 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree-Stream 3D/1D CNN for Fine-Grained Action Classification and Segmentation in Table Tennis
Paper and Code
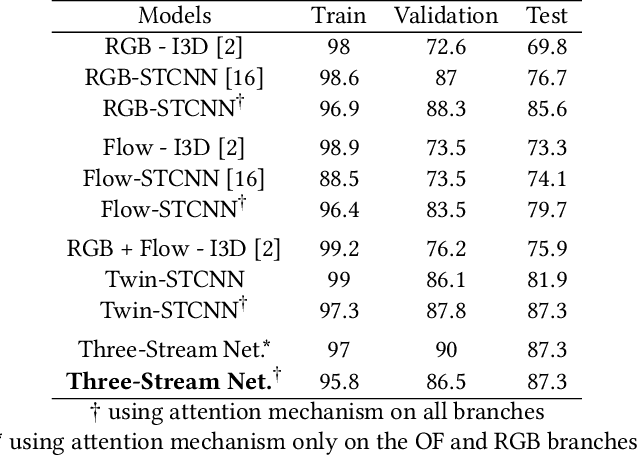
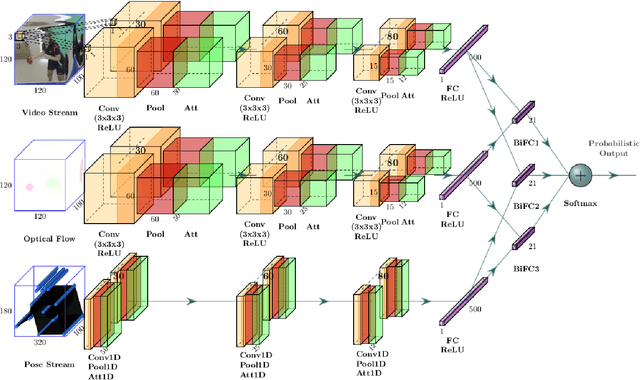
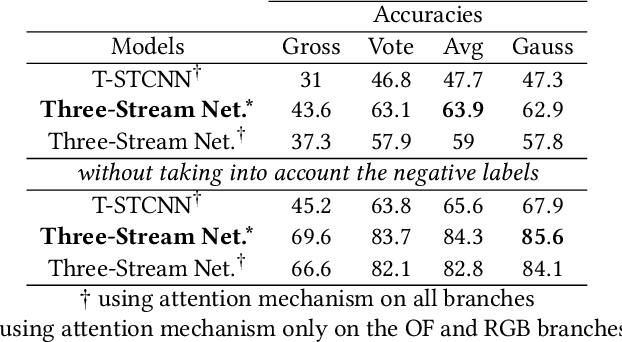

This paper proposes a fusion method of modalities extracted from video through a three-stream network with spatio-temporal and temporal convolutions for fine-grained action classification in sport. It is applied to TTStroke-21 dataset which consists of untrimmed videos of table tennis games. The goal is to detect and classify table tennis strokes in the videos, the first step of a bigger scheme aiming at giving feedback to the players for improving their performance. The three modalities are raw RGB data, the computed optical flow and the estimated pose of the player. The network consists of three branches with attention blocks. Features are fused at the latest stage of the network using bilinear layers. Compared to previous approaches, the use of three modalities allows faster convergence and better performances on both tasks: classification of strokes with known temporal boundaries and joint segmentation and classification. The pose is also further investigated in order to offer richer feedback to the athletes.