 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocating Demographic Bias at the Attention-Head Level in CLIP's Vision Encoder
Mar 12, 2026Standard fairness audits of foundation models quantify that a model is biased, but not where inside the network the bias resides. We propose a mechanistic fairness audit that combines projected residual-stream decomposition, zero-shot Concept Activation Vectors, and bias-augmented TextSpan analysis to locate demographic bias at the level of individual attention heads in vision transformers. As a feasibility case study, we apply this pipeline to the CLIP ViT-L-14 encoder on 42 profession classes of the FACET benchmark, auditing both gender and age bias. For gender, the pipeline identifies four terminal-layer heads whose ablation reduces global bias (Cramer's V: 0.381 -> 0.362) while marginally improving accuracy (+0.42%); a layer-matched random control confirms that this effect is specific to the identified heads. A single head in the final layer contributes to the majority of the reduction in the most stereotyped classes, and class-level analysis shows that corrected predictions shift toward the correct occupation. For age, the same pipeline identifies candidate heads, but ablation produces weaker and less consistent effects, suggesting that age bias is encoded more diffusely than gender bias in this model. These results provide preliminary evidence that head-level bias localisation is feasible for discriminative vision encoders and that the degree of localisability may vary across protected attributes. keywords: Bias . CLIP . Mechanistic Interpretability . Vision Transformer . Fairness
Mean Opinion Score as a New Metric for User-Evaluation of XAI Methods
Jul 29, 2024This paper investigates the use of Mean Opinion Score (MOS), a common image quality metric, as a user-centric evaluation metric for XAI post-hoc explainers. To measure the MOS, a user experiment is proposed, which has been conducted with explanation maps of intentionally distorted images. Three methods from the family of feature attribution methods - Gradient-weighted Class Activation Mapping (Grad-CAM), Multi-Layered Feature Explanation Method (MLFEM), and Feature Explanation Method (FEM) - are compared with this metric. Additionally, the correlation of this new user-centric metric with automatic metrics is studied via Spearman's rank correlation coefficient. MOS of MLFEM shows the highest correlation with automatic metrics of Insertion Area Under Curve (IAUC) and Deletion Area Under Curve (DAUC). However, the overall correlations are limited, which highlights the lack of consensus between automatic and user-centric metrics.
Sport Task: Fine Grained Action Detection and Classification of Table Tennis Strokes from Videos for MediaEval 2022
Jan 31, 2023
Sports video analysis is a widespread research topic. Its applications are very diverse, like events detection during a match, video summary, or fine-grained movement analysis of athletes. As part of the MediaEval 2022 benchmarking initiative, this task aims at detecting and classifying subtle movements from sport videos. We focus on recordings of table tennis matches. Conducted since 2019, this task provides a classification challenge from untrimmed videos recorded under natural conditions with known temporal boundaries for each stroke. Since 2021, the task also provides a stroke detection challenge from unannotated, untrimmed videos. This year, the training, validation, and test sets are enhanced to ensure that all strokes are represented in each dataset. The dataset is now similar to the one used in [1, 2]. This research is intended to build tools for coaches and athletes who want to further evaluate their sport performances.
Sports Video: Fine-Grained Action Detection and Classification of Table Tennis Strokes from Videos for MediaEval 2021
Dec 16, 2021
Sports video analysis is a prevalent research topic due to the variety of application areas, ranging from multimedia intelligent devices with user-tailored digests up to analysis of athletes' performance. The Sports Video task is part of the MediaEval 2021 benchmark. This task tackles fine-grained action detection and classification from videos. The focus is on recordings of table tennis games. Running since 2019, the task has offered a classification challenge from untrimmed video recorded in natural conditions with known temporal boundaries for each stroke. This year, the dataset is extended and offers, in addition, a detection challenge from untrimmed videos without annotations. This work aims at creating tools for sports coaches and players in order to analyze sports performance. Movement analysis and player profiling may be built upon such technology to enrich the training experience of athletes and improve their performance.
Three-Stream 3D/1D CNN for Fine-Grained Action Classification and Segmentation in Table Tennis
Sep 29, 2021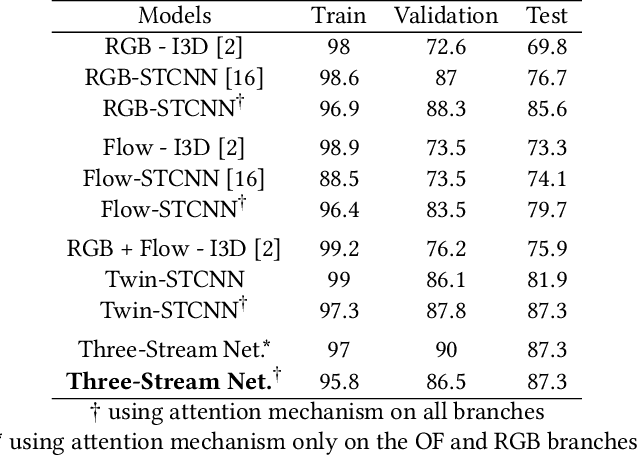
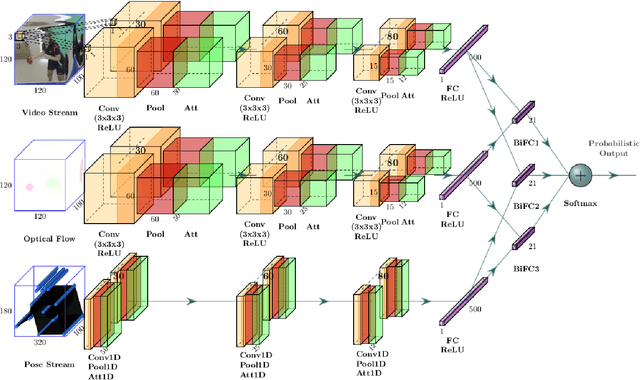
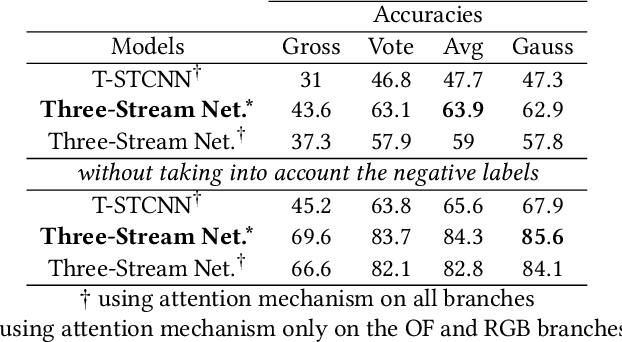

This paper proposes a fusion method of modalities extracted from video through a three-stream network with spatio-temporal and temporal convolutions for fine-grained action classification in sport. It is applied to TTStroke-21 dataset which consists of untrimmed videos of table tennis games. The goal is to detect and classify table tennis strokes in the videos, the first step of a bigger scheme aiming at giving feedback to the players for improving their performance. The three modalities are raw RGB data, the computed optical flow and the estimated pose of the player. The network consists of three branches with attention blocks. Features are fused at the latest stage of the network using bilinear layers. Compared to previous approaches, the use of three modalities allows faster convergence and better performances on both tasks: classification of strokes with known temporal boundaries and joint segmentation and classification. The pose is also further investigated in order to offer richer feedback to the athletes.
White Box Methods for Explanations of Convolutional Neural Networks in Image Classification Tasks
Apr 06, 2021


In recent years, deep learning has become prevalent to solve applications from multiple domains. Convolutional Neural Networks (CNNs) particularly have demonstrated state of the art performance for the task of image classification. However, the decisions made by these networks are not transparent and cannot be directly interpreted by a human. Several approaches have been proposed to explain to understand the reasoning behind a prediction made by a network. In this paper, we propose a topology of grouping these methods based on their assumptions and implementations. We focus primarily on white box methods that leverage the information of the internal architecture of a network to explain its decision. Given the task of image classification and a trained CNN, this work aims to provide a comprehensive and detailed overview of a set of methods that can be used to create explanation maps for a particular image, that assign an importance score to each pixel of the image based on its contribution to the decision of the network. We also propose a further classification of the white box methods based on their implementations to enable better comparisons and help researchers find methods best suited for different scenarios.
3D attention mechanism for fine-grained classification of table tennis strokes using a Twin Spatio-Temporal Convolutional Neural Networks
Nov 20, 2020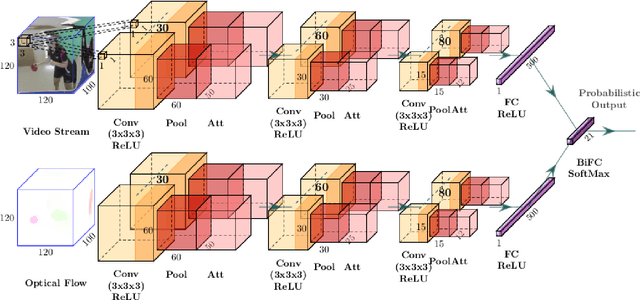
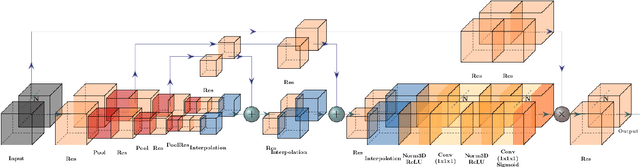
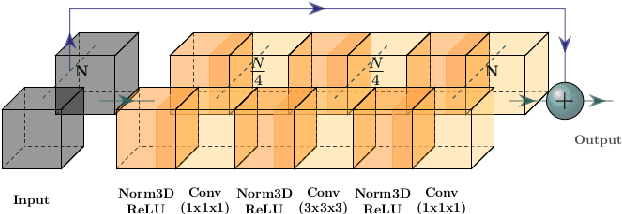

The paper addresses the problem of recognition of actions in video with low inter-class variability such as Table Tennis strokes. Two stream, "twin" convolutional neural networks are used with 3D convolutions both on RGB data and optical flow. Actions are recognized by classification of temporal windows. We introduce 3D attention modules and examine their impact on classification efficiency. In the context of the study of sportsmen performances, a corpus of the particular actions of table tennis strokes is considered. The use of attention blocks in the network speeds up the training step and improves the classification scores up to 5% with our twin model. We visualize the impact on the obtained features and notice correlation between attention and player movements and position. Score comparison of state-of-the-art action classification method and proposed approach with attentional blocks is performed on the corpus. Proposed model with attention blocks outperforms previous model without them and our baseline.
Move-to-Data: A new Continual Learning approach with Deep CNNs, Application for image-class recognition
Jun 12, 2020


In many real-life tasks of application of supervised learning approaches, all the training data are not available at the same time. The examples are lifelong image classification or recognition of environmental objects during interaction of instrumented persons with their environment, enrichment of an online-database with more images. It is necessary to pre-train the model at a "training recording phase" and then adjust it to the new coming data. This is the task of incremental/continual learning approaches. Amongst different problems to be solved by these approaches such as introduction of new categories in the model, refining existing categories to sub-categories and extending trained classifiers over them, ... we focus on the problem of adjusting pre-trained model with new additional training data for existing categories. We propose a fast continual learning layer at the end of the neuronal network. Obtained results are illustrated on the opensource CIFAR benchmark dataset. The proposed scheme yields similar performances as retraining but with drastically lower computational cost.
3D Inception-based CNN with sMRI and MD-DTI data fusion for Alzheimer's Disease diagnostics
Jul 17, 2018
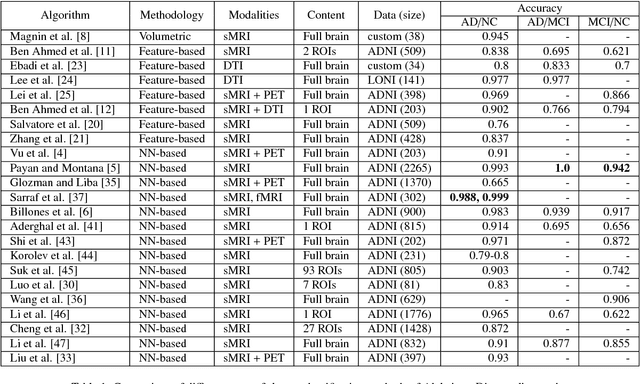
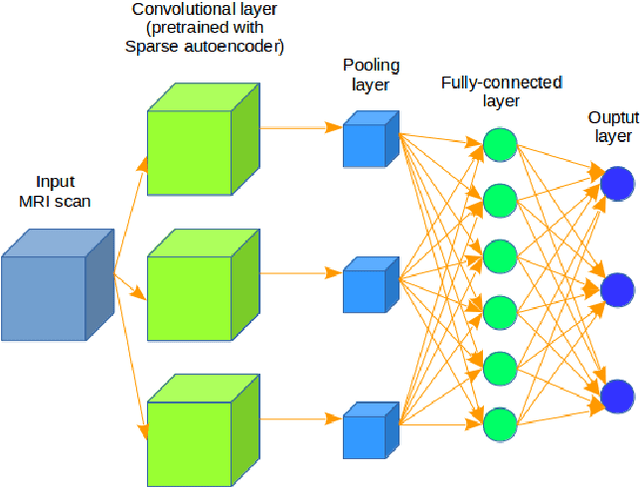
In the last decade, computer-aided early diagnostics of Alzheimer's Disease (AD) and its prodromal form, Mild Cognitive Impairment (MCI), has been the subject of extensive research. Some recent studies have shown promising results in the AD and MCI determination using structural and functional Magnetic Resonance Imaging (sMRI, fMRI), Positron Emission Tomography (PET) and Diffusion Tensor Imaging (DTI) modalities. Furthermore, fusion of imaging modalities in a supervised machine learning framework has shown promising direction of research. In this paper we first review major trends in automatic classification methods such as feature extraction based methods as well as deep learning approaches in medical image analysis applied to the field of Alzheimer's Disease diagnostics. Then we propose our own design of a 3D Inception-based Convolutional Neural Network (CNN) for Alzheimer's Disease diagnostics. The network is designed with an emphasis on the interior resource utilization and uses sMRI and DTI modalities fusion on hippocampal ROI. The comparison with the conventional AlexNet-based network using data from the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset (http://adni.loni.usc.edu) demonstrates significantly better performance of the proposed 3D Inception-based CNN.
3D CNN-based classification using sMRI and MD-DTI images for Alzheimer disease studies
Jan 18, 2018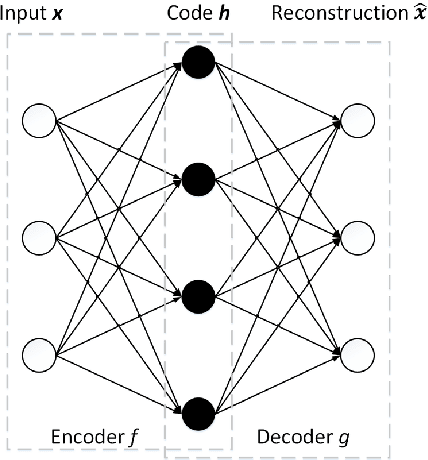
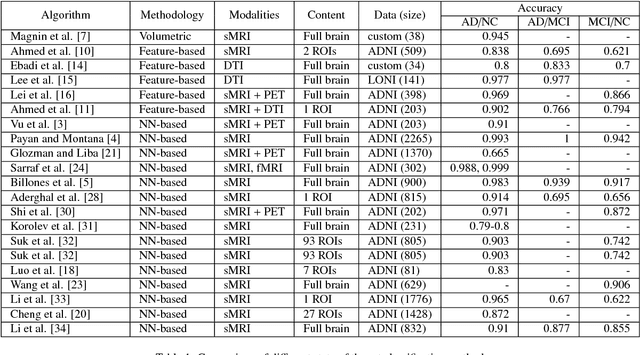
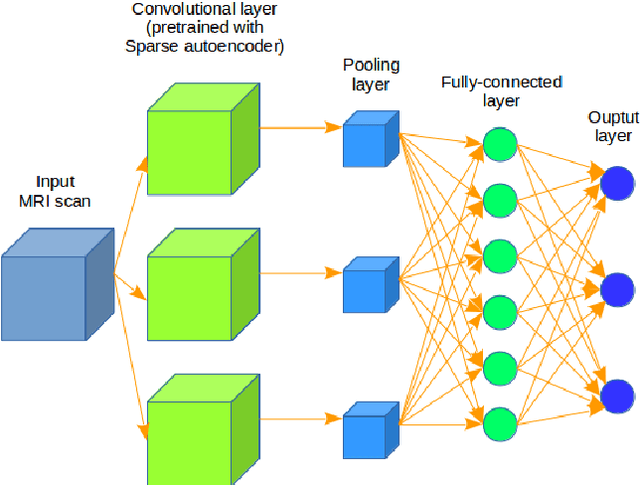
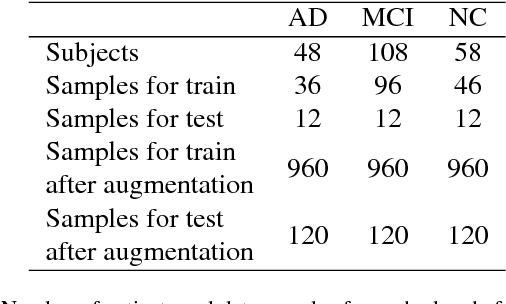
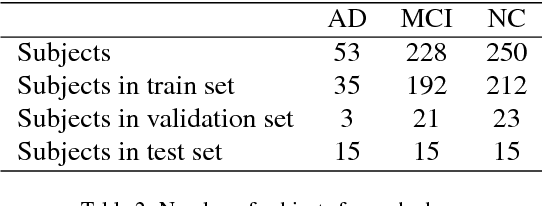
Computer-aided early diagnosis of Alzheimers Disease (AD) and its prodromal form, Mild Cognitive Impairment (MCI), has been the subject of extensive research in recent years. Some recent studies have shown promising results in the AD and MCI determination using structural and functional Magnetic Resonance Imaging (sMRI, fMRI), Positron Emission Tomography (PET) and Diffusion Tensor Imaging (DTI) modalities. Furthermore, fusion of imaging modalities in a supervised machine learning framework has shown promising direction of research. In this paper we first review major trends in automatic classification methods such as feature extraction based methods as well as deep learning approaches in medical image analysis applied to the field of Alzheimer's Disease diagnostics. Then we propose our own algorithm for Alzheimer's Disease diagnostics based on a convolutional neural network and sMRI and DTI modalities fusion on hippocampal ROI using data from the Alzheimers Disease Neuroimaging Initiative (ADNI) database (http://adni.loni.usc.edu). Comparison with a single modality approach shows promising results. We also propose our own method of data augmentation for balancing classes of different size and analyze the impact of the ROI size on the classification results as well.