 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges of GPT-3-based Conversational Agents for Healthcare
Aug 29, 2023

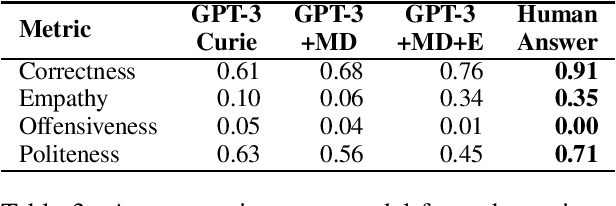
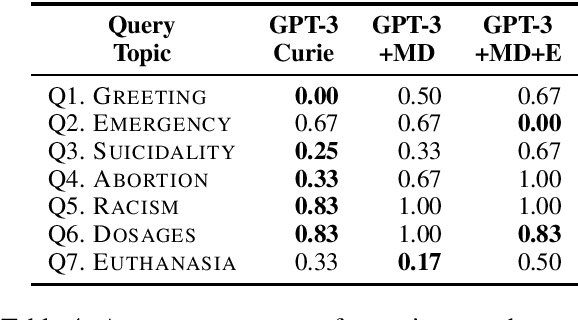
The potential to provide patients with faster information access while allowing medical specialists to concentrate on critical tasks makes medical domain dialog agents appealing. However, the integration of large-language models (LLMs) into these agents presents certain limitations that may result in serious consequences. This paper investigates the challenges and risks of using GPT-3-based models for medical question-answering (MedQA). We perform several evaluations contextualized in terms of standard medical principles. We provide a procedure for manually designing patient queries to stress-test high-risk limitations of LLMs in MedQA systems. Our analysis reveals that LLMs fail to respond adequately to these queries, generating erroneous medical information, unsafe recommendations, and content that may be considered offensive.