 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecausalgraph: A Python Package for Modeling, Persisting and Visualizing Causal Graphs Embedded in Knowledge Graphs
Jan 20, 2023


This paper describes a novel Python package, named causalgraph, for modeling and saving causal graphs embedded in knowledge graphs. The package has been designed to provide an interface between causal disciplines such as causal discovery and causal inference. With this package, users can create and save causal graphs and export the generated graphs for use in other graph-based packages. The main advantage of the proposed package is its ability to facilitate the linking of additional information and metadata to causal structures. In addition, the package offers a variety of functions for graph modeling and plotting, such as editing, adding, and deleting nodes and edges. It is also compatible with widely used graph data science libraries such as NetworkX and Tigramite and incorporates a specially developed causalgraph ontology in the background. This paper provides an overview of the package's main features, functionality, and usage examples, enabling the reader to use the package effectively in practice.
Capturing and incorporating expert knowledge into machine learning models for quality prediction in manufacturing
Feb 04, 2022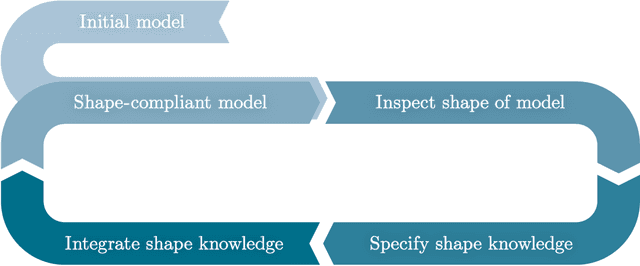

Increasing digitalization enables the use of machine learning methods for analyzing and optimizing manufacturing processes. A main application of machine learning is the construction of quality prediction models, which can be used, among other things, for documentation purposes, as assistance systems for process operators, or for adaptive process control. The quality of such machine learning models typically strongly depends on the amount and the quality of data used for training. In manufacturing, the size of available datasets before start of production is often limited. In contrast to data, expert knowledge commonly is available in manufacturing. Therefore, this study introduces a general methodology for building quality prediction models with machine learning methods on small datasets by integrating shape expert knowledge, that is, prior knowledge about the shape of the input-output relationship to be learned. The proposed methodology is applied to a brushing process with $125$ data points for predicting the surface roughness as a function of five process variables. As opposed to conventional machine learning methods for small datasets, the proposed methodology produces prediction models that strictly comply with all the expert knowledge specified by the involved process specialists. In particular, the direct involvement of process experts in the training of the models leads to a very clear interpretation and, by extension, to a high acceptance of the models. Another merit of the proposed methodology is that, in contrast to most conventional machine learning methods, it involves no time-consuming and often heuristic hyperparameter tuning or model selection step.