 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlligat0R: Pre-Training Through Co-Visibility Segmentation for Relative Camera Pose Regression
Mar 10, 2025
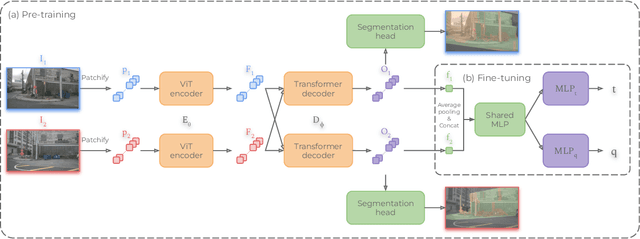


Pre-training techniques have greatly advanced computer vision, with CroCo's cross-view completion approach yielding impressive results in tasks like 3D reconstruction and pose regression. However, this method requires substantial overlap between training pairs, limiting its effectiveness. We introduce Alligat0R, a novel pre-training approach that reformulates cross-view learning as a co-visibility segmentation task. Our method predicts whether each pixel in one image is co-visible in the second image, occluded, or outside the field of view (FOV), enabling the use of image pairs with any degree of overlap and providing interpretable predictions. To support this, we present Cub3, a large-scale dataset with 2.5 million image pairs and dense co-visibility annotations derived from the nuScenes dataset. This dataset includes diverse scenarios with varying degrees of overlap. The experiments show that Alligat0R significantly outperforms CroCo in relative pose regression, especially in scenarios with limited overlap. Alligat0R and Cub3 will be made publicly available.
RUBIK: A Structured Benchmark for Image Matching across Geometric Challenges
Feb 27, 2025Camera pose estimation is crucial for many computer vision applications, yet existing benchmarks offer limited insight into method limitations across different geometric challenges. We introduce RUBIK, a novel benchmark that systematically evaluates image matching methods across well-defined geometric difficulty levels. Using three complementary criteria - overlap, scale ratio, and viewpoint angle - we organize 16.5K image pairs from nuScenes into 33 difficulty levels. Our comprehensive evaluation of 14 methods reveals that while recent detector-free approaches achieve the best performance (>47% success rate), they come with significant computational overhead compared to detector-based methods (150-600ms vs. 40-70ms). Even the best performing method succeeds on only 54.8% of the pairs, highlighting substantial room for improvement, particularly in challenging scenarios combining low overlap, large scale differences, and extreme viewpoint changes. Benchmark will be made publicly available.
Reliability in Semantic Segmentation: Can We Use Synthetic Data?
Dec 14, 2023
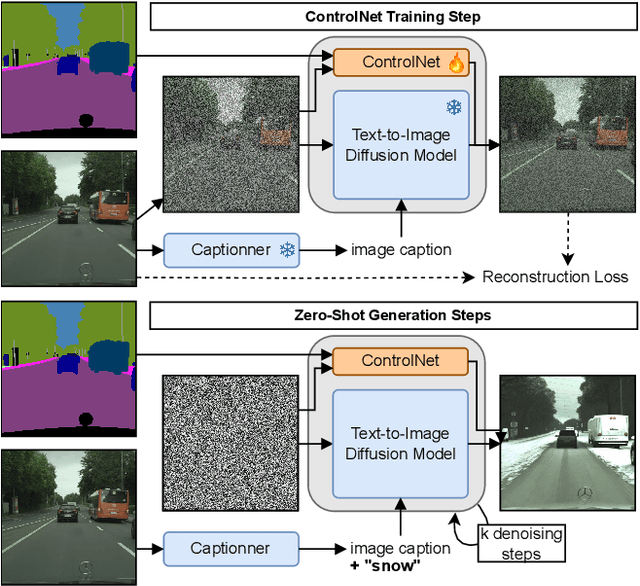
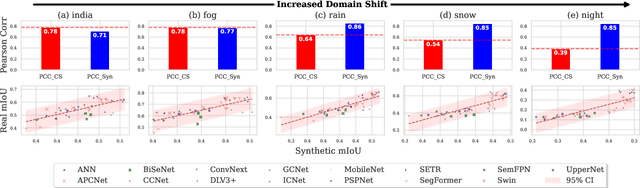
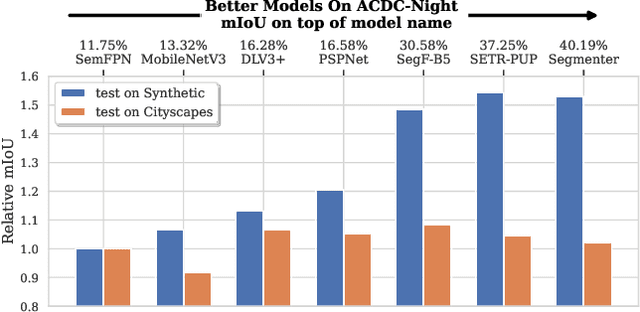
Assessing the reliability of perception models to covariate shifts and out-of-distribution (OOD) detection is crucial for safety-critical applications such as autonomous vehicles. By nature of the task, however, the relevant data is difficult to collect and annotate. In this paper, we challenge cutting-edge generative models to automatically synthesize data for assessing reliability in semantic segmentation. By fine-tuning Stable Diffusion, we perform zero-shot generation of synthetic data in OOD domains or inpainted with OOD objects. Synthetic data is employed to provide an initial assessment of pretrained segmenters, thereby offering insights into their performance when confronted with real edge cases. Through extensive experiments, we demonstrate a high correlation between the performance on synthetic data and the performance on real OOD data, showing the validity approach. Furthermore, we illustrate how synthetic data can be utilized to enhance the calibration and OOD detection capabilities of segmenters.