 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-based image inpainting with internal learning
Jun 06, 2024Diffusion models are now the undisputed state-of-the-art for image generation and image restoration. However, they require large amounts of computational power for training and inference. In this paper, we propose lightweight diffusion models for image inpainting that can be trained on a single image, or a few images. We show that our approach competes with large state-of-the-art models in specific cases. We also show that training a model on a single image is particularly relevant for image acquisition modality that differ from the RGB images of standard learning databases. We show results in three different contexts: texture images, line drawing images, and materials BRDF, for which we achieve state-of-the-art results in terms of realism, with a computational load that is greatly reduced compared to concurrent methods.
Infusion: Internal Diffusion for Video Inpainting
Nov 02, 2023Video inpainting is the task of filling a desired region in a video in a visually convincing manner. It is a very challenging task due to the high dimensionality of the signal and the temporal consistency required for obtaining convincing results. Recently, diffusion models have shown impressive results in modeling complex data distributions, including images and videos. Diffusion models remain nonetheless very expensive to train and perform inference with, which strongly restrict their application to video. We show that in the case of video inpainting, thanks to the highly auto-similar nature of videos, the training of a diffusion model can be restricted to the video to inpaint and still produce very satisfying results. This leads us to adopt an internal learning approch, which also allows for a greatly reduced network size. We call our approach "Infusion": an internal learning algorithm for video inpainting through diffusion. Due to our frugal network, we are able to propose the first video inpainting approach based purely on diffusion. Other methods require supporting elements such as optical flow estimation, which limits their performance in the case of dynamic textures for example. We introduce a new method for efficient training and inference of diffusion models in the context of internal learning. We split the diffusion process into different learning intervals which greatly simplifies the learning steps. We show qualititative and quantitative results, demonstrating that our method reaches state-of-the-art performance, in particular in the case of dynamic backgrounds and textures.
Patch-Based Stochastic Attention for Image Editing
Feb 07, 2022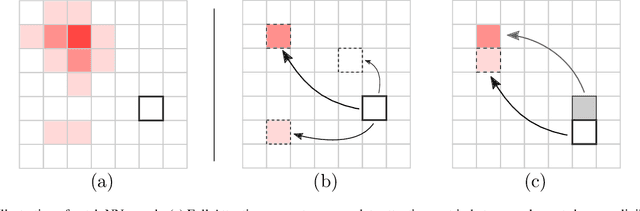



Attention mechanisms have become of crucial importance in deep learning in recent years. These non-local operations, which are similar to traditional patch-based methods in image processing, complement local convolutions. However, computing the full attention matrix is an expensive step with a heavy memory and computational load. These limitations curb network architectures and performances, in particular for the case of high resolution images. We propose an efficient attention layer based on the stochastic algorithm PatchMatch, which is used for determining approximate nearest neighbors. We refer to our proposed layer as a "Patch-based Stochastic Attention Layer" (PSAL). Furthermore, we propose different approaches, based on patch aggregation, to ensure the differentiability of PSAL, thus allowing end-to-end training of any network containing our layer. PSAL has a small memory footprint and can therefore scale to high resolution images. It maintains this footprint without sacrificing spatial precision and globality of the nearest neighbours, which means that it can be easily inserted in any level of a deep architecture, even in shallower levels. We demonstrate the usefulness of PSAL on several image editing tasks, such as image inpainting and image colorization.