 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Image Inpainting Through Improved Wasserstein Generative Adversarial Networks
Paper and Code
Dec 03, 2018
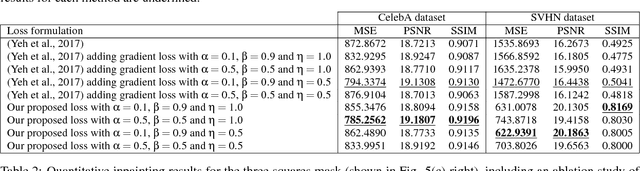

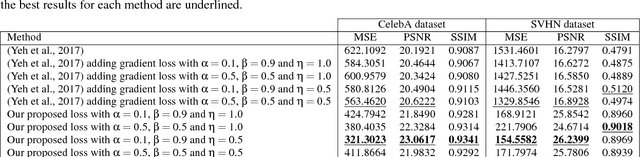
Image inpainting is the task of filling-in missing regions of a damaged or incomplete image. In this work we tackle this problem not only by using the available visual data but also by incorporating image semantics through the use of generative models. Our contribution is twofold: First, we learn a data latent space by training an improved version of the Wasserstein generative adversarial network, for which we incorporate a new generator and discriminator architecture. Second, the learned semantic information is combined with a new optimization loss for inpainting whose minimization infers the missing content conditioned by the available data. It takes into account powerful contextual and perceptual content inherent in the image itself. The benefits include the ability to recover large regions by accumulating semantic information even it is not fully present in the damaged image. Experiments show that the presented method obtains qualitative and quantitative top-tier results in different experimental situations and also achieves accurate photo-realism comparable to state-of-the-art works.