 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint reconstruction-segmentation on graphs
Aug 11, 2022
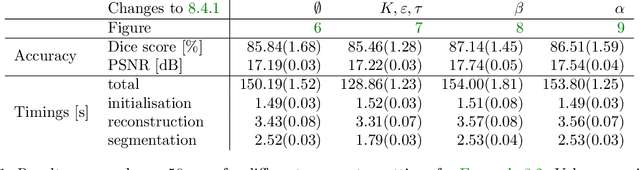

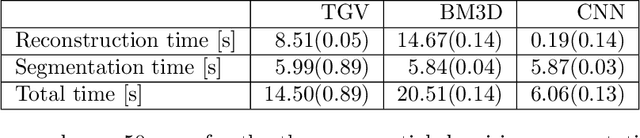
Practical image segmentation tasks concern images which must be reconstructed from noisy, distorted, and/or incomplete observations. A recent approach for solving such tasks is to perform this reconstruction jointly with the segmentation, using each to guide the other. However, this work has so far employed relatively simple segmentation methods, such as the Chan--Vese algorithm. In this paper, we present a method for joint reconstruction-segmentation using graph-based segmentation methods, which have been seeing increasing recent interest. Complications arise due to the large size of the matrices involved, and we show how these complications can be managed. We then analyse the convergence properties of our scheme. Finally, we apply this scheme to distorted versions of ``two cows'' images familiar from previous graph-based segmentation literature, first to a highly noised version and second to a blurred version, achieving highly accurate segmentations in both cases. We compare these results to those obtained by sequential reconstruction-segmentation approaches, finding that our method competes with, or even outperforms, those approaches in terms of reconstruction and segmentation accuracy.
An Analysis of Generative Methods for Multiple Image Inpainting
May 04, 2022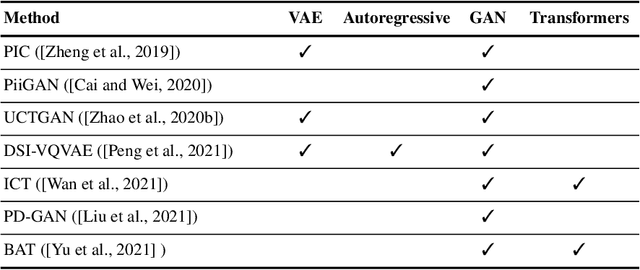
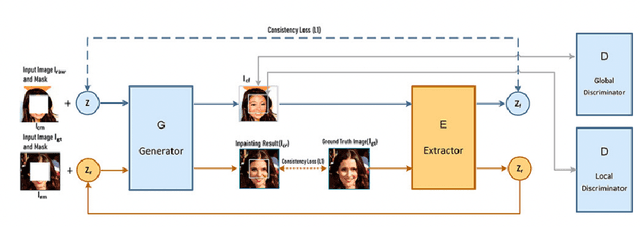
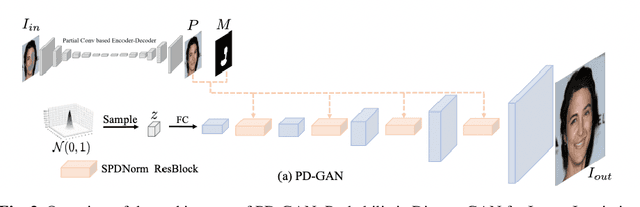
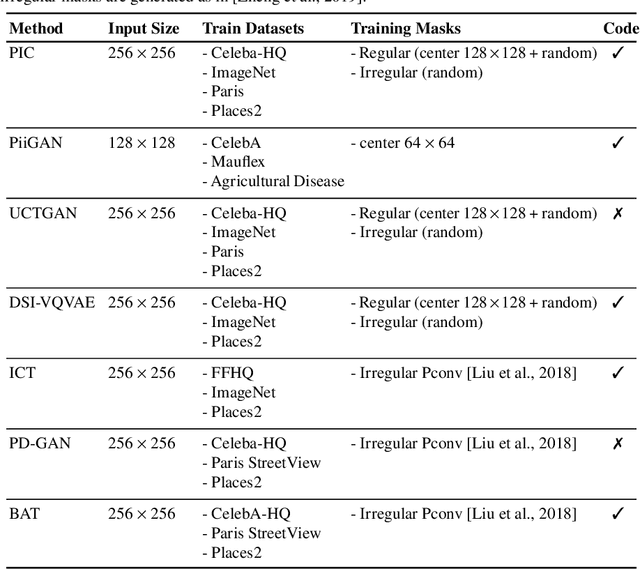
Image inpainting refers to the restoration of an image with missing regions in a way that is not detectable by the observer. The inpainting regions can be of any size and shape. This is an ill-posed inverse problem that does not have a unique solution. In this work, we focus on learning-based image completion methods for multiple and diverse inpainting which goal is to provide a set of distinct solutions for a given damaged image. These methods capitalize on the probabilistic nature of certain generative models to sample various solutions that coherently restore the missing content. Along the chapter, we will analyze the underlying theory and analyze the recent proposals for multiple inpainting. To investigate the pros and cons of each method, we present quantitative and qualitative comparisons, on common datasets, regarding both the quality and the diversity of the set of inpainted solutions. Our analysis allows us to identify the most successful generative strategies in both inpainting quality and inpainting diversity. This task is closely related to the learning of an accurate probability distribution of images. Depending on the dataset in use, the challenges that entail the training of such a model will be discussed through the analysis.
Unsupervised Clustering of Roman Potsherds via Variational Autoencoders
Mar 14, 2022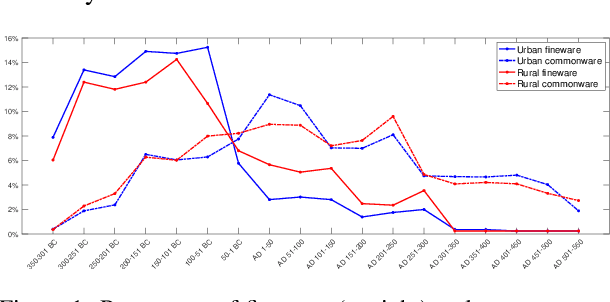
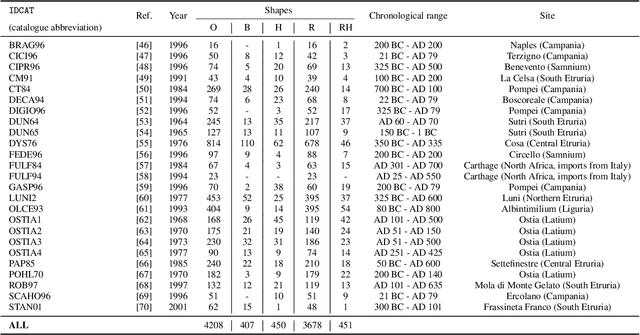
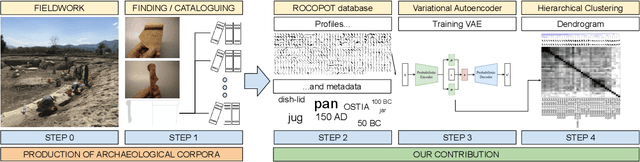
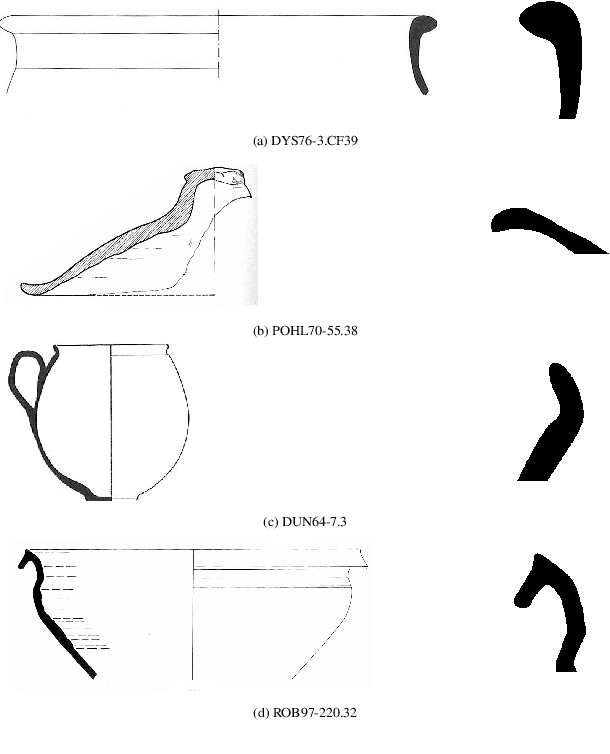
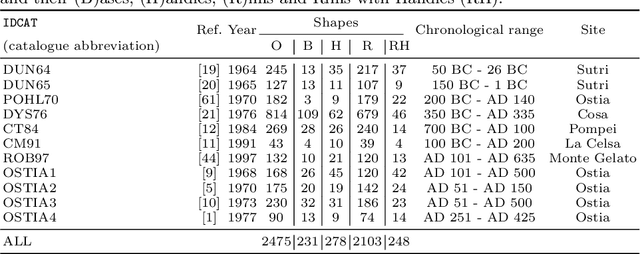
In this paper we propose an artificial intelligence imaging solution to support archaeologists in the classification task of Roman commonware potsherds. Usually, each potsherd is represented by its sectional profile as a two dimensional black-white image and printed in archaeological books related to specific archaeological excavations. The partiality and handcrafted variance of the fragments make their matching a challenging problem: we propose to pair similar profiles via the unsupervised hierarchical clustering of non-linear features learned in the latent space of a deep convolutional Variational Autoencoder (VAE) network. Our contribution also include the creation of a ROman COmmonware POTtery (ROCOPOT) database, with more than 4000 potsherds profiles extracted from 25 Roman pottery corpora, and a MATLAB GUI software for the easy inspection of shape similarities. Results are commented both from a mathematical and archaeological perspective so as to unlock new research directions in both communities.
Unsupervised clustering of Roman pottery profiles from their SSAE representation
Jun 04, 2020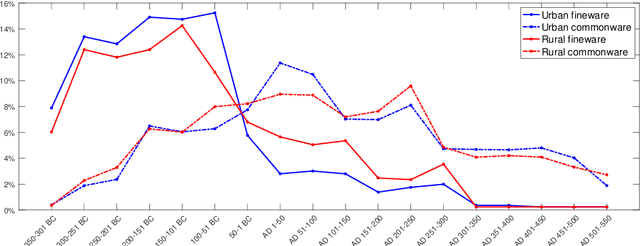
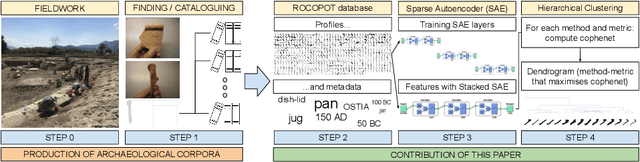

In this paper we introduce the ROman COmmonware POTtery (ROCOPOT) database, which comprises of more than 2000 black and white imaging profiles of pottery shapes extracted from 11 Roman catalogues and related to different excavation sites. The partiality and the handcrafted variance of the shape fragments within this new database make their unsupervised clustering a very challenging problem: profile similarities are thus explored via the hierarchical clustering of non-linear features learned in the latent representation space of a stacked sparse autoencoder (SSAE) network, unveiling new profile matches. Results are commented both from a mathematical and archaeological perspective so as to unlock new research directions in the respective communities.
Variational Osmosis for Non-linear Image Fusion
Oct 04, 2019



We propose a new variational model for nonlinear image fusion. Our approach incorporates the osmosis model proposed in Vogel et al. (2013) and Weickert et al. (2013) as an energy term in a variational model. The osmosis energy is known to realize visually plausible image data fusion. As a consequence, our method is invariant to multiplicative brightness changes. On the practical side, it requires minimal supervision and parameter tuning and can encode prior information on the structure of the images to be fused. We develop a primal-dual algorithm for solving this new image fusion model and we apply the resulting minimisation scheme to multi-modal image fusion for face fusion, colour transfer and some cultural heritage conservation challenges. Visual comparison to state-of-the-art proves the quality and flexibility of our method.
Unveiling the invisible - mathematical methods for restoring and interpreting illuminated manuscripts
Mar 19, 2018
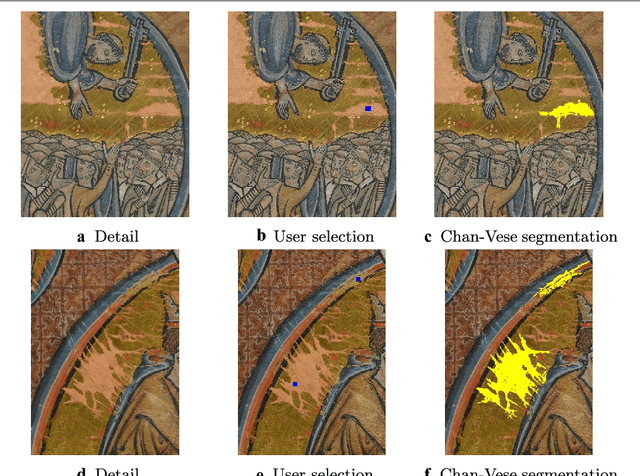


The last fifty years have seen an impressive development of mathematical methods for the analysis and processing of digital images, mostly in the context of photography, biomedical imaging and various forms of engineering. The arts have been mostly overlooked in this process, apart from a few exceptional works in the last ten years. With the rapid emergence of digitisation in the arts, however, the arts domain is becoming increasingly receptive to digital image processing methods and the importance of paying attention to this therefore increases. In this paper we discuss a range of mathematical methods for digital image restoration and digital visualisation for illuminated manuscripts. The latter provide an interesting opportunity for digital manipulation because they traditionally remain physically untouched. At the same time they also serve as an example for the possibilities mathematics and digital restoration offer as a generic and objective toolkit for the arts.