 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Multilingual Large Language Models Mitigate Stereotype Bias?
Jul 09, 2024



While preliminary findings indicate that multilingual LLMs exhibit reduced bias compared to monolingual ones, a comprehensive understanding of the effect of multilingual training on bias mitigation, is lacking. This study addresses this gap by systematically training six LLMs of identical size (2.6B parameters) and architecture: five monolingual models (English, German, French, Italian, and Spanish) and one multilingual model trained on an equal distribution of data across these languages, all using publicly available data. To ensure robust evaluation, standard bias benchmarks were automatically translated into the five target languages and verified for both translation quality and bias preservation by human annotators. Our results consistently demonstrate that multilingual training effectively mitigates bias. Moreover, we observe that multilingual models achieve not only lower bias but also superior prediction accuracy when compared to monolingual models with the same amount of training data, model architecture, and size.
Corpus Considerations for Annotator Modeling and Scaling
Apr 02, 2024Recent trends in natural language processing research and annotation tasks affirm a paradigm shift from the traditional reliance on a single ground truth to a focus on individual perspectives, particularly in subjective tasks. In scenarios where annotation tasks are meant to encompass diversity, models that solely rely on the majority class labels may inadvertently disregard valuable minority perspectives. This oversight could result in the omission of crucial information and, in a broader context, risk disrupting the balance within larger ecosystems. As the landscape of annotator modeling unfolds with diverse representation techniques, it becomes imperative to investigate their effectiveness with the fine-grained features of the datasets in view. This study systematically explores various annotator modeling techniques and compares their performance across seven corpora. From our findings, we show that the commonly used user token model consistently outperforms more complex models. We introduce a composite embedding approach and show distinct differences in which model performs best as a function of the agreement with a given dataset. Our findings shed light on the relationship between corpus statistics and annotator modeling performance, which informs future work on corpus construction and perspectivist NLP.
Unifying Data Perspectivism and Personalization: An Application to Social Norms
Oct 31, 2022Instead of using a single ground truth for language processing tasks, several recent studies have examined how to represent and predict the labels of the set of annotators. However, often little or no information about annotators is known, or the set of annotators is small. In this work, we examine a corpus of social media posts about conflict from a set of 13k annotators and 210k judgements of social norms. We provide a novel experimental setup that applies personalization methods to the modeling of annotators and compare their effectiveness for predicting the perception of social norms. We further provide an analysis of performance across subsets of social situations that vary by the closeness of the relationship between parties in conflict, and assess where personalization helps the most.
Understanding Interpersonal Conflict Types and their Impact on Perception Classification
Aug 18, 2022


Studies on interpersonal conflict have a long history and contain many suggestions for conflict typology. We use this as the basis of a novel annotation scheme and release a new dataset of situations and conflict aspect annotations. We then build a classifier to predict whether someone will perceive the actions of one individual as right or wrong in a given situation, outperforming previous work on this task. Our analyses include conflict aspects, but also generated clusters, which are human validated, and show differences in conflict content based on the relationship of participants to the author. Our findings have important implications for understanding conflict and social norms.
Refining Diagnosis Paths for Medical Diagnosis based on an Augmented Knowledge Graph
Apr 28, 2022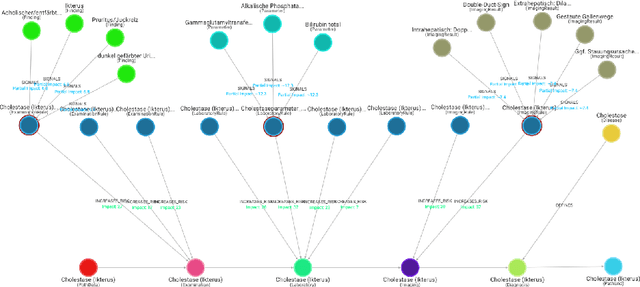
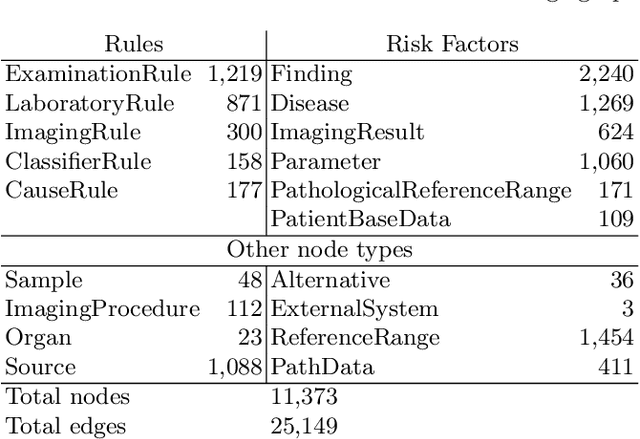
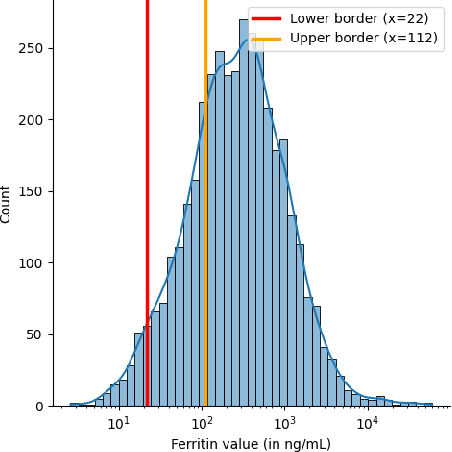

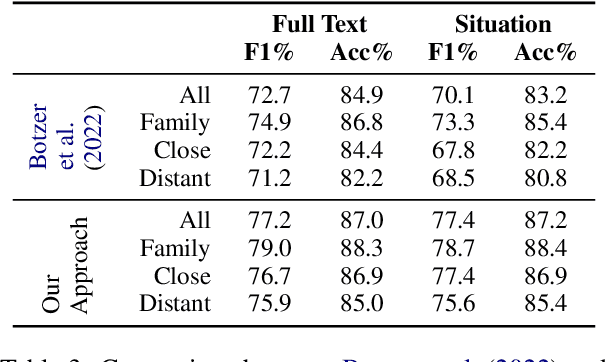
Medical diagnosis is the process of making a prediction of the disease a patient is likely to have, given a set of symptoms and observations. This requires extensive expert knowledge, in particular when covering a large variety of diseases. Such knowledge can be coded in a knowledge graph -- encompassing diseases, symptoms, and diagnosis paths. Since both the knowledge itself and its encoding can be incomplete, refining the knowledge graph with additional information helps physicians making better predictions. At the same time, for deployment in a hospital, the diagnosis must be explainable and transparent. In this paper, we present an approach using diagnosis paths in a medical knowledge graph. We show that those graphs can be refined using latent representations with RDF2vec, while the final diagnosis is still made in an explainable way. Using both an intrinsic as well as an expert-based evaluation, we show that the embedding-based prediction approach is beneficial for refining the graph with additional valid conditions.
Perceived and Intended Sarcasm Detection with Graph Attention Networks
Oct 08, 2021



Existing sarcasm detection systems focus on exploiting linguistic markers, context, or user-level priors. However, social studies suggest that the relationship between the author and the audience can be equally relevant for the sarcasm usage and interpretation. In this work, we propose a framework jointly leveraging (1) a user context from their historical tweets together with (2) the social information from a user's conversational neighborhood in an interaction graph, to contextualize the interpretation of the post. We use graph attention networks (GAT) over users and tweets in a conversation thread, combined with dense user history representations. Apart from achieving state-of-the-art results on the recently published dataset of 19k Twitter users with 30K labeled tweets, adding 10M unlabeled tweets as context, our results indicate that the model contributes to interpreting the sarcastic intentions of an author more than to predicting the sarcasm perception by others.
Conversational Question Answering over Knowledge Graphs with Transformer and Graph Attention Networks
Apr 04, 2021
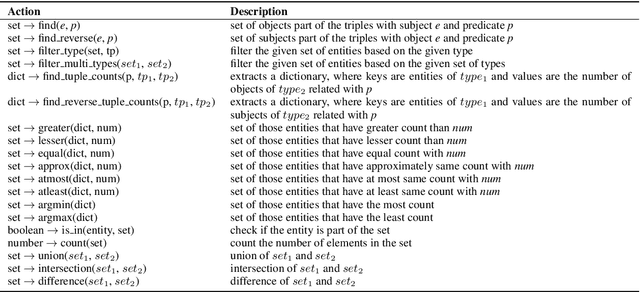
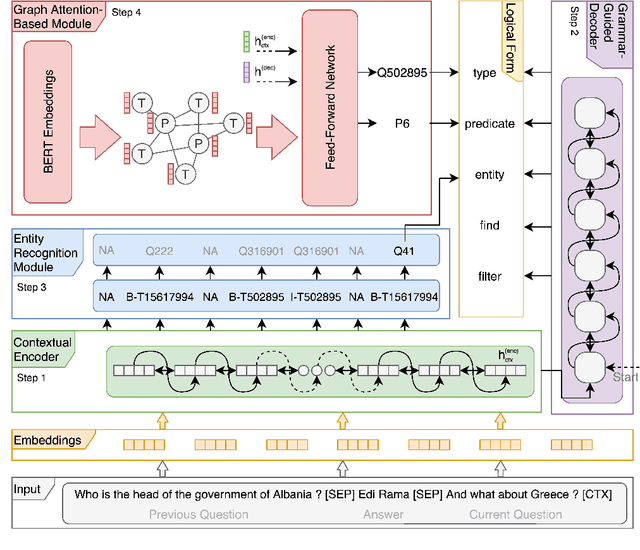
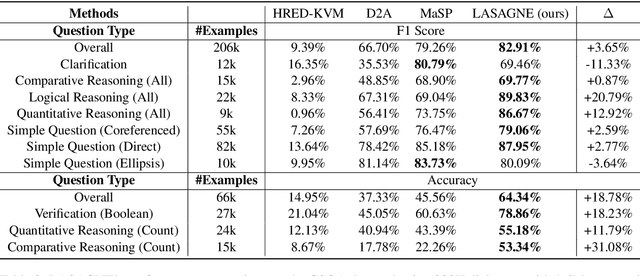
This paper addresses the task of (complex) conversational question answering over a knowledge graph. For this task, we propose LASAGNE (muLti-task semAntic parSing with trAnsformer and Graph atteNtion nEtworks). It is the first approach, which employs a transformer architecture extended with Graph Attention Networks for multi-task neural semantic parsing. LASAGNE uses a transformer model for generating the base logical forms, while the Graph Attention model is used to exploit correlations between (entity) types and predicates to produce node representations. LASAGNE also includes a novel entity recognition module which detects, links, and ranks all relevant entities in the question context. We evaluate LASAGNE on a standard dataset for complex sequential question answering, on which it outperforms existing baseline averages on all question types. Specifically, we show that LASAGNE improves the F1-score on eight out of ten question types; in some cases, the increase in F1-score is more than 20% compared to the state of the art.
Context Transformer with Stacked Pointer Networks for Conversational Question Answering over Knowledge Graphs
Mar 13, 2021
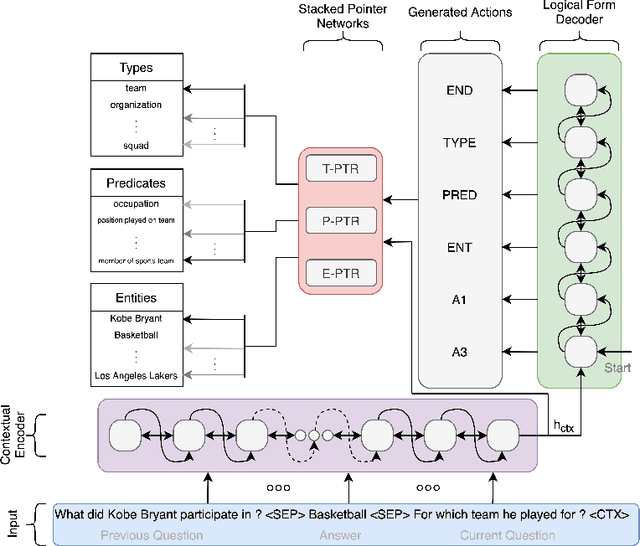
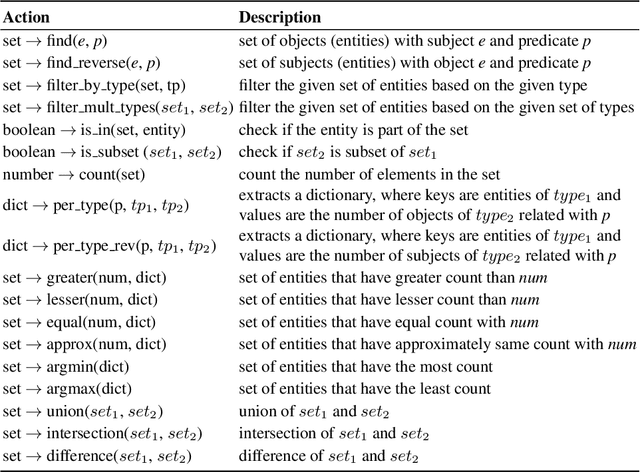
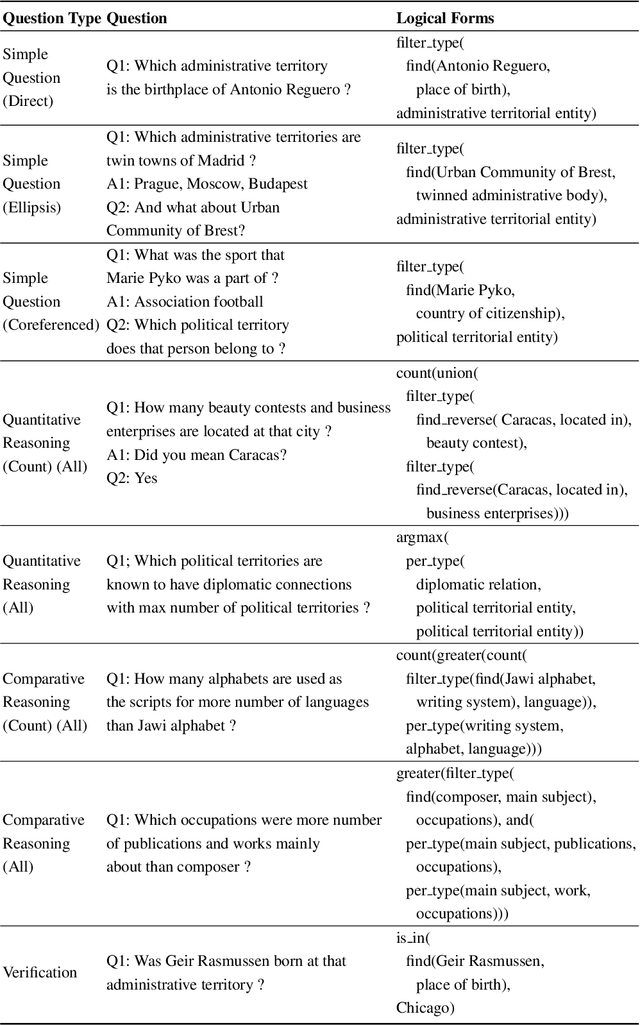
Neural semantic parsing approaches have been widely used for Question Answering (QA) systems over knowledge graphs. Such methods provide the flexibility to handle QA datasets with complex queries and a large number of entities. In this work, we propose a novel framework named CARTON, which performs multi-task semantic parsing for handling the problem of conversational question answering over a large-scale knowledge graph. Our framework consists of a stack of pointer networks as an extension of a context transformer model for parsing the input question and the dialog history. The framework generates a sequence of actions that can be executed on the knowledge graph. We evaluate CARTON on a standard dataset for complex sequential question answering on which CARTON outperforms all baselines. Specifically, we observe performance improvements in F1-score on eight out of ten question types compared to the previous state of the art. For logical reasoning questions, an improvement of 11 absolute points is reached.