 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLATINO-PRO: LAtent consisTency INverse sOlver with PRompt Optimization
Mar 16, 2025Text-to-image latent diffusion models (LDMs) have recently emerged as powerful generative models with great potential for solving inverse problems in imaging. However, leveraging such models in a Plug & Play (PnP), zero-shot manner remains challenging because it requires identifying a suitable text prompt for the unknown image of interest. Also, existing text-to-image PnP approaches are highly computationally expensive. We herein address these challenges by proposing a novel PnP inference paradigm specifically designed for embedding generative models within stochastic inverse solvers, with special attention to Latent Consistency Models (LCMs), which distill LDMs into fast generators. We leverage our framework to propose LAtent consisTency INverse sOlver (LATINO), the first zero-shot PnP framework to solve inverse problems with priors encoded by LCMs. Our conditioning mechanism avoids automatic differentiation and reaches SOTA quality in as little as 8 neural function evaluations. As a result, LATINO delivers remarkably accurate solutions and is significantly more memory and computationally efficient than previous approaches. We then embed LATINO within an empirical Bayesian framework that automatically calibrates the text prompt from the observed measurements by marginal maximum likelihood estimation. Extensive experiments show that prompt self-calibration greatly improves estimation, allowing LATINO with PRompt Optimization to define new SOTAs in image reconstruction quality and computational efficiency.
Plug-and-Play image restoration with Stochastic deNOising REgularization
Feb 01, 2024Plug-and-Play (PnP) algorithms are a class of iterative algorithms that address image inverse problems by combining a physical model and a deep neural network for regularization. Even if they produce impressive image restoration results, these algorithms rely on a non-standard use of a denoiser on images that are less and less noisy along the iterations, which contrasts with recent algorithms based on Diffusion Models (DM), where the denoiser is applied only on re-noised images. We propose a new PnP framework, called Stochastic deNOising REgularization (SNORE), which applies the denoiser only on images with noise of the adequate level. It is based on an explicit stochastic regularization, which leads to a stochastic gradient descent algorithm to solve ill-posed inverse problems. A convergence analysis of this algorithm and its annealing extension is provided. Experimentally, we prove that SNORE is competitive with respect to state-of-the-art methods on deblurring and inpainting tasks, both quantitatively and qualitatively.
Inverse problem regularization with hierarchical variational autoencoders
Mar 20, 2023In this paper, we propose to regularize ill-posed inverse problems using a deep hierarchical variational autoencoder (HVAE) as an image prior. The proposed method synthesizes the advantages of i) denoiser-based Plug \& Play approaches and ii) generative model based approaches to inverse problems. First, we exploit VAE properties to design an efficient algorithm that benefits from convergence guarantees of Plug-and-Play (PnP) methods. Second, our approach is not restricted to specialized datasets and the proposed PnP-HVAE model is able to solve image restoration problems on natural images of any size. Our experiments show that the proposed PnP-HVAE method is competitive with both SOTA denoiser-based PnP approaches, and other SOTA restoration methods based on generative models.
SCOTCH and SODA: A Transformer Video Shadow Detection Framework
Nov 13, 2022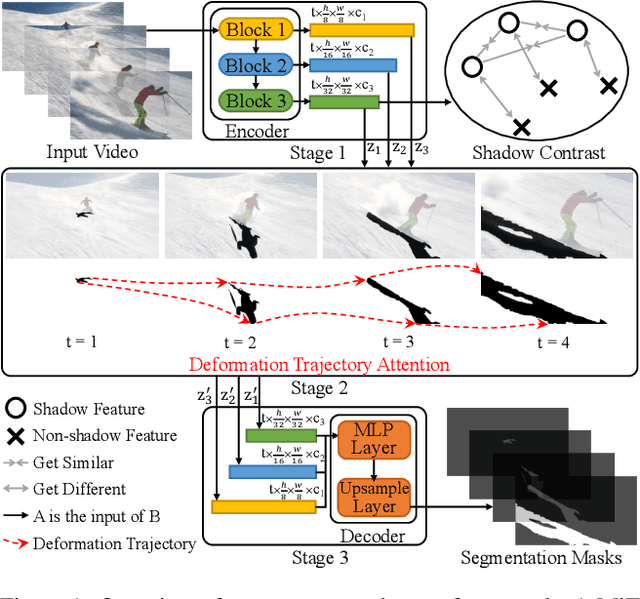
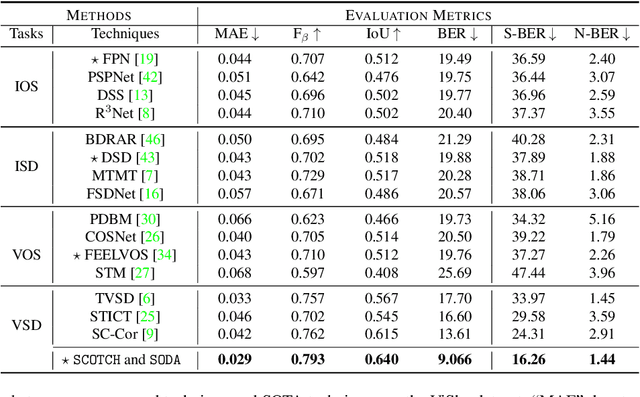
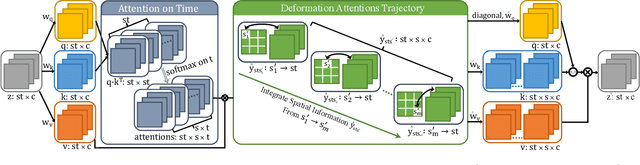
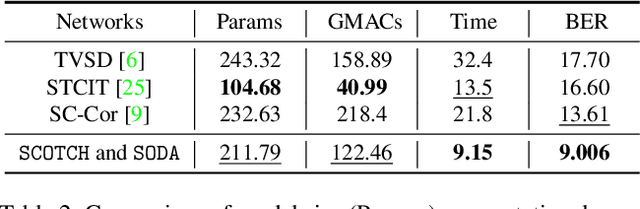
Shadows in videos are difficult to detect because of the large shadow deformation between frames. In this work, we argue that accounting for the shadow deformation is essential when designing a video shadow detection method. To this end, we introduce the shadow deformation attention trajectory (SODA), a new type of video self-attention module, specially designed to handle the large shadow deformations in videos. Moreover, we present a shadow contrastive learning mechanism (SCOTCH) which aims at guiding the network to learn a high-level representation of shadows, unified across different videos. We demonstrate empirically the effectiveness of our two contributions in an ablation study. Furthermore, we show that SCOTCH and SODA significantly outperforms existing techniques for video shadow detection. Code will be available upon the acceptance of this work.
Diverse super-resolution with pretrained deep hiererarchical VAEs
May 20, 2022


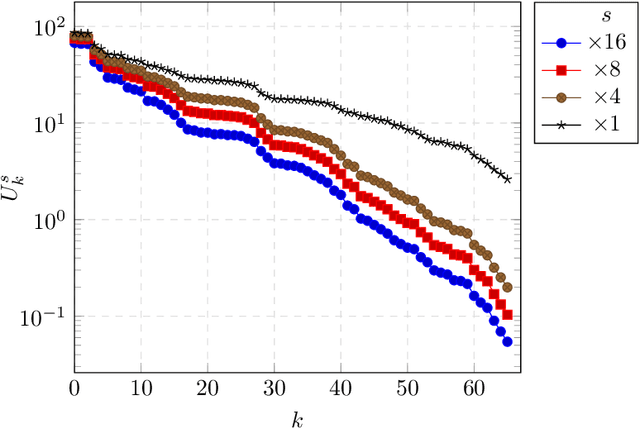
Image super-resolution is a one-to-many problem, but most deep-learning based methods only provide one single solution to this problem. In this work, we tackle the problem of diverse super-resolution by reusing VD-VAE, a state-of-the art variational autoencoder (VAE). We find that the hierarchical latent representation learned by VD-VAE naturally separates the image low-frequency information, encoded in the latent groups at the top of the hierarchy, from the image high-frequency details, determined by the latent groups at the bottom of the latent hierarchy. Starting from this observation, we design a super-resolution model exploiting the specific structure of VD-VAE latent space. Specifically, we train an encoder to encode low-resolution images in the subset of VD-VAE latent space encoding the low-frequency information, and we combine this encoder with VD-VAE generative model to sample diverse super-resolved version of a low-resolution input. We demonstrate the ability of our method to generate diverse solutions to the super-resolution problem on face super-resolution with upsampling factors x4, x8, and x16.
Learning local regularization for variational image restoration
Feb 11, 2021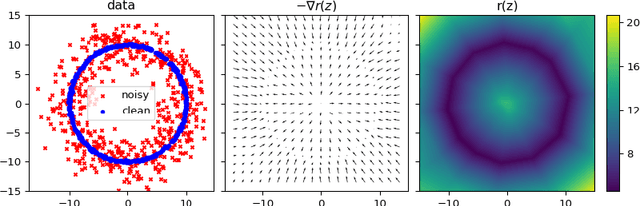

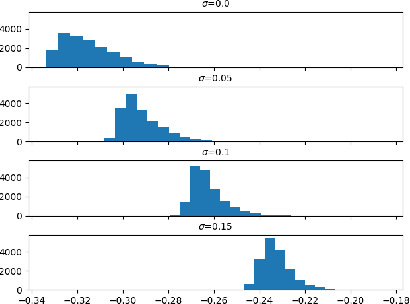

In this work, we propose a framework to learn a local regularization model for solving general image restoration problems. This regularizer is defined with a fully convolutional neural network that sees the image through a receptive field corresponding to small image patches. The regularizer is then learned as a critic between unpaired distributions of clean and degraded patches using a Wasserstein generative adversarial networks based energy. This yields a regularization function that can be incorporated in any image restoration problem. The efficiency of the framework is finally shown on denoising and deblurring applications.