 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMean Opinion Score as a New Metric for User-Evaluation of XAI Methods
Jul 29, 2024This paper investigates the use of Mean Opinion Score (MOS), a common image quality metric, as a user-centric evaluation metric for XAI post-hoc explainers. To measure the MOS, a user experiment is proposed, which has been conducted with explanation maps of intentionally distorted images. Three methods from the family of feature attribution methods - Gradient-weighted Class Activation Mapping (Grad-CAM), Multi-Layered Feature Explanation Method (MLFEM), and Feature Explanation Method (FEM) - are compared with this metric. Additionally, the correlation of this new user-centric metric with automatic metrics is studied via Spearman's rank correlation coefficient. MOS of MLFEM shows the highest correlation with automatic metrics of Insertion Area Under Curve (IAUC) and Deletion Area Under Curve (DAUC). However, the overall correlations are limited, which highlights the lack of consensus between automatic and user-centric metrics.
FORBID: Fast Overlap Removal By stochastic gradIent Descent for Graph Drawing
Aug 19, 2022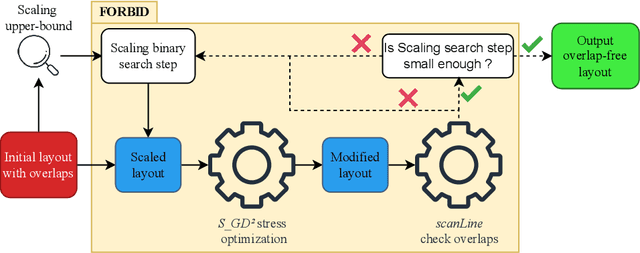
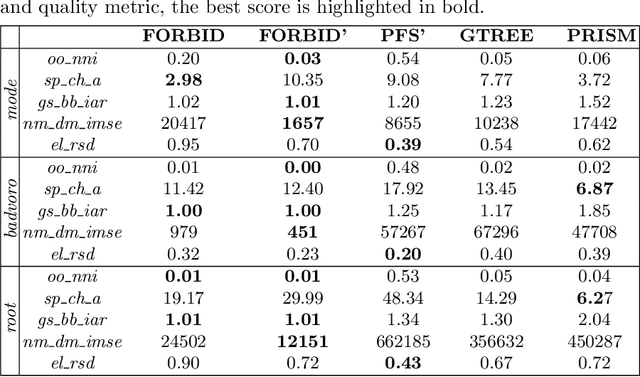
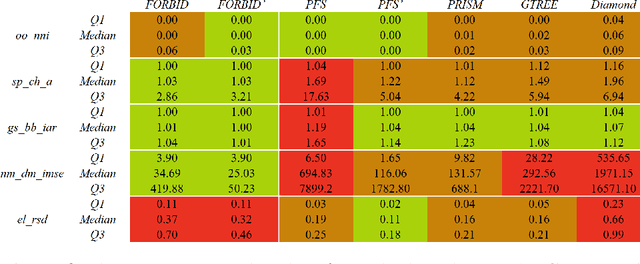

While many graph drawing algorithms consider nodes as points, graph visualization tools often represent them as shapes. These shapes support the display of information such as labels or encode various data with size or color. However, they can create overlaps between nodes which hinder the exploration process by hiding parts of the information. It is therefore of utmost importance to remove these overlaps to improve graph visualization readability. If not handled by the layout process, Overlap Removal (OR) algorithms have been proposed as layout post-processing. As graph layouts usually convey information about their topology, it is important that OR algorithms preserve them as much as possible. We propose a novel algorithm that models OR as a joint stress and scaling optimization problem, and leverages efficient stochastic gradient descent. This approach is compared with state-of-the-art algorithms, and several quality metrics demonstrate its efficiency to quickly remove overlaps while retaining the initial layout structures.
Deep Neural Network for DrawiNg Networks, ^2
Aug 10, 2021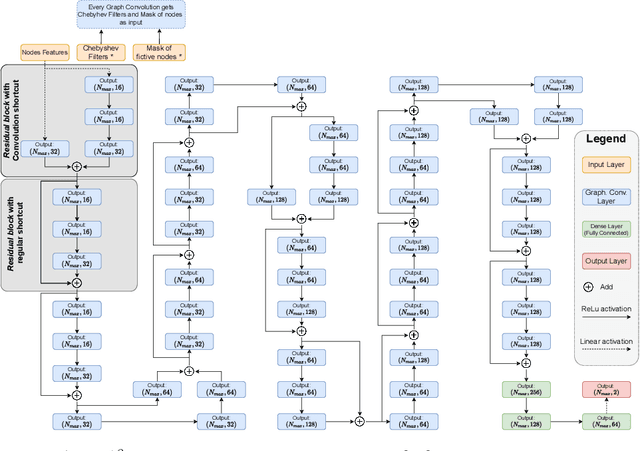
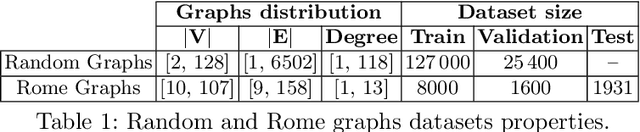
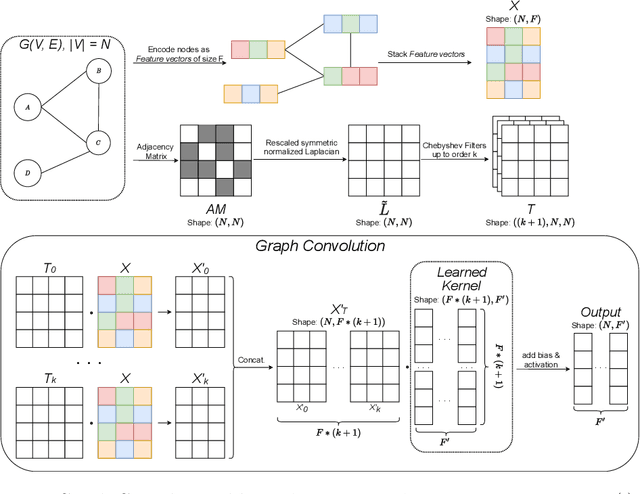

By leveraging recent progress of stochastic gradient descent methods, several works have shown that graphs could be efficiently laid out through the optimization of a tailored objective function. In the meantime, Deep Learning (DL) techniques achieved great performances in many applications. We demonstrate that it is possible to use DL techniques to learn a graph-to-layout sequence of operations thanks to a graph-related objective function. In this paper, we present a novel graph drawing framework called (DNN)^2: Deep Neural Network for DrawiNg Networks. Our method uses Graph Convolution Networks to learn a model. Learning is achieved by optimizing a graph topology related loss function that evaluates (DNN)^2 generated layouts during training. Once trained, the (DNN)^ model is able to quickly lay any input graph out. We experiment (DNN)^2 and statistically compare it to optimization-based and regular graph layout algorithms. The results show that (DNN)^2 performs well and are encouraging as the Deep Learning approach to Graph Drawing is novel and many leads for future works are identified.
Impacts of the Numbers of Colors and Shapes on Outlier Detection: from Automated to User Evaluation
Mar 10, 2021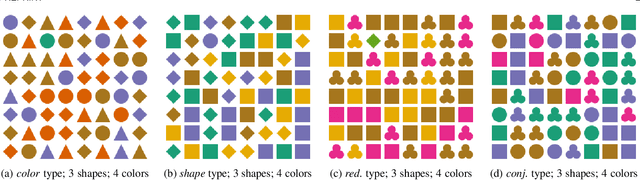
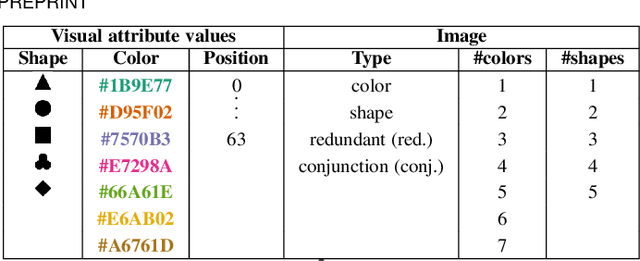
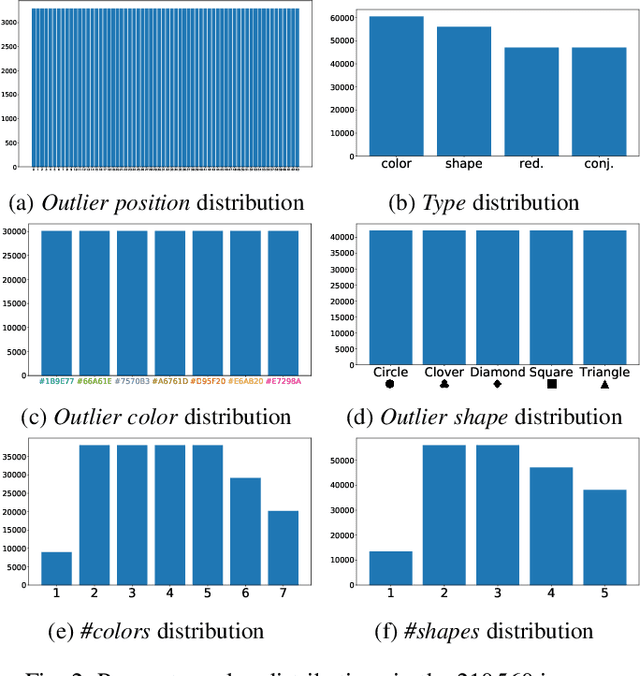
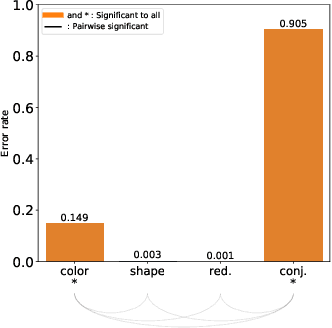
The design of efficient representations is well established as a fruitful way to explore and analyze complex or large data. In these representations, data are encoded with various visual attributes depending on the needs of the representation itself. To make coherent design choices about visual attributes, the visual search field proposes guidelines based on the human brain perception of features. However, information visualization representations frequently need to depict more data than the amount these guidelines have been validated on. Since, the information visualization community has extended these guidelines to a wider parameter space. This paper contributes to this theme by extending visual search theories to an information visualization context. We consider a visual search task where subjects are asked to find an unknown outlier in a grid of randomly laid out distractor. Stimuli are defined by color and shape features for the purpose of visually encoding categorical data. The experimental protocol is made of a parameters space reduction step (i.e., sub-sampling) based on a machine learning model, and a user evaluation to measure capacity limits and validate hypotheses. The results show that the major difficulty factor is the number of visual attributes that are used to encode the outlier. When redundantly encoded, the display heterogeneity has no effect on the task. When encoded with one attribute, the difficulty depends on that attribute heterogeneity until its capacity limit (7 for color, 5 for shape) is reached. Finally, when encoded with two attributes simultaneously, performances drop drastically even with minor heterogeneity.
CNNs Fusion for Building Detection in Aerial Images for the Building Detection Challenge
Sep 28, 2018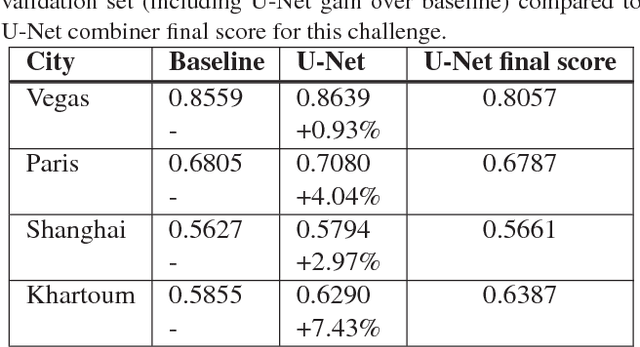


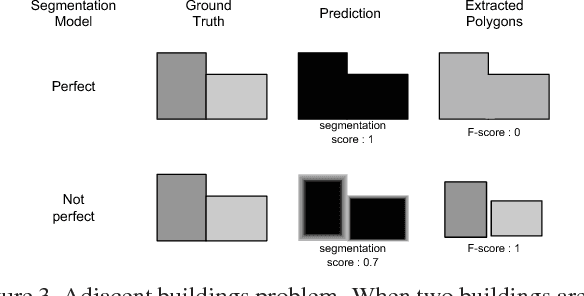
This paper presents our contribution to the DeepGlobe Building Detection Challenge. We enhanced the SpaceNet Challenge winning solution by proposing a new fusion strategy based on a deep combiner using segmentation both results of different CNN and input data to segment. Segmentation results for all cities have been significantly improved (between 1% improvement over the baseline for the smallest one to more than 7% for the largest one). The separation of adjacent buildings should be the next enhancement made to the solution.
Web-Based Benchmark for Keystroke Dynamics Biometric Systems: A Statistical Analysis
Jul 03, 2012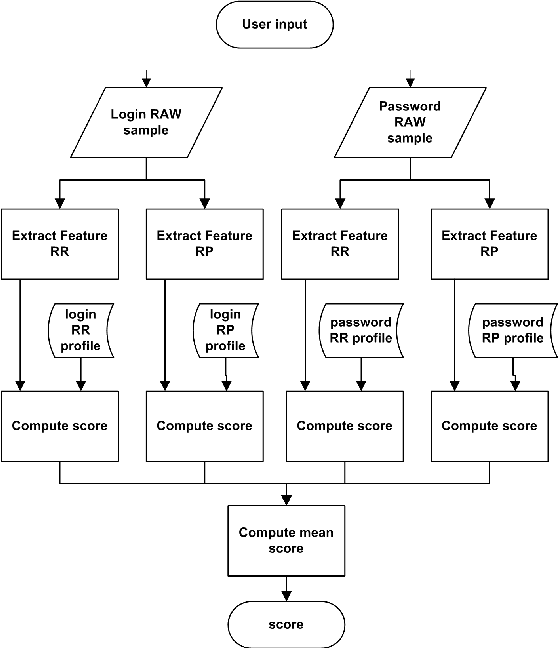
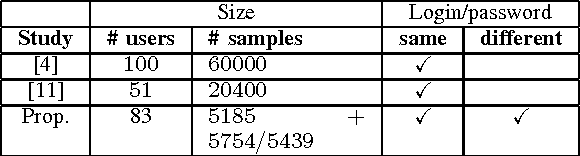
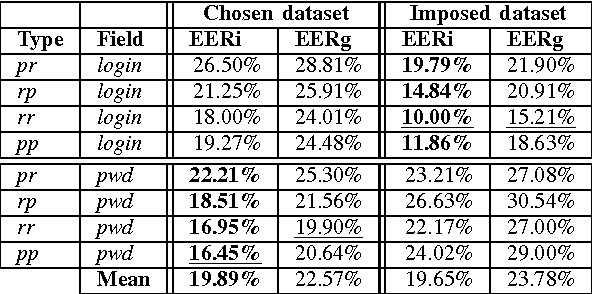
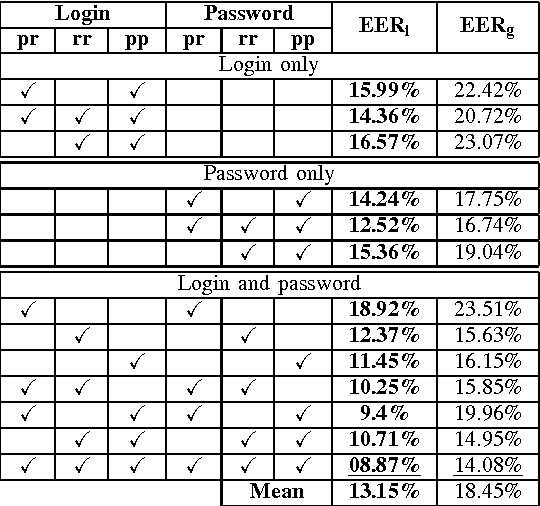
Most keystroke dynamics studies have been evaluated using a specific kind of dataset in which users type an imposed login and password. Moreover, these studies are optimistics since most of them use different acquisition protocols, private datasets, controlled environment, etc. In order to enhance the accuracy of keystroke dynamics' performance, the main contribution of this paper is twofold. First, we provide a new kind of dataset in which users have typed both an imposed and a chosen pairs of logins and passwords. In addition, the keystroke dynamics samples are collected in a web-based uncontrolled environment (OS, keyboards, browser, etc.). Such kind of dataset is important since it provides us more realistic results of keystroke dynamics' performance in comparison to the literature (controlled environment, etc.). Second, we present a statistical analysis of well known assertions such as the relationship between performance and password size, impact of fusion schemes on system overall performance, and others such as the relationship between performance and entropy. We put into obviousness in this paper some new results on keystroke dynamics in realistic conditions.
Hybrid Template Update System for Unimodal Biometric Systems
Jul 03, 2012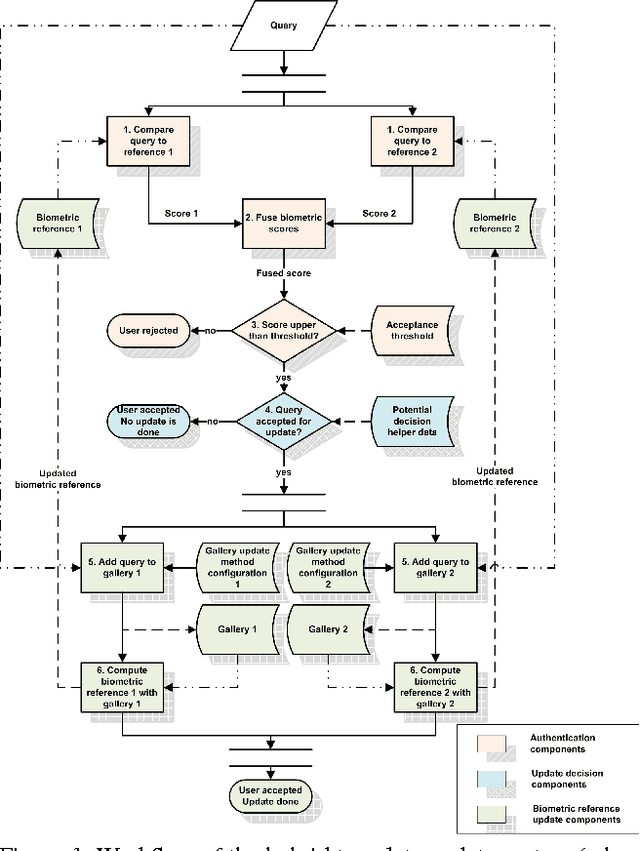
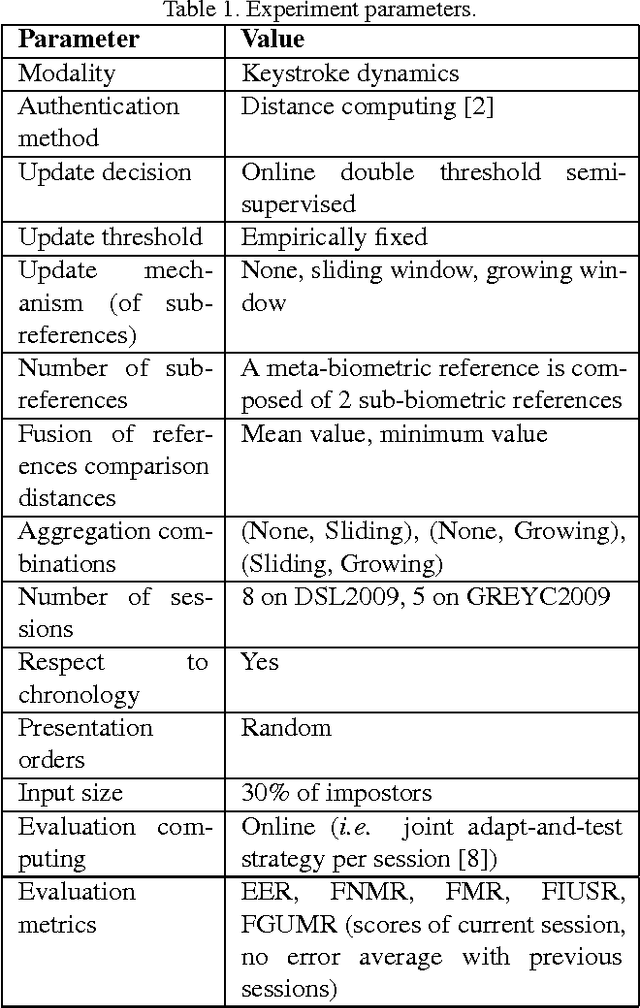
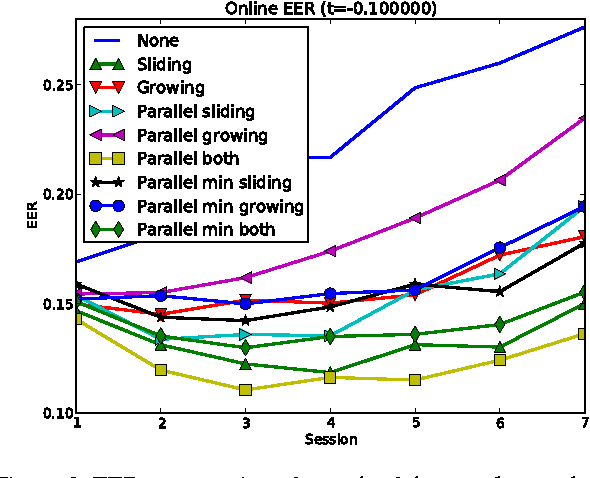
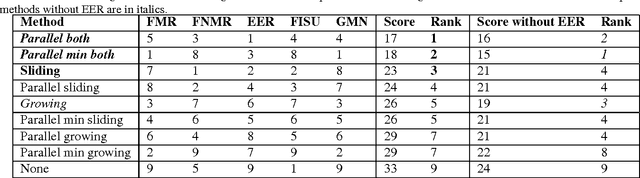
Semi-supervised template update systems allow to automatically take into account the intra-class variability of the biometric data over time. Such systems can be inefficient by including too many impostor's samples or skipping too many genuine's samples. In the first case, the biometric reference drifts from the real biometric data and attracts more often impostors. In the second case, the biometric reference does not evolve quickly enough and also progressively drifts from the real biometric data. We propose a hybrid system using several biometric sub-references in order to increase per- formance of self-update systems by reducing the previously cited errors. The proposition is validated for a keystroke- dynamics authentication system (this modality suffers of high variability over time) on two consequent datasets from the state of the art.
Local Water Diffusion Phenomenon Clustering From High Angular Resolution Diffusion Imaging (HARDI)
Jul 03, 2012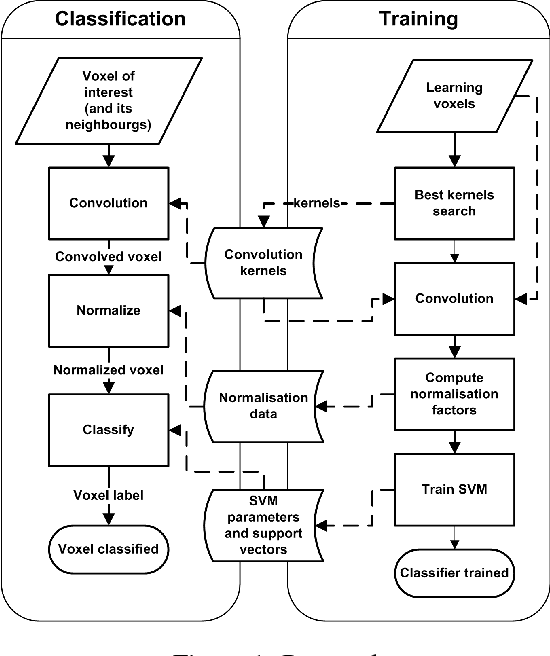
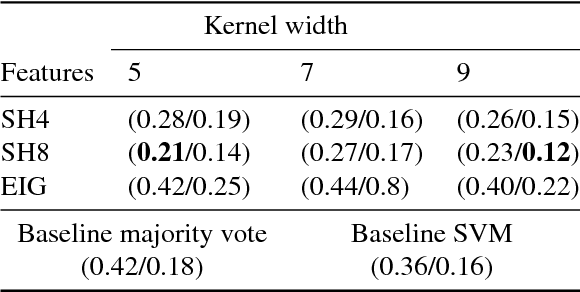
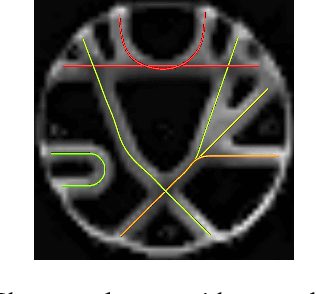
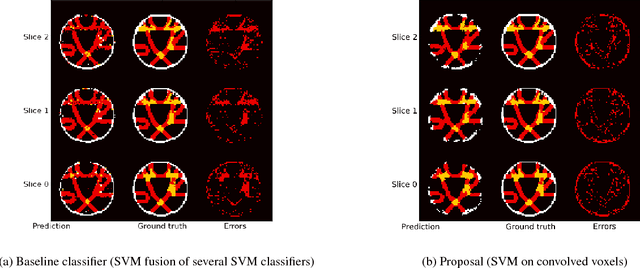
The understanding of neurodegenerative diseases undoubtedly passes through the study of human brain white matter fiber tracts. To date, diffusion magnetic resonance imaging (dMRI) is the unique technique to obtain information about the neural architecture of the human brain, thus permitting the study of white matter connections and their integrity. However, a remaining challenge of the dMRI community is to better characterize complex fiber crossing configurations, where diffusion tensor imaging (DTI) is limited but high angular resolution diffusion imaging (HARDI) now brings solutions. This paper investigates the development of both identification and classification process of the local water diffusion phenomenon based on HARDI data to automatically detect imaging voxels where there are single and crossing fiber bundle populations. The technique is based on knowledge extraction processes and is validated on a dMRI phantom dataset with ground truth.
Genetic Programming for Multibiometrics
Feb 20, 2012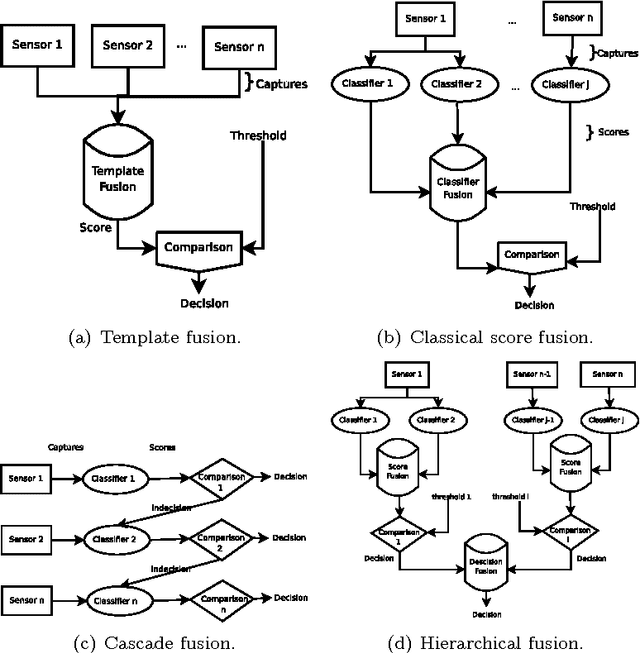
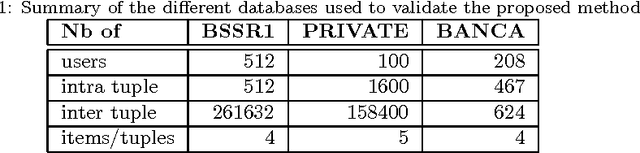
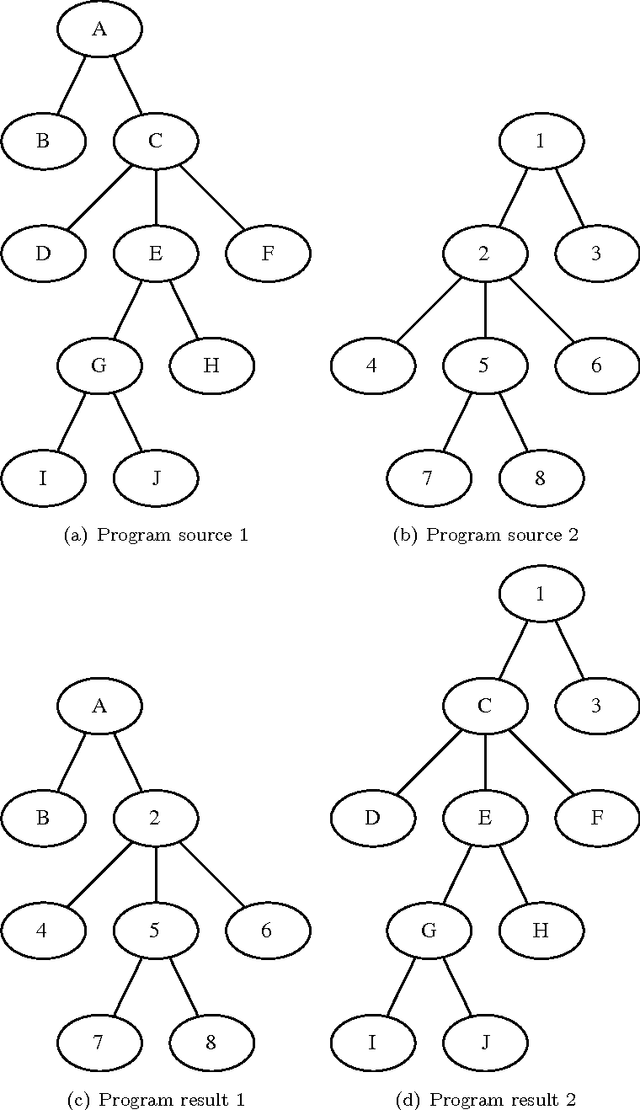
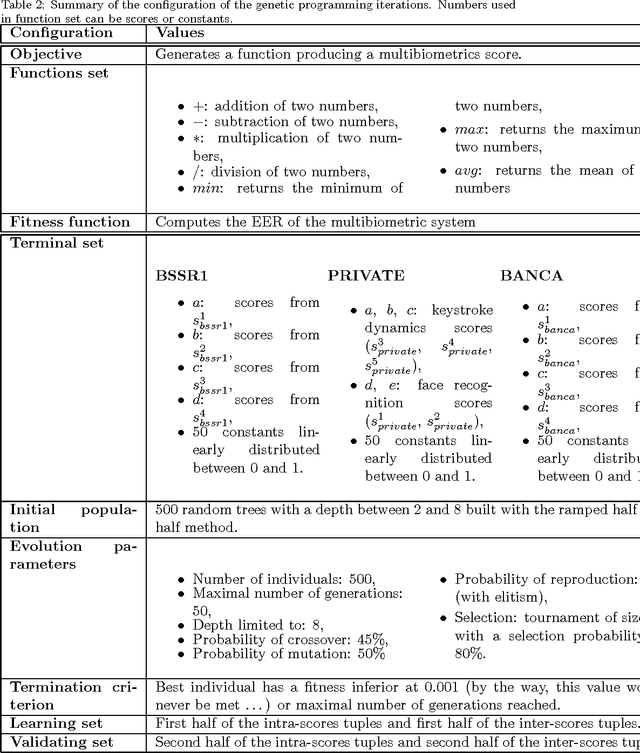
Biometric systems suffer from some drawbacks: a biometric system can provide in general good performances except with some individuals as its performance depends highly on the quality of the capture. One solution to solve some of these problems is to use multibiometrics where different biometric systems are combined together (multiple captures of the same biometric modality, multiple feature extraction algorithms, multiple biometric modalities...). In this paper, we are interested in score level fusion functions application (i.e., we use a multibiometric authentication scheme which accept or deny the claimant for using an application). In the state of the art, the weighted sum of scores (which is a linear classifier) and the use of an SVM (which is a non linear classifier) provided by different biometric systems provide one of the best performances. We present a new method based on the use of genetic programming giving similar or better performances (depending on the complexity of the database). We derive a score fusion function by assembling some classical primitives functions (+, *, -, ...). We have validated the proposed method on three significant biometric benchmark datasets from the state of the art.
Keystroke Dynamics Authentication For Collaborative Systems
Nov 17, 2009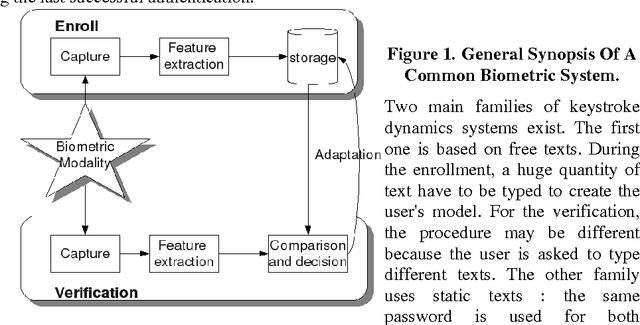
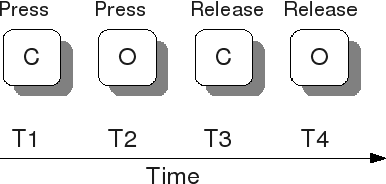
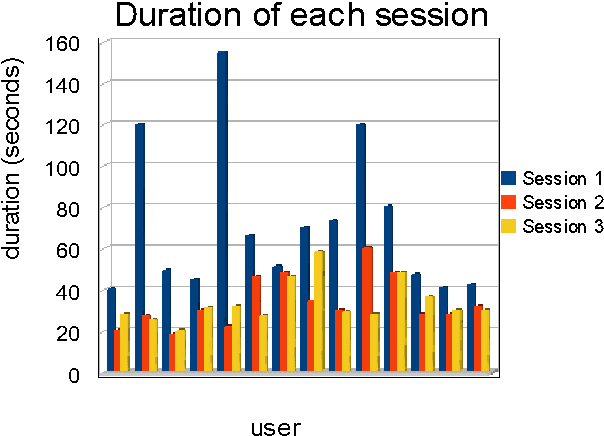
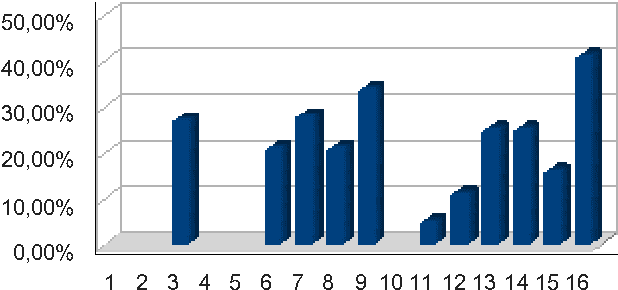
We present in this paper a study on the ability and the benefits of using a keystroke dynamics authentication method for collaborative systems. Authentication is a challenging issue in order to guarantee the security of use of collaborative systems during the access control step. Many solutions exist in the state of the art such as the use of one time passwords or smart-cards. We focus in this paper on biometric based solutions that do not necessitate any additional sensor. Keystroke dynamics is an interesting solution as it uses only the keyboard and is invisible for users. Many methods have been published in this field. We make a comparative study of many of them considering the operational constraints of use for collaborative systems.