 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlur2seq: Blind Deblurring and Camera Trajectory Estimation from a Single Camera Motion-blurred Image
Oct 23, 2025Motion blur caused by camera shake, particularly under large or rotational movements, remains a major challenge in image restoration. We propose a deep learning framework that jointly estimates the latent sharp image and the underlying camera motion trajectory from a single blurry image. Our method leverages the Projective Motion Blur Model (PMBM), implemented efficiently using a differentiable blur creation module compatible with modern networks. A neural network predicts a full 3D rotation trajectory, which guides a model-based restoration network trained end-to-end. This modular architecture provides interpretability by revealing the camera motion that produced the blur. Moreover, this trajectory enables the reconstruction of the sequence of sharp images that generated the observed blurry image. To further refine results, we optimize the trajectory post-inference via a reblur loss, improving consistency between the blurry input and the restored output. Extensive experiments show that our method achieves state-of-the-art performance on both synthetic and real datasets, particularly in cases with severe or spatially variant blur, where end-to-end deblurring networks struggle. Code and trained models are available at https://github.com/GuillermoCarbajal/Blur2Seq/
LATINO-PRO: LAtent consisTency INverse sOlver with PRompt Optimization
Mar 16, 2025Text-to-image latent diffusion models (LDMs) have recently emerged as powerful generative models with great potential for solving inverse problems in imaging. However, leveraging such models in a Plug & Play (PnP), zero-shot manner remains challenging because it requires identifying a suitable text prompt for the unknown image of interest. Also, existing text-to-image PnP approaches are highly computationally expensive. We herein address these challenges by proposing a novel PnP inference paradigm specifically designed for embedding generative models within stochastic inverse solvers, with special attention to Latent Consistency Models (LCMs), which distill LDMs into fast generators. We leverage our framework to propose LAtent consisTency INverse sOlver (LATINO), the first zero-shot PnP framework to solve inverse problems with priors encoded by LCMs. Our conditioning mechanism avoids automatic differentiation and reaches SOTA quality in as little as 8 neural function evaluations. As a result, LATINO delivers remarkably accurate solutions and is significantly more memory and computationally efficient than previous approaches. We then embed LATINO within an empirical Bayesian framework that automatically calibrates the text prompt from the observed measurements by marginal maximum likelihood estimation. Extensive experiments show that prompt self-calibration greatly improves estimation, allowing LATINO with PRompt Optimization to define new SOTAs in image reconstruction quality and computational efficiency.
Diffusion-based image inpainting with internal learning
Jun 06, 2024Diffusion models are now the undisputed state-of-the-art for image generation and image restoration. However, they require large amounts of computational power for training and inference. In this paper, we propose lightweight diffusion models for image inpainting that can be trained on a single image, or a few images. We show that our approach competes with large state-of-the-art models in specific cases. We also show that training a model on a single image is particularly relevant for image acquisition modality that differ from the RGB images of standard learning databases. We show results in three different contexts: texture images, line drawing images, and materials BRDF, for which we achieve state-of-the-art results in terms of realism, with a computational load that is greatly reduced compared to concurrent methods.
Infusion: Internal Diffusion for Video Inpainting
Nov 02, 2023Video inpainting is the task of filling a desired region in a video in a visually convincing manner. It is a very challenging task due to the high dimensionality of the signal and the temporal consistency required for obtaining convincing results. Recently, diffusion models have shown impressive results in modeling complex data distributions, including images and videos. Diffusion models remain nonetheless very expensive to train and perform inference with, which strongly restrict their application to video. We show that in the case of video inpainting, thanks to the highly auto-similar nature of videos, the training of a diffusion model can be restricted to the video to inpaint and still produce very satisfying results. This leads us to adopt an internal learning approch, which also allows for a greatly reduced network size. We call our approach "Infusion": an internal learning algorithm for video inpainting through diffusion. Due to our frugal network, we are able to propose the first video inpainting approach based purely on diffusion. Other methods require supporting elements such as optical flow estimation, which limits their performance in the case of dynamic textures for example. We introduce a new method for efficient training and inference of diffusion models in the context of internal learning. We split the diffusion process into different learning intervals which greatly simplifies the learning steps. We show qualititative and quantitative results, demonstrating that our method reaches state-of-the-art performance, in particular in the case of dynamic backgrounds and textures.
Plug-and-Play Posterior Sampling under Mismatched Measurement and Prior Models
Oct 05, 2023



Posterior sampling has been shown to be a powerful Bayesian approach for solving imaging inverse problems. The recent plug-and-play unadjusted Langevin algorithm (PnP-ULA) has emerged as a promising method for Monte Carlo sampling and minimum mean squared error (MMSE) estimation by combining physical measurement models with deep-learning priors specified using image denoisers. However, the intricate relationship between the sampling distribution of PnP-ULA and the mismatched data-fidelity and denoiser has not been theoretically analyzed. We address this gap by proposing a posterior-L2 pseudometric and using it to quantify an explicit error bound for PnP-ULA under mismatched posterior distribution. We numerically validate our theory on several inverse problems such as sampling from Gaussian mixture models and image deblurring. Our results suggest that the sensitivity of the sampling distribution of PnP-ULA to a mismatch in the measurement model and the denoiser can be precisely characterized.
Fast Diffusion EM: a diffusion model for blind inverse problems with application to deconvolution
Sep 01, 2023Using diffusion models to solve inverse problems is a growing field of research. Current methods assume the degradation to be known and provide impressive results in terms of restoration quality and diversity. In this work, we leverage the efficiency of those models to jointly estimate the restored image and unknown parameters of the degradation model. In particular, we designed an algorithm based on the well-known Expectation-Minimization (EM) estimation method and diffusion models. Our method alternates between approximating the expected log-likelihood of the inverse problem using samples drawn from a diffusion model and a maximization step to estimate unknown model parameters. For the maximization step, we also introduce a novel blur kernel regularization based on a Plug \& Play denoiser. Diffusion models are long to run, thus we provide a fast version of our algorithm. Extensive experiments on blind image deblurring demonstrate the effectiveness of our method when compared to other state-of-the-art approaches.
Inverse problem regularization with hierarchical variational autoencoders
Mar 20, 2023In this paper, we propose to regularize ill-posed inverse problems using a deep hierarchical variational autoencoder (HVAE) as an image prior. The proposed method synthesizes the advantages of i) denoiser-based Plug \& Play approaches and ii) generative model based approaches to inverse problems. First, we exploit VAE properties to design an efficient algorithm that benefits from convergence guarantees of Plug-and-Play (PnP) methods. Second, our approach is not restricted to specialized datasets and the proposed PnP-HVAE model is able to solve image restoration problems on natural images of any size. Our experiments show that the proposed PnP-HVAE method is competitive with both SOTA denoiser-based PnP approaches, and other SOTA restoration methods based on generative models.
Provably Convergent Plug & Play Linearized ADMM, applied to Deblurring Spatially Varying Kernels
Oct 19, 2022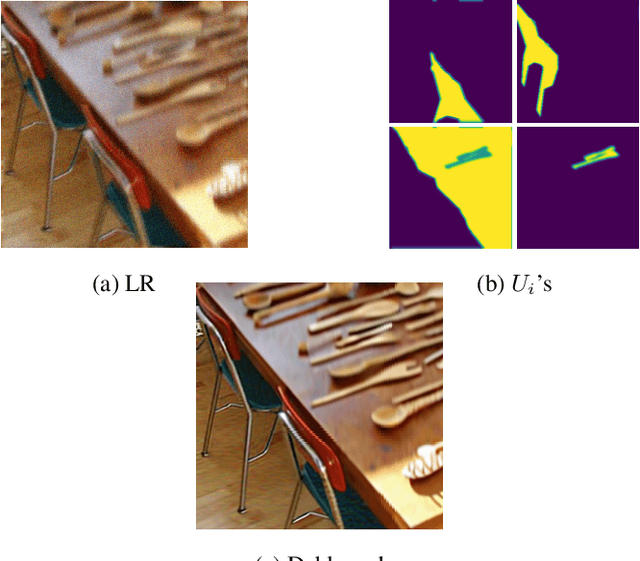
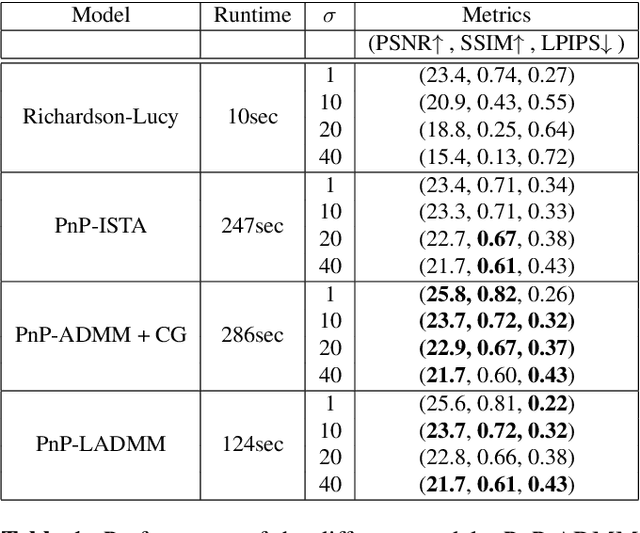
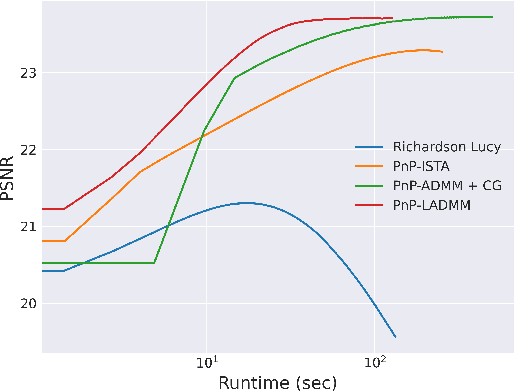
Plug & Play methods combine proximal algorithms with denoiser priors to solve inverse problems. These methods rely on the computability of the proximal operator of the data fidelity term. In this paper, we propose a Plug & Play framework based on linearized ADMM that allows us to bypass the computation of intractable proximal operators. We demonstrate the convergence of the algorithm and provide results on restoration tasks such as super-resolution and deblurring with non-uniform blur.
Video Restoration with a Deep Plug-and-Play Prior
Sep 15, 2022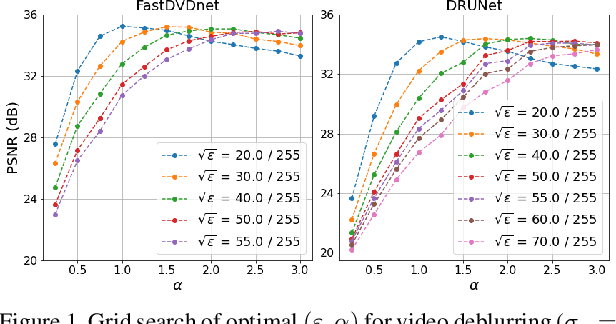

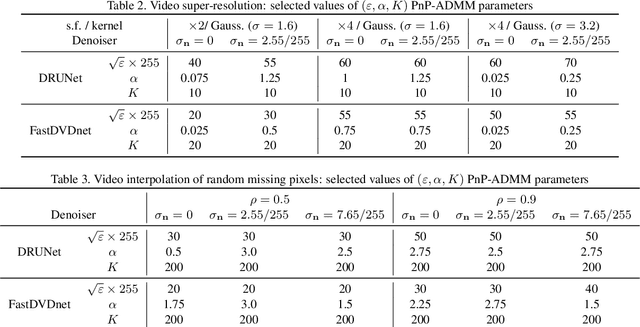
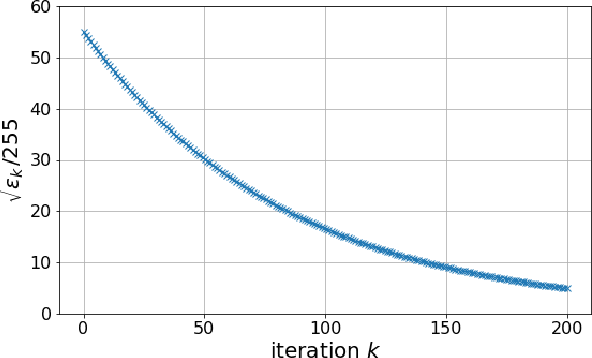
This paper presents a novel method for restoring digital videos via a Deep Plug-and-Play (PnP) approach. Under a Bayesian formalism, the method consists in using a deep convolutional denoising network in place of the proximal operator of the prior in an alternating optimization scheme. We distinguish ourselves from prior PnP work by directly applying that method to restore a digital video from a degraded video observation. This way, a network trained once for denoising can be repurposed for other video restoration tasks. Our experiments in video deblurring, super-resolution, and interpolation of random missing pixels all show a clear benefit to using a network specifically designed for video denoising, as it yields better restoration performance and better temporal stability than a single image network with similar denoising performance using the same PnP formulation. Moreover, our method compares favorably to applying a different state-of-the-art PnP scheme separately on each frame of the sequence. This opens new perspectives in the field of video restoration.
Diverse super-resolution with pretrained deep hiererarchical VAEs
May 20, 2022


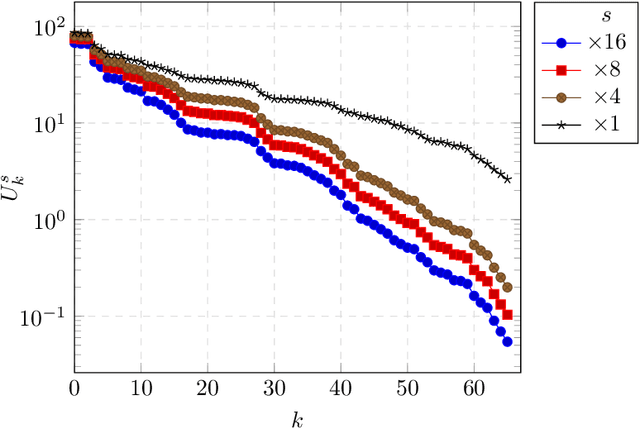
Image super-resolution is a one-to-many problem, but most deep-learning based methods only provide one single solution to this problem. In this work, we tackle the problem of diverse super-resolution by reusing VD-VAE, a state-of-the art variational autoencoder (VAE). We find that the hierarchical latent representation learned by VD-VAE naturally separates the image low-frequency information, encoded in the latent groups at the top of the hierarchy, from the image high-frequency details, determined by the latent groups at the bottom of the latent hierarchy. Starting from this observation, we design a super-resolution model exploiting the specific structure of VD-VAE latent space. Specifically, we train an encoder to encode low-resolution images in the subset of VD-VAE latent space encoding the low-frequency information, and we combine this encoder with VD-VAE generative model to sample diverse super-resolved version of a low-resolution input. We demonstrate the ability of our method to generate diverse solutions to the super-resolution problem on face super-resolution with upsampling factors x4, x8, and x16.