 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpus Considerations for Annotator Modeling and Scaling
Apr 02, 2024Recent trends in natural language processing research and annotation tasks affirm a paradigm shift from the traditional reliance on a single ground truth to a focus on individual perspectives, particularly in subjective tasks. In scenarios where annotation tasks are meant to encompass diversity, models that solely rely on the majority class labels may inadvertently disregard valuable minority perspectives. This oversight could result in the omission of crucial information and, in a broader context, risk disrupting the balance within larger ecosystems. As the landscape of annotator modeling unfolds with diverse representation techniques, it becomes imperative to investigate their effectiveness with the fine-grained features of the datasets in view. This study systematically explores various annotator modeling techniques and compares their performance across seven corpora. From our findings, we show that the commonly used user token model consistently outperforms more complex models. We introduce a composite embedding approach and show distinct differences in which model performs best as a function of the agreement with a given dataset. Our findings shed light on the relationship between corpus statistics and annotator modeling performance, which informs future work on corpus construction and perspectivist NLP.
Unifying Data Perspectivism and Personalization: An Application to Social Norms
Oct 31, 2022Instead of using a single ground truth for language processing tasks, several recent studies have examined how to represent and predict the labels of the set of annotators. However, often little or no information about annotators is known, or the set of annotators is small. In this work, we examine a corpus of social media posts about conflict from a set of 13k annotators and 210k judgements of social norms. We provide a novel experimental setup that applies personalization methods to the modeling of annotators and compare their effectiveness for predicting the perception of social norms. We further provide an analysis of performance across subsets of social situations that vary by the closeness of the relationship between parties in conflict, and assess where personalization helps the most.
Understanding Interpersonal Conflict Types and their Impact on Perception Classification
Aug 18, 2022

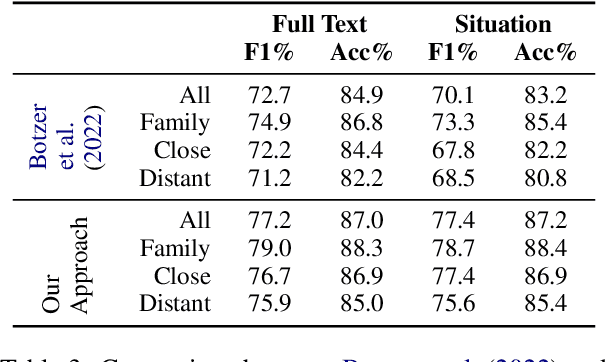

Studies on interpersonal conflict have a long history and contain many suggestions for conflict typology. We use this as the basis of a novel annotation scheme and release a new dataset of situations and conflict aspect annotations. We then build a classifier to predict whether someone will perceive the actions of one individual as right or wrong in a given situation, outperforming previous work on this task. Our analyses include conflict aspects, but also generated clusters, which are human validated, and show differences in conflict content based on the relationship of participants to the author. Our findings have important implications for understanding conflict and social norms.
Mitigating Toxic Degeneration with Empathetic Data: Exploring the Relationship Between Toxicity and Empathy
May 15, 2022
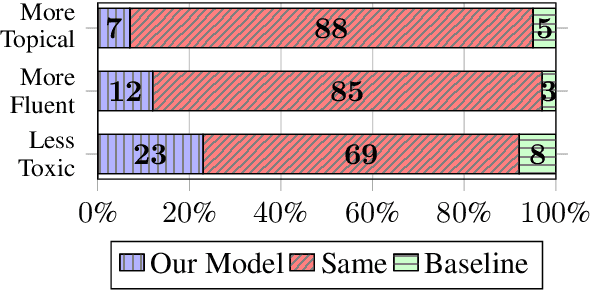
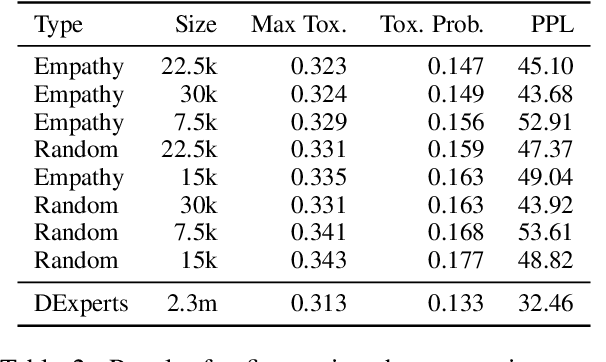

Large pre-trained neural language models have supported the effectiveness of many NLP tasks, yet are still prone to generating toxic language hindering the safety of their use. Using empathetic data, we improve over recent work on controllable text generation that aims to reduce the toxicity of generated text. We find we are able to dramatically reduce the size of fine-tuning data to 7.5-30k samples while at the same time making significant improvements over state-of-the-art toxicity mitigation of up to 3.4% absolute reduction (26% relative) from the original work on 2.3m samples, by strategically sampling data based on empathy scores. We observe that the degree of improvement is subject to specific communication components of empathy. In particular, the cognitive components of empathy significantly beat the original dataset in almost all experiments, while emotional empathy was tied to less improvement and even underperforming random samples of the original data. This is a particularly implicative insight for NLP work concerning empathy as until recently the research and resources built for it have exclusively considered empathy as an emotional concept.