 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Multiple Hypotheses in Coarse-to-Fine Dense Image Matching
Sep 10, 2025Dense image matching aims to find a correspondent for every pixel of a source image in a partially overlapping target image. State-of-the-art methods typically rely on a coarse-to-fine mechanism where a single correspondent hypothesis is produced per source location at each scale. In challenging cases -- such as at depth discontinuities or when the target image is a strong zoom-in of the source image -- the correspondents of neighboring source locations are often widely spread and predicting a single correspondent hypothesis per source location at each scale may lead to erroneous matches. In this paper, we investigate the idea of predicting multiple correspondent hypotheses per source location at each scale instead. We consider a beam search strategy to propagat multiple hypotheses at each scale and propose integrating these multiple hypotheses into cross-attention layers, resulting in a novel dense matching architecture called BEAMER. BEAMER learns to preserve and propagate multiple hypotheses across scales, making it significantly more robust than state-of-the-art methods, especially at depth discontinuities or when the target image is a strong zoom-in of the source image.
Alligat0R: Pre-Training Through Co-Visibility Segmentation for Relative Camera Pose Regression
Mar 10, 2025
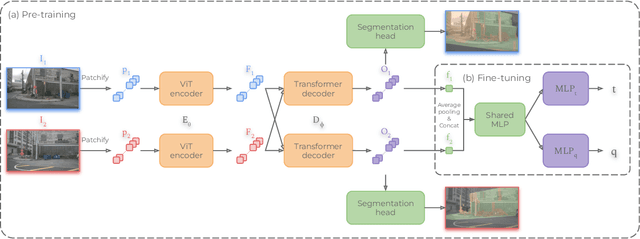


Pre-training techniques have greatly advanced computer vision, with CroCo's cross-view completion approach yielding impressive results in tasks like 3D reconstruction and pose regression. However, this method requires substantial overlap between training pairs, limiting its effectiveness. We introduce Alligat0R, a novel pre-training approach that reformulates cross-view learning as a co-visibility segmentation task. Our method predicts whether each pixel in one image is co-visible in the second image, occluded, or outside the field of view (FOV), enabling the use of image pairs with any degree of overlap and providing interpretable predictions. To support this, we present Cub3, a large-scale dataset with 2.5 million image pairs and dense co-visibility annotations derived from the nuScenes dataset. This dataset includes diverse scenarios with varying degrees of overlap. The experiments show that Alligat0R significantly outperforms CroCo in relative pose regression, especially in scenarios with limited overlap. Alligat0R and Cub3 will be made publicly available.
RUBIK: A Structured Benchmark for Image Matching across Geometric Challenges
Feb 27, 2025Camera pose estimation is crucial for many computer vision applications, yet existing benchmarks offer limited insight into method limitations across different geometric challenges. We introduce RUBIK, a novel benchmark that systematically evaluates image matching methods across well-defined geometric difficulty levels. Using three complementary criteria - overlap, scale ratio, and viewpoint angle - we organize 16.5K image pairs from nuScenes into 33 difficulty levels. Our comprehensive evaluation of 14 methods reveals that while recent detector-free approaches achieve the best performance (>47% success rate), they come with significant computational overhead compared to detector-based methods (150-600ms vs. 40-70ms). Even the best performing method succeeds on only 54.8% of the pairs, highlighting substantial room for improvement, particularly in challenging scenarios combining low overlap, large scale differences, and extreme viewpoint changes. Benchmark will be made publicly available.
Are Semi-Dense Detector-Free Methods Good at Matching Local Features?
Feb 13, 2024



Semi-dense detector-free approaches (SDF), such as LoFTR, are currently among the most popular image matching methods. While SDF methods are trained to establish correspondences between two images, their performances are almost exclusively evaluated using relative pose estimation metrics. Thus, the link between their ability to establish correspondences and the quality of the resulting estimated pose has thus far received little attention. This paper is a first attempt to study this link. We start with proposing a novel structured attention-based image matching architecture (SAM). It allows us to show a counter-intuitive result on two datasets (MegaDepth and HPatches): on the one hand SAM either outperforms or is on par with SDF methods in terms of pose/homography estimation metrics, but on the other hand SDF approaches are significantly better than SAM in terms of matching accuracy. We then propose to limit the computation of the matching accuracy to textured regions, and show that in this case SAM often surpasses SDF methods. Our findings highlight a strong correlation between the ability to establish accurate correspondences in textured regions and the accuracy of the resulting estimated pose/homography. Our code will be made available.
Visual Correspondence Hallucination: Towards Geometric Reasoning
Jun 17, 2021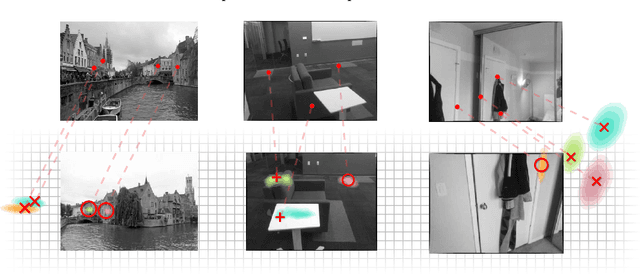
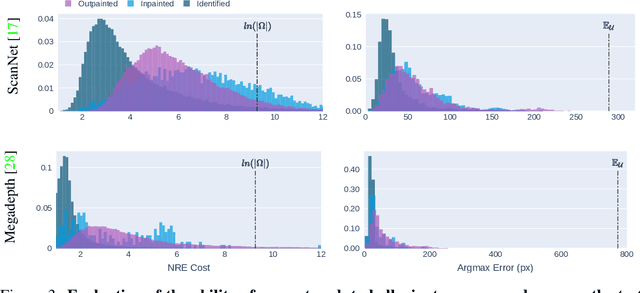
Given a pair of partially overlapping source and target images and a keypoint in the source image, the keypoint's correspondent in the target image can be either visible, occluded or outside the field of view. Local feature matching methods are only able to identify the correspondent's location when it is visible, while humans can also hallucinate its location when it is occluded or outside the field of view through geometric reasoning. In this paper, we bridge this gap by training a network to output a peaked probability distribution over the correspondent's location, regardless of this correspondent being visible, occluded, or outside the field of view. We experimentally demonstrate that this network is indeed able to hallucinate correspondences on unseen pairs of images. We also apply this network to a camera pose estimation problem and find it is significantly more robust than state-of-the-art local feature matching-based competitors.
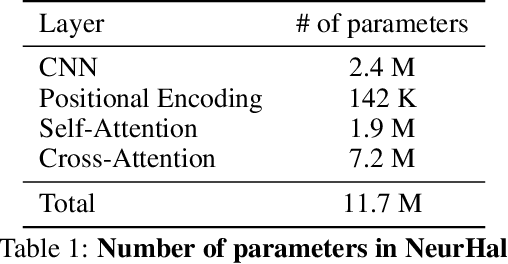
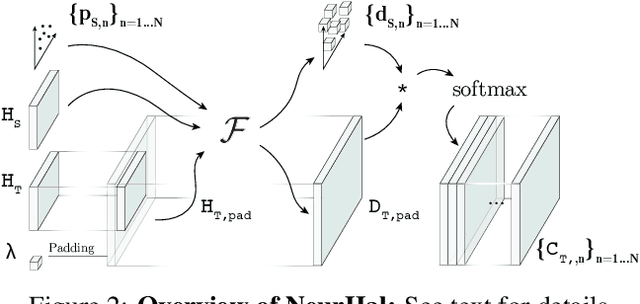
Neural Reprojection Error: Merging Feature Learning and Camera Pose Estimation
Mar 12, 2021
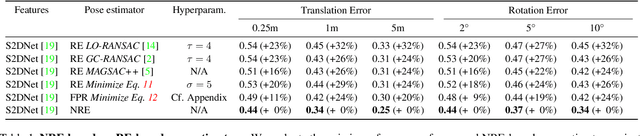

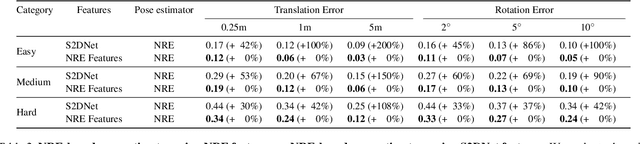
Absolute camera pose estimation is usually addressed by sequentially solving two distinct subproblems: First a feature matching problem that seeks to establish putative 2D-3D correspondences, and then a Perspective-n-Point problem that minimizes, with respect to the camera pose, the sum of so-called Reprojection Errors (RE). We argue that generating putative 2D-3D correspondences 1) leads to an important loss of information that needs to be compensated as far as possible, within RE, through the choice of a robust loss and the tuning of its hyperparameters and 2) may lead to an RE that conveys erroneous data to the pose estimator. In this paper, we introduce the Neural Reprojection Error (NRE) as a substitute for RE. NRE allows to rethink the camera pose estimation problem by merging it with the feature learning problem, hence leveraging richer information than 2D-3D correspondences and eliminating the need for choosing a robust loss and its hyperparameters. Thus NRE can be used as training loss to learn image descriptors tailored for pose estimation. We also propose a coarse-to-fine optimization method able to very efficiently minimize a sum of NRE terms with respect to the camera pose. We experimentally demonstrate that NRE is a good substitute for RE as it significantly improves both the robustness and the accuracy of the camera pose estimate while being computationally and memory highly efficient. From a broader point of view, we believe this new way of merging deep learning and 3D geometry may be useful in other computer vision applications.
S2DNet: Learning Accurate Correspondences for Sparse-to-Dense Feature Matching
Apr 03, 2020
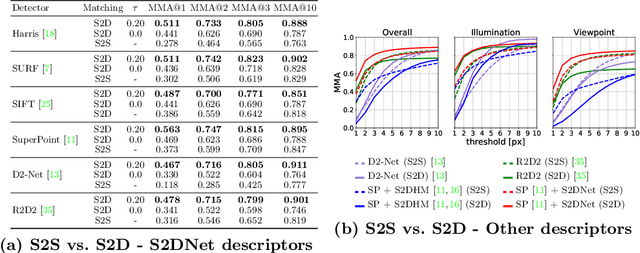
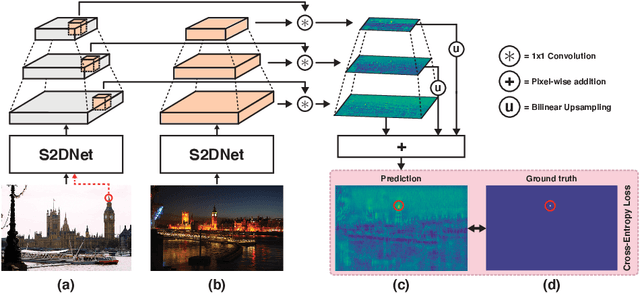
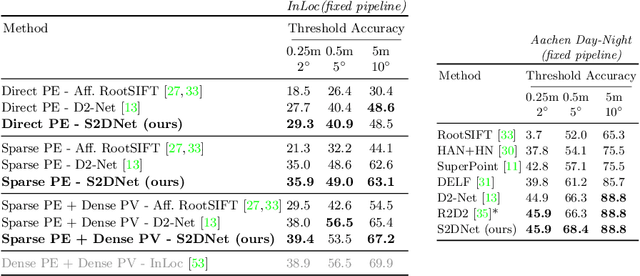
Establishing robust and accurate correspondences is a fundamental backbone to many computer vision algorithms. While recent learning-based feature matching methods have shown promising results in providing robust correspondences under challenging conditions, they are often limited in terms of precision. In this paper, we introduce S2DNet, a novel feature matching pipeline, designed and trained to efficiently establish both robust and accurate correspondences. By leveraging a sparse-to-dense matching paradigm, we cast the correspondence learning problem as a supervised classification task to learn to output highly peaked correspondence maps. We show that S2DNet achieves state-of-the-art results on the HPatches benchmark, as well as on several long-term visual localization datasets.
Sparse-to-Dense Hypercolumn Matching for Long-Term Visual Localization
Aug 21, 2019
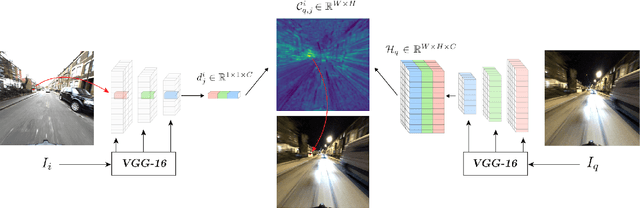
We propose a novel approach to feature point matching, suitable for robust and accurate outdoor visual localization in long-term scenarios. Given a query image, we first match it against a database of registered reference images, using recent retrieval techniques. This gives us a first estimate of the camera pose. To refine this estimate, like previous approaches, we match 2D points across the query image and the retrieved reference image. This step, however, is prone to fail as it is still very difficult to detect and match sparse feature points across images captured in potentially very different conditions. Our key contribution is to show that we need to extract sparse feature points only in the retrieved reference image: We then search for the corresponding 2D locations in the query image exhaustively. This search can be performed efficiently using convolutional operations, and robustly by using hypercolumn descriptors, i.e. image features computed for retrieval. We refer to this method as Sparse-to-Dense Hypercolumn Matching. Because we know the 3D locations of the sparse feature points in the reference images thanks to an offline reconstruction stage, it is then possible to accurately estimate the camera pose from these matches. Our experiments show that this method allows us to outperform the state-of-the-art on several challenging outdoor datasets.
Efficient Condition-based Representations for Long-Term Visual Localization
Dec 10, 2018
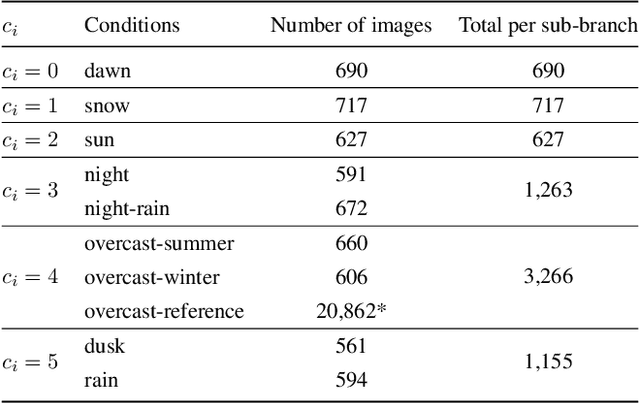
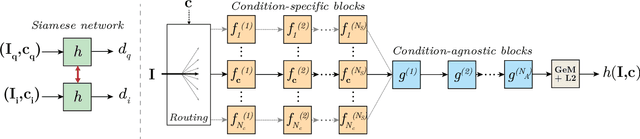
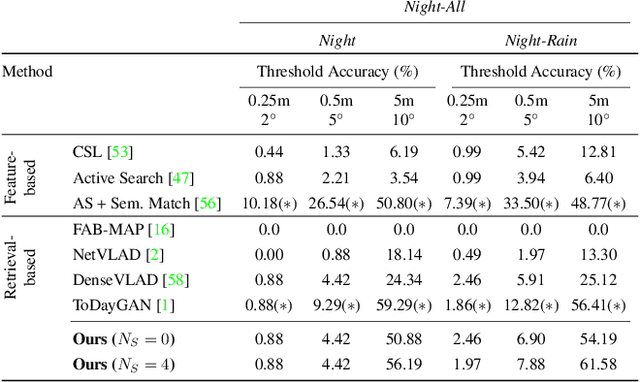
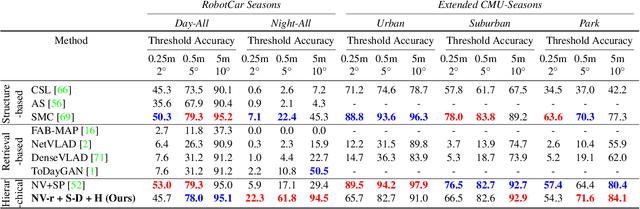
We propose an approach to localization from images that is designed to explicitly handle the strong variations in appearance happening when capturing conditions change throughout the day or across seasons. As revealed by recent long-term localization benchmarks, both traditional feature-based and retrieval-based approaches still struggle to handle such changes. Our novel retrieval-based method introduces condition-specific sub-networks allowing the computation of global image descriptors that are explicitly dependent of the capturing conditions. We compare our approach to previous localization methods on very recent challenging benchmarks, and observe that our method outperforms them by a large margin in case of day-night variation, where repeatable feature points cannot be identified or matched.
Egocentric vision IT technologies for Alzheimer disease assessment and studies
Mar 13, 2013


Egocentric vision technology consists in capturing the actions of persons from their own visual point of view using wearable camera sensors. We apply this new paradigm to instrumental activities monitoring with the objective of providing new tools for the clinical evaluation of the impact of the disease on persons with dementia. In this paper, we introduce the current state of the development of this technology and focus on two technology modules: automatic location estimation and visual saliency estimation for content interpretation.