse combination of the vertices in the training set and uses the recovered coefficients to classify the test vertex. We prove consistency of our proposed classifier for stochastic blockmodels, and demonstrate that the sparse representation classifier can predict vertex labels with higher accuracy than adjacency spectral embedding approaches via both simulation studies and real data experiments. Our results demonstrate the robustness and effectiveness of our proposed vertex classifier when the model dimension is unknown.
Multiscale Dictionary Learning for Estimating Conditional Distributions
Dec 04, 2013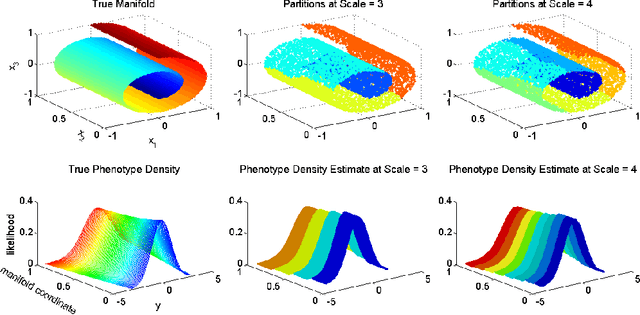
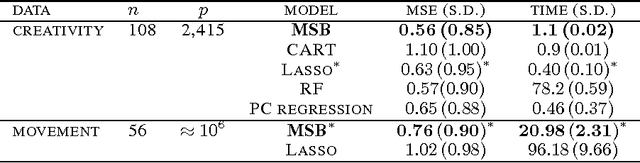
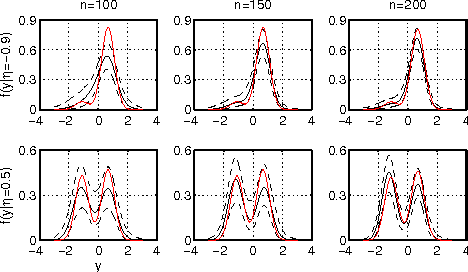
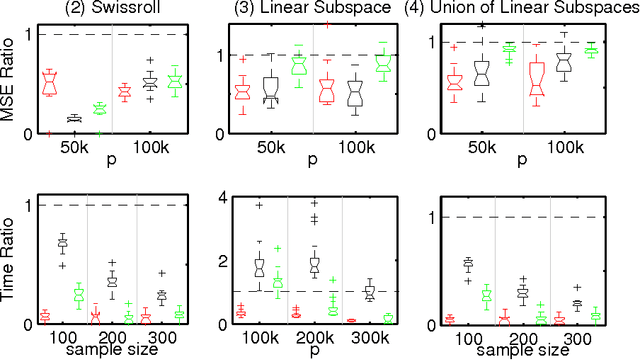
Nonparametric estimation of the conditional distribution of a response given high-dimensional features is a challenging problem. It is important to allow not only the mean but also the variance and shape of the response density to change flexibly with features, which are massive-dimensional. We propose a multiscale dictionary learning model, which expresses the conditional response density as a convex combination of dictionary densities, with the densities used and their weights dependent on the path through a tree decomposition of the feature space. A fast graph partitioning algorithm is applied to obtain the tree decomposition, with Bayesian methods then used to adaptively prune and average over different sub-trees in a soft probabilistic manner. The algorithm scales efficiently to approximately one million features. State of the art predictive performance is demonstrated for toy examples and two neuroscience applications including up to a million features.
Robust Multimodal Graph Matching: Sparse Coding Meets Graph Matching
Nov 25, 2013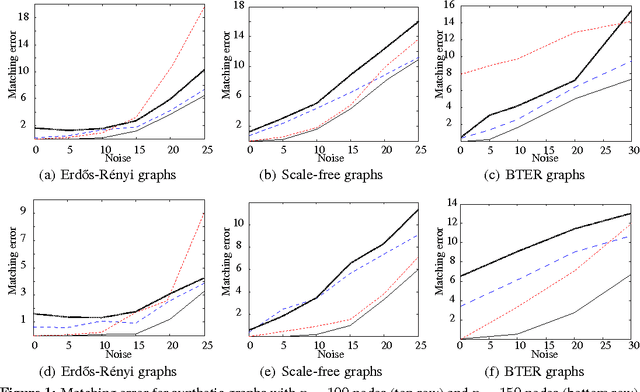
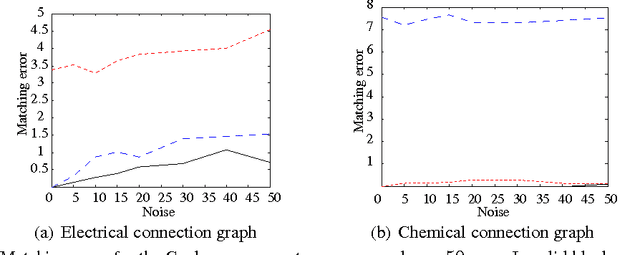
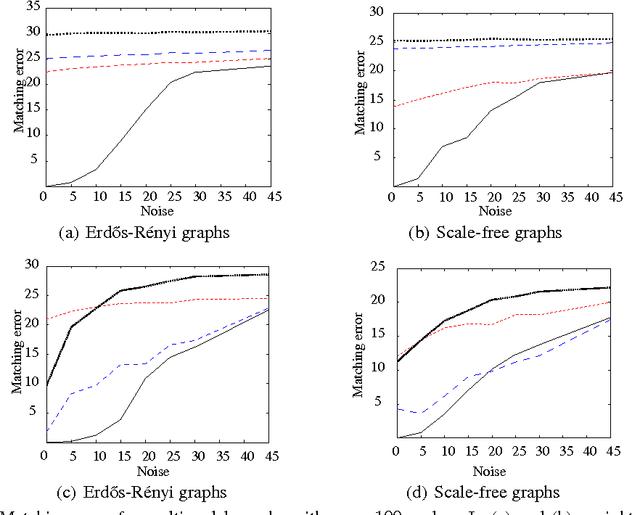
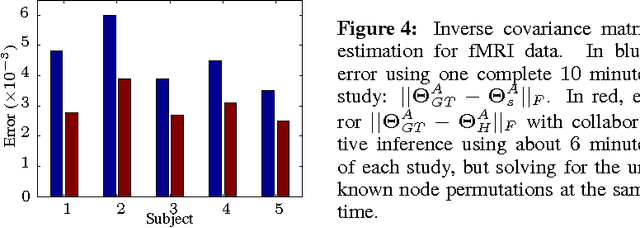
Graph matching is a challenging problem with very important applications in a wide range of fields, from image and video analysis to biological and biomedical problems. We propose a robust graph matching algorithm inspired in sparsity-related techniques. We cast the problem, resembling group or collaborative sparsity formulations, as a non-smooth convex optimization problem that can be efficiently solved using augmented Lagrangian techniques. The method can deal with weighted or unweighted graphs, as well as multimodal data, where different graphs represent different types of data. The proposed approach is also naturally integrated with collaborative graph inference techniques, solving general network inference problems where the observed variables, possibly coming from different modalities, are not in correspondence. The algorithm is tested and compared with state-of-the-art graph matching techniques in both synthetic and real graphs. We also present results on multimodal graphs and applications to collaborative inference of brain connectivity from alignment-free functional magnetic resonance imaging (fMRI) data. The code is publicly available.