 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing and incorporating expert knowledge into machine learning models for quality prediction in manufacturing
Feb 04, 2022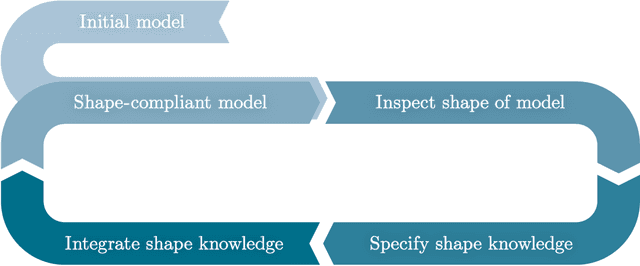

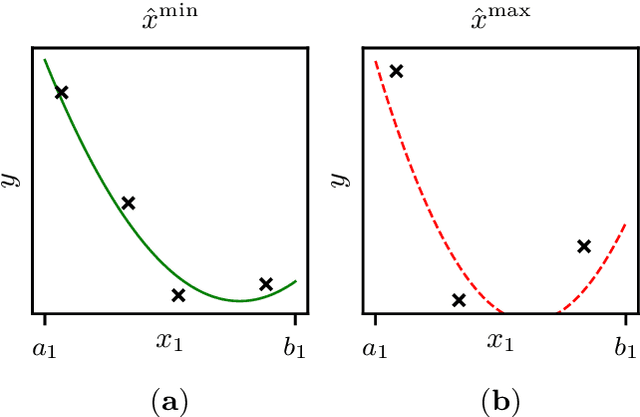
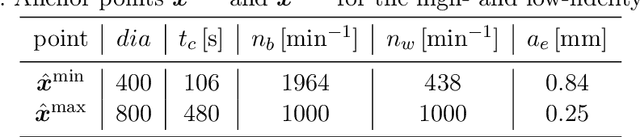
Increasing digitalization enables the use of machine learning methods for analyzing and optimizing manufacturing processes. A main application of machine learning is the construction of quality prediction models, which can be used, among other things, for documentation purposes, as assistance systems for process operators, or for adaptive process control. The quality of such machine learning models typically strongly depends on the amount and the quality of data used for training. In manufacturing, the size of available datasets before start of production is often limited. In contrast to data, expert knowledge commonly is available in manufacturing. Therefore, this study introduces a general methodology for building quality prediction models with machine learning methods on small datasets by integrating shape expert knowledge, that is, prior knowledge about the shape of the input-output relationship to be learned. The proposed methodology is applied to a brushing process with $125$ data points for predicting the surface roughness as a function of five process variables. As opposed to conventional machine learning methods for small datasets, the proposed methodology produces prediction models that strictly comply with all the expert knowledge specified by the involved process specialists. In particular, the direct involvement of process experts in the training of the models leads to a very clear interpretation and, by extension, to a high acceptance of the models. Another merit of the proposed methodology is that, in contrast to most conventional machine learning methods, it involves no time-consuming and often heuristic hyperparameter tuning or model selection step.
Move-to-Data: A new Continual Learning approach with Deep CNNs, Application for image-class recognition
Jun 12, 2020


In many real-life tasks of application of supervised learning approaches, all the training data are not available at the same time. The examples are lifelong image classification or recognition of environmental objects during interaction of instrumented persons with their environment, enrichment of an online-database with more images. It is necessary to pre-train the model at a "training recording phase" and then adjust it to the new coming data. This is the task of incremental/continual learning approaches. Amongst different problems to be solved by these approaches such as introduction of new categories in the model, refining existing categories to sub-categories and extending trained classifiers over them, ... we focus on the problem of adjusting pre-trained model with new additional training data for existing categories. We propose a fast continual learning layer at the end of the neuronal network. Obtained results are illustrated on the opensource CIFAR benchmark dataset. The proposed scheme yields similar performances as retraining but with drastically lower computational cost.