 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMove-to-Data: A new Continual Learning approach with Deep CNNs, Application for image-class recognition
Jun 12, 2020


In many real-life tasks of application of supervised learning approaches, all the training data are not available at the same time. The examples are lifelong image classification or recognition of environmental objects during interaction of instrumented persons with their environment, enrichment of an online-database with more images. It is necessary to pre-train the model at a "training recording phase" and then adjust it to the new coming data. This is the task of incremental/continual learning approaches. Amongst different problems to be solved by these approaches such as introduction of new categories in the model, refining existing categories to sub-categories and extending trained classifiers over them, ... we focus on the problem of adjusting pre-trained model with new additional training data for existing categories. We propose a fast continual learning layer at the end of the neuronal network. Obtained results are illustrated on the opensource CIFAR benchmark dataset. The proposed scheme yields similar performances as retraining but with drastically lower computational cost.
Saliency Driven Object recognition in egocentric videos with deep CNN
Jun 23, 2016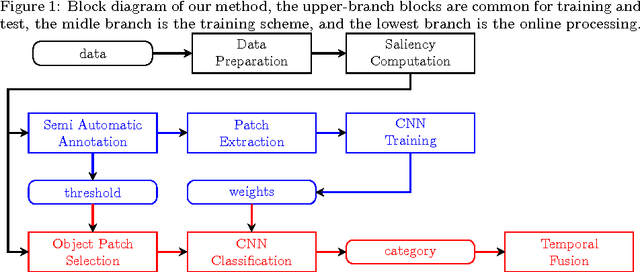


The problem of object recognition in natural scenes has been recently successfully addressed with Deep Convolutional Neuronal Networks giving a significant break-through in recognition scores. The computational efficiency of Deep CNNs as a function of their depth, allows for their use in real-time applications. One of the key issues here is to reduce the number of windows selected from images to be submitted to a Deep CNN. This is usually solved by preliminary segmentation and selection of specific windows, having outstanding "objectiveness" or other value of indicators of possible location of objects. In this paper we propose a Deep CNN approach and the general framework for recognition of objects in a real-time scenario and in an egocentric perspective. Here the window of interest is built on the basis of visual attention map computed over gaze fixations measured by a glass-worn eye-tracker. The application of this set-up is an interactive user-friendly environment for upper-limb amputees. Vision has to help the subject to control his worn neuro-prosthesis in case of a small amount of remaining muscles when the EMG control becomes unefficient. The recognition results on a specifically recorded corpus of 151 videos with simple geometrical objects show the mAP of 64,6\% and the computational time at the generalization lower than a time of a visual fixation on the object-of-interest.