 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLM Agents Identify Spoken Dialects like a Linguist?
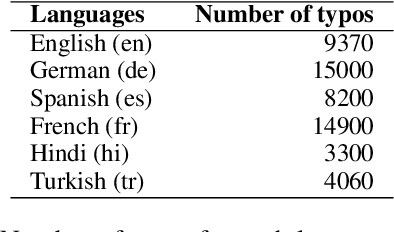
Mar 31, 2026Due to the scarcity of labeled dialectal speech, audio dialect classification is a challenging task for most languages, including Swiss German. In this work, we explore the ability of large language models (LLMs) as agents in understanding the dialects and whether they can show comparable performance to models such as HuBERT in dialect classification. In addition, we provide an LLM baseline and a human linguist one. Our approach uses phonetic transcriptions produced by ASR systems and combines them with linguistic resources such as dialect feature maps, vowel history, and rules. Our findings indicate that, when linguistic information is provided, the LLM predictions improve. The human baseline shows that automatically generated transcriptions can be beneficial for such classifications, but also presents opportunities for improvement.
Shapes are not enough: CONSERVAttack and its use for finding vulnerabilities and uncertainties in machine learning applications
Mar 14, 2026In High Energy Physics, as in many other fields of science, the application of machine learning techniques has been crucial in advancing our understanding of fundamental phenomena. Increasingly, deep learning models are applied to analyze both simulated and experimental data. In most experiments, a rigorous regime of testing for physically motivated systematic uncertainties is in place. The numerical evaluation of these tests for differences between the data on the one side and simulations on the other side quantifies the effect of potential sources of mismodelling on the machine learning output. In addition, thorough comparisons of marginal distributions and (linear) feature correlations between data and simulation in "control regions" are applied. However, the guidance by physical motivation, and the need to constrain comparisons to specific regions, does not guarantee that all possible sources of deviations have been accounted for. We therefore propose a new adversarial attack - the CONSERVAttack - designed to exploit the remaining space of hypothetical deviations between simulation and data after the above mentioned tests. The resulting adversarial perturbations are consistent within the uncertainty bounds - evading standard validation checks - while successfully fooling the underlying model. We further propose strategies to mitigate such vulnerabilities and argue that robustness to adversarial effects must be considered when interpreting results from deep learning in particle physics.
Label-Consistent Data Generation for Aspect-Based Sentiment Analysis Using LLM Agents
Feb 18, 2026We propose an agentic data augmentation method for Aspect-Based Sentiment Analysis (ABSA) that uses iterative generation and verification to produce high quality synthetic training examples. To isolate the effect of agentic structure, we also develop a closely matched prompting-based baseline using the same model and instructions. Both methods are evaluated across three ABSA subtasks (Aspect Term Extraction (ATE), Aspect Sentiment Classification (ATSC), and Aspect Sentiment Pair Extraction (ASPE)), four SemEval datasets, and two encoder-decoder models: T5-Base and Tk-Instruct. Our results show that the agentic augmentation outperforms raw prompting in label preservation of the augmented data, especially when the tasks require aspect term generation. In addition, when combined with real data, agentic augmentation provides higher gains, consistently outperforming prompting-based generation. These benefits are most pronounced for T5-Base, while the more heavily pretrained Tk-Instruct exhibits smaller improvements. As a result, augmented data helps T5-Base achieve comparable performance with its counterpart.
Encoder Fine-tuning with Stochastic Sampling Outperforms Open-weight GPT in Astronomy Knowledge Extraction
Nov 11, 2025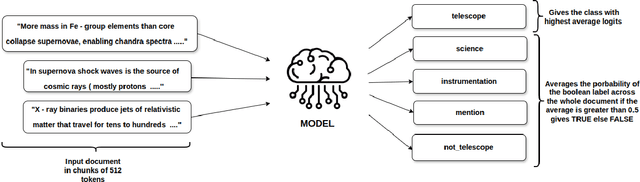

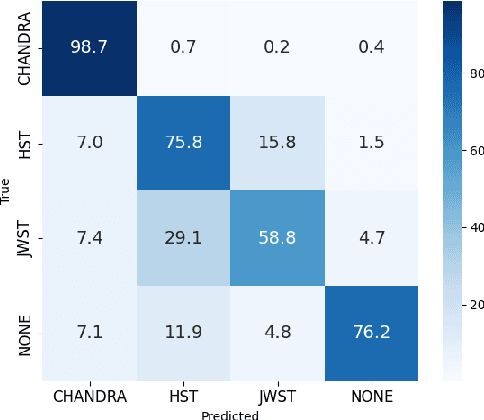
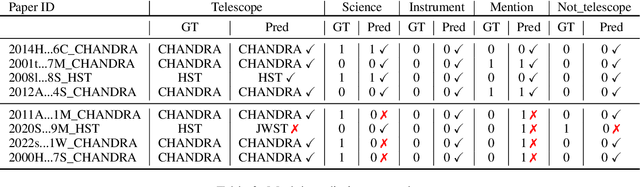
Scientific literature in astronomy is rapidly expanding, making it increasingly important to automate the extraction of key entities and contextual information from research papers. In this paper, we present an encoder-based system for extracting knowledge from astronomy articles. Our objective is to develop models capable of classifying telescope references, detecting auxiliary semantic attributes, and recognizing instrument mentions from textual content. To this end, we implement a multi-task transformer-based system built upon the SciBERT model and fine-tuned for astronomy corpora classification. To carry out the fine-tuning, we stochastically sample segments from the training data and use majority voting over the test segments at inference time. Our system, despite its simplicity and low-cost implementation, significantly outperforms the open-weight GPT baseline.
More Agents Helps but Adversarial Robustness Gap Persists
Nov 10, 2025When LLM agents work together, they seem to be more powerful than a single LLM in mathematical question answering. However, are they also more robust to adversarial inputs? We investigate this question using adversarially perturbed math questions. These perturbations include punctuation noise with three intensities (10, 30, and 50 percent), plus real-world and human-like typos (WikiTypo, R2ATA). Using a unified sampling-and-voting framework (Agent Forest), we evaluate six open-source models (Qwen3-4B/14B, Llama3.1-8B, Mistral-7B, Gemma3-4B/12B) across four benchmarks (GSM8K, MATH, MMLU-Math, MultiArith), with various numbers of agents n from one to 25 (1, 2, 5, 10, 15, 20, 25). Our findings show that (1) Noise type matters: punctuation noise harm scales with its severity, and the human typos remain the dominant bottleneck, yielding the largest gaps to Clean accuracy and the highest ASR even with a large number of agents. And (2) Collaboration reliably improves accuracy as the number of agents, n, increases, with the largest gains from one to five agents and diminishing returns beyond 10 agents. However, the adversarial robustness gap persists regardless of the agent count.
Exploring Robustness of LLMs to Sociodemographically-Conditioned Paraphrasing
Jan 14, 2025Large Language Models (LLMs) have shown impressive performance in various NLP tasks. However, there are concerns about their reliability in different domains of linguistic variations. Many works have proposed robustness evaluation measures for local adversarial attacks, but we need globally robust models unbiased to different language styles. We take a broader approach to explore a wider range of variations across sociodemographic dimensions to perform structured reliability tests on the reasoning capacity of language models. We extend the SocialIQA dataset to create diverse paraphrased sets conditioned on sociodemographic styles. The assessment aims to provide a deeper understanding of LLMs in (a) their capability of generating demographic paraphrases with engineered prompts and (b) their reasoning capabilities in real-world, complex language scenarios. We also explore measures such as perplexity, explainability, and ATOMIC performance of paraphrases for fine-grained reliability analysis of LLMs on these sets. We find that demographic-specific paraphrasing significantly impacts the performance of language models, indicating that the subtleties of language variations remain a significant challenge. The code and dataset will be made available for reproducibility and future research.
Exploring Robustness of Multilingual LLMs on Real-World Noisy Data
Jan 14, 2025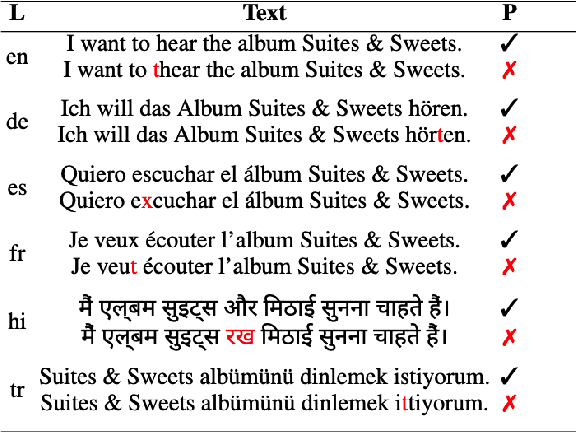
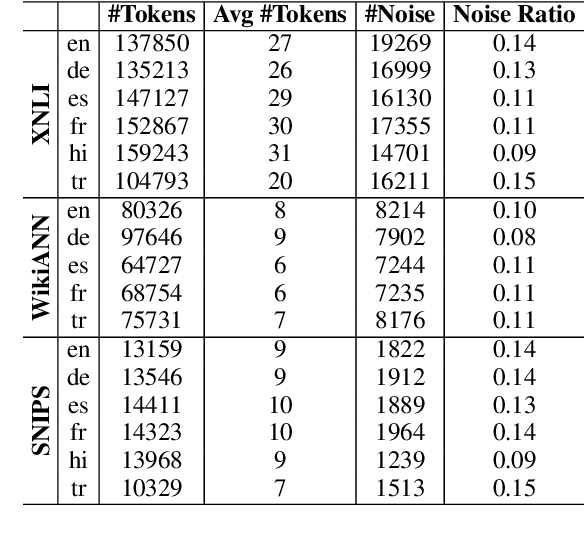
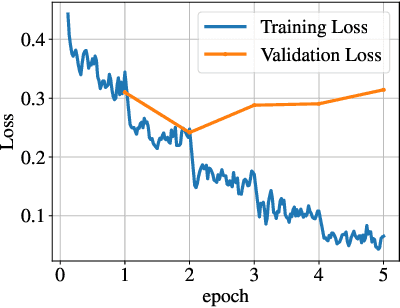
Large Language Models (LLMs) are trained on Web data that might contain spelling errors made by humans. But do they become robust to similar real-world noise? In this paper, we investigate the effect of real-world spelling mistakes on the performance of 9 language models, with parameters ranging from 0.2B to 13B, in 3 different NLP tasks, namely Natural Language Inference (NLI), Name Entity Recognition (NER), and Intent Classification (IC). We perform our experiments on 6 different languages and build a dictionary of real-world noise for them using the Wikipedia edit history. We show that the performance gap of the studied models on the clean and noisy test data averaged across all the datasets and languages ranges from 2.3 to 4.3 absolute percentage points. In addition, mT5 models, in general, show more robustness compared to BLOOM, Falcon, and BERT-like models. In particular, mT5 (13B), was the most robust on average overall, across the 3 tasks, and in 4 of the 6 languages.
ArithmAttack: Evaluating Robustness of LLMs to Noisy Context in Math Problem Solving
Jan 14, 2025



While Large Language Models (LLMs) have shown impressive capabilities in math problem-solving tasks, their robustness to noisy inputs is not well-studied. In this work, we propose ArithmAttack to examine how robust the LLMs are when they encounter noisy prompts that contain extra noise in the form of punctuation marks. While being easy to implement, ArithmAttack does not cause any information loss since words are not added or deleted from the context. We evaluate the robustness of seven LLMs, including LLama3, Mistral, and Mathstral, on noisy GSM8K and MultiArith datasets. Our experiments suggest that all the studied models show vulnerability to such noise, with more noise leading to poorer performances.
Enforcing Fundamental Relations via Adversarial Attacks on Input Parameter Correlations
Jan 09, 2025Correlations between input parameters play a crucial role in many scientific classification tasks, since these are often related to fundamental laws of nature. For example, in high energy physics, one of the common deep learning use-cases is the classification of signal and background processes in particle collisions. In many such cases, the fundamental principles of the correlations between observables are often better understood than the actual distributions of the observables themselves. In this work, we present a new adversarial attack algorithm called Random Distribution Shuffle Attack (RDSA), emphasizing the correlations between observables in the network rather than individual feature characteristics. Correct application of the proposed novel attack can result in a significant improvement in classification performance - particularly in the context of data augmentation - when using the generated adversaries within adversarial training. Given that correlations between input features are also crucial in many other disciplines. We demonstrate the RDSA effectiveness on six classification tasks, including two particle collision challenges (using CERN Open Data), hand-written digit recognition (MNIST784), human activity recognition (HAR), weather forecasting (Rain in Australia), and ICU patient mortality (MIMIC-IV), demonstrating a general use case beyond fundamental physics for this new type of adversarial attack algorithms.
Do Multilingual Large Language Models Mitigate Stereotype Bias?
Jul 09, 2024



While preliminary findings indicate that multilingual LLMs exhibit reduced bias compared to monolingual ones, a comprehensive understanding of the effect of multilingual training on bias mitigation, is lacking. This study addresses this gap by systematically training six LLMs of identical size (2.6B parameters) and architecture: five monolingual models (English, German, French, Italian, and Spanish) and one multilingual model trained on an equal distribution of data across these languages, all using publicly available data. To ensure robust evaluation, standard bias benchmarks were automatically translated into the five target languages and verified for both translation quality and bias preservation by human annotators. Our results consistently demonstrate that multilingual training effectively mitigates bias. Moreover, we observe that multilingual models achieve not only lower bias but also superior prediction accuracy when compared to monolingual models with the same amount of training data, model architecture, and size.