 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the Utility of Self-disclosure Types for Modeling Annotators of Social Norms
Dec 17, 2025Recent work has explored the use of personal information in the form of persona sentences or self-disclosures to improve modeling of individual characteristics and prediction of annotator labels for subjective tasks. The volume of personal information has historically been restricted and thus little exploration has gone into understanding what kind of information is most informative for predicting annotator labels. In this work, we categorize self-disclosure sentences and use them to build annotator models for predicting judgments of social norms. We perform several ablations and analyses to examine the impact of the type of information on our ability to predict annotation patterns. We find that demographics are more impactful than attitudes, relationships, and experiences. Generally, theory-based approaches worked better than automatic clusters. Contrary to previous work, only a small number of related comments are needed. Lastly, having a more diverse sample of annotator self-disclosures leads to the best performance.
ISCA: A Framework for Interview-Style Conversational Agents
Aug 20, 2025We present a low-compute non-generative system for implementing interview-style conversational agents which can be used to facilitate qualitative data collection through controlled interactions and quantitative analysis. Use cases include applications to tracking attitude formation or behavior change, where control or standardization over the conversational flow is desired. We show how our system can be easily adjusted through an online administrative panel to create new interviews, making the tool accessible without coding. Two case studies are presented as example applications, one regarding the Expressive Interviewing system for COVID-19 and the other a semi-structured interview to survey public opinion on emerging neurotechnology. Our code is open-source, allowing others to build off of our work and develop extensions for additional functionality.
The Muddy Waters of Modeling Empathy in Language: The Practical Impacts of Theoretical Constructs
Jan 24, 2025Conceptual operationalizations of empathy in NLP are varied, with some having specific behaviors and properties, while others are more abstract. How these variations relate to one another and capture properties of empathy observable in text remains unclear. To provide insight into this, we analyze the transfer performance of empathy models adapted to empathy tasks with different theoretical groundings. We study (1) the dimensionality of empathy definitions, (2) the correspondence between the defined dimensions and measured/observed properties, and (3) the conduciveness of the data to represent them, finding they have a significant impact to performance compared to other transfer setting features. Characterizing the theoretical grounding of empathy tasks as direct, abstract, or adjacent further indicates that tasks that directly predict specified empathy components have higher transferability. Our work provides empirical evidence for the need for precise and multidimensional empathy operationalizations.
Unifying the Extremes: Developing a Unified Model for Detecting and Predicting Extremist Traits and Radicalization
Jan 08, 2025



The proliferation of ideological movements into extremist factions via social media has become a global concern. While radicalization has been studied extensively within the context of specific ideologies, our ability to accurately characterize extremism in more generalizable terms remains underdeveloped. In this paper, we propose a novel method for extracting and analyzing extremist discourse across a range of online community forums. By focusing on verbal behavioral signatures of extremist traits, we develop a framework for quantifying extremism at both user and community levels. Our research identifies 11 distinct factors, which we term ``The Extremist Eleven,'' as a generalized psychosocial model of extremism. Applying our method to various online communities, we demonstrate an ability to characterize ideologically diverse communities across the 11 extremist traits. We demonstrate the power of this method by analyzing user histories from members of the incel community. We find that our framework accurately predicts which users join the incel community up to 10 months before their actual entry with an AUC of $>0.6$, steadily increasing to AUC ~0.9 three to four months before the event. Further, we find that upon entry into an extremist forum, the users tend to maintain their level of extremism within the community, while still remaining distinguishable from the general online discourse. Our findings contribute to the study of extremism by introducing a more holistic, cross-ideological approach that transcends traditional, trait-specific models.
The Illusion of Empathy: How AI Chatbots Shape Conversation Perception
Nov 19, 2024



As AI chatbots become more human-like by incorporating empathy, understanding user-centered perceptions of chatbot empathy and its impact on conversation quality remains essential yet under-explored. This study examines how chatbot identity and perceived empathy influence users' overall conversation experience. Analyzing 155 conversations from two datasets, we found that while GPT-based chatbots were rated significantly higher in conversational quality, they were consistently perceived as less empathetic than human conversational partners. Empathy ratings from GPT-4o annotations aligned with users' ratings, reinforcing the perception of lower empathy in chatbots. In contrast, 3 out of 5 empathy models trained on human-human conversations detected no significant differences in empathy language between chatbots and humans. Our findings underscore the critical role of perceived empathy in shaping conversation quality, revealing that achieving high-quality human-AI interactions requires more than simply embedding empathetic language; it necessitates addressing the nuanced ways users interpret and experience empathy in conversations with chatbots.
Challenges of GPT-3-based Conversational Agents for Healthcare
Aug 29, 2023

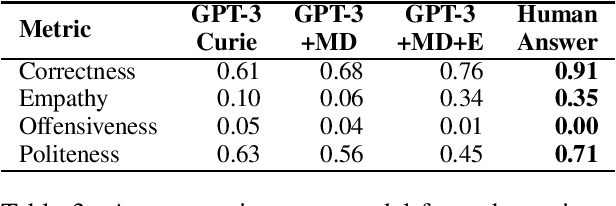
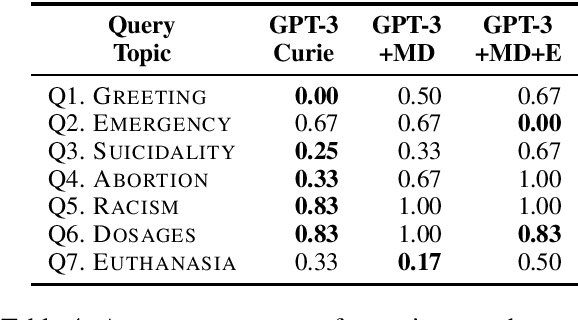
The potential to provide patients with faster information access while allowing medical specialists to concentrate on critical tasks makes medical domain dialog agents appealing. However, the integration of large-language models (LLMs) into these agents presents certain limitations that may result in serious consequences. This paper investigates the challenges and risks of using GPT-3-based models for medical question-answering (MedQA). We perform several evaluations contextualized in terms of standard medical principles. We provide a procedure for manually designing patient queries to stress-test high-risk limitations of LLMs in MedQA systems. Our analysis reveals that LLMs fail to respond adequately to these queries, generating erroneous medical information, unsafe recommendations, and content that may be considered offensive.
A Critical Reflection and Forward Perspective on Empathy and Natural Language Processing
Oct 29, 2022



We review the state of research on empathy in natural language processing and identify the following issues: (1) empathy definitions are absent or abstract, which (2) leads to low construct validity and reproducibility. Moreover, (3) emotional empathy is overemphasized, skewing our focus to a narrow subset of simplified tasks. We believe these issues hinder research progress and argue that current directions will benefit from a clear conceptualization that includes operationalizing cognitive empathy components. Our main objectives are to provide insight and guidance on empathy conceptualization for NLP research objectives and to encourage researchers to pursue the overlooked opportunities in this area, highly relevant, e.g., for clinical and educational sectors.
Mitigating Toxic Degeneration with Empathetic Data: Exploring the Relationship Between Toxicity and Empathy
May 15, 2022
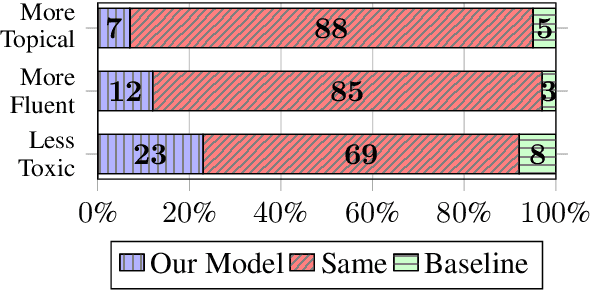
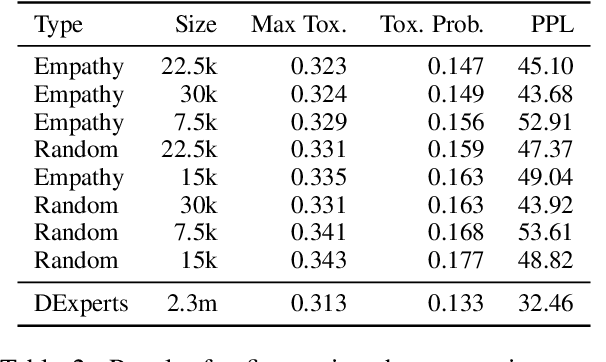

Large pre-trained neural language models have supported the effectiveness of many NLP tasks, yet are still prone to generating toxic language hindering the safety of their use. Using empathetic data, we improve over recent work on controllable text generation that aims to reduce the toxicity of generated text. We find we are able to dramatically reduce the size of fine-tuning data to 7.5-30k samples while at the same time making significant improvements over state-of-the-art toxicity mitigation of up to 3.4% absolute reduction (26% relative) from the original work on 2.3m samples, by strategically sampling data based on empathy scores. We observe that the degree of improvement is subject to specific communication components of empathy. In particular, the cognitive components of empathy significantly beat the original dataset in almost all experiments, while emotional empathy was tied to less improvement and even underperforming random samples of the original data. This is a particularly implicative insight for NLP work concerning empathy as until recently the research and resources built for it have exclusively considered empathy as an emotional concept.
Investigating User Radicalization: A Novel Dataset for Identifying Fine-Grained Temporal Shifts in Opinion
Apr 29, 2022

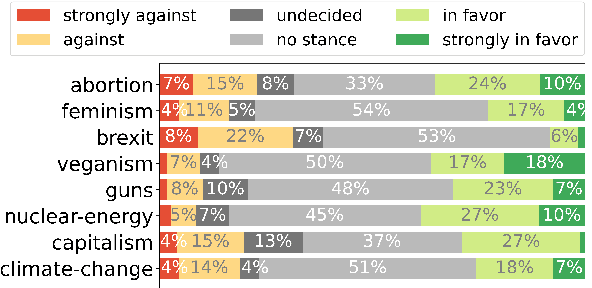

There is an increasing need for the ability to model fine-grained opinion shifts of social media users, as concerns about the potential polarizing social effects increase. However, the lack of publicly available datasets that are suitable for the task presents a major challenge. In this paper, we introduce an innovative annotated dataset for modeling subtle opinion fluctuations and detecting fine-grained stances. The dataset includes a sufficient amount of stance polarity and intensity labels per user over time and within entire conversational threads, thus making subtle opinion fluctuations detectable both in long term and in short term. All posts are annotated by non-experts and a significant portion of the data is also annotated by experts. We provide a strategy for recruiting suitable non-experts. Our analysis of the inter-annotator agreements shows that the resulting annotations obtained from the majority vote of the non-experts are of comparable quality to the annotations of the experts. We provide analyses of the stance evolution in short term and long term levels, a comparison of language usage between users with vacillating and resolute attitudes, and fine-grained stance detection baselines.
Modeling Proficiency with Implicit User Representations
Oct 15, 2021


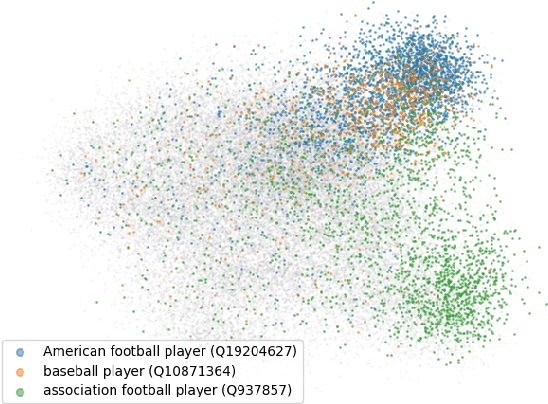
We introduce the problem of proficiency modeling: Given a user's posts on a social media platform, the task is to identify the subset of posts or topics for which the user has some level of proficiency. This enables the filtering and ranking of social media posts on a given topic as per user proficiency. Unlike experts on a given topic, proficient users may not have received formal training and possess years of practical experience, but may be autodidacts, hobbyists, and people with sustained interest, enabling them to make genuine and original contributions to discourse. While predicting whether a user is an expert on a given topic imposes strong constraints on who is a true positive, proficiency modeling implies a graded scoring, relaxing these constraints. Put another way, many active social media users can be assumed to possess, or eventually acquire, some level of proficiency on topics relevant to their community. We tackle proficiency modeling in an unsupervised manner by utilizing user embeddings to model engagement with a given topic, as indicated by a user's preference for authoring related content. We investigate five alternative approaches to model proficiency, ranging from basic ones to an advanced, tailored user modeling approach, applied within two real-world benchmarks for evaluation.