 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrift Detection: Introducing Gaussian Split Detector
May 14, 2024

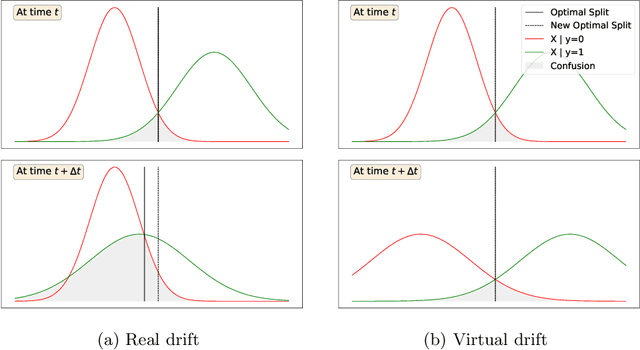

Recent research yielded a wide array of drift detectors. However, in order to achieve remarkable performance, the true class labels must be available during the drift detection phase. This paper targets at detecting drift when the ground truth is unknown during the detection phase. To that end, we introduce Gaussian Split Detector (GSD) a novel drift detector that works in batch mode. GSD is designed to work when the data follow a normal distribution and makes use of Gaussian mixture models to monitor changes in the decision boundary. The algorithm is designed to handle multi-dimension data streams and to work without the ground truth labels during the inference phase making it pertinent for real world use. In an extensive experimental study on real and synthetic datasets, we evaluate our detector against the state of the art. We show that our detector outperforms the state of the art in detecting real drift and in ignoring virtual drift which is key to avoid false alarms.
White Box Methods for Explanations of Convolutional Neural Networks in Image Classification Tasks
Apr 06, 2021

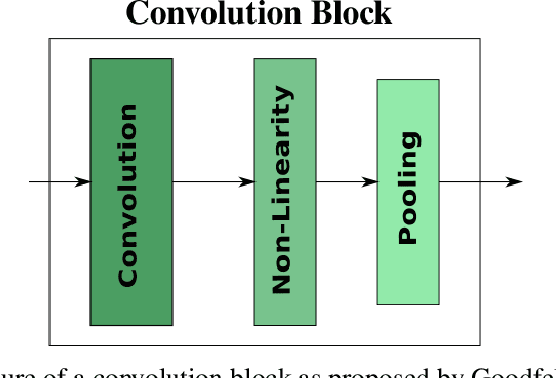

In recent years, deep learning has become prevalent to solve applications from multiple domains. Convolutional Neural Networks (CNNs) particularly have demonstrated state of the art performance for the task of image classification. However, the decisions made by these networks are not transparent and cannot be directly interpreted by a human. Several approaches have been proposed to explain to understand the reasoning behind a prediction made by a network. In this paper, we propose a topology of grouping these methods based on their assumptions and implementations. We focus primarily on white box methods that leverage the information of the internal architecture of a network to explain its decision. Given the task of image classification and a trained CNN, this work aims to provide a comprehensive and detailed overview of a set of methods that can be used to create explanation maps for a particular image, that assign an importance score to each pixel of the image based on its contribution to the decision of the network. We also propose a further classification of the white box methods based on their implementations to enable better comparisons and help researchers find methods best suited for different scenarios.
Move-to-Data: A new Continual Learning approach with Deep CNNs, Application for image-class recognition
Jun 12, 2020


In many real-life tasks of application of supervised learning approaches, all the training data are not available at the same time. The examples are lifelong image classification or recognition of environmental objects during interaction of instrumented persons with their environment, enrichment of an online-database with more images. It is necessary to pre-train the model at a "training recording phase" and then adjust it to the new coming data. This is the task of incremental/continual learning approaches. Amongst different problems to be solved by these approaches such as introduction of new categories in the model, refining existing categories to sub-categories and extending trained classifiers over them, ... we focus on the problem of adjusting pre-trained model with new additional training data for existing categories. We propose a fast continual learning layer at the end of the neuronal network. Obtained results are illustrated on the opensource CIFAR benchmark dataset. The proposed scheme yields similar performances as retraining but with drastically lower computational cost.