 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAEDA: An Easier Data Augmentation Technique for Text Classification
Paper and Code
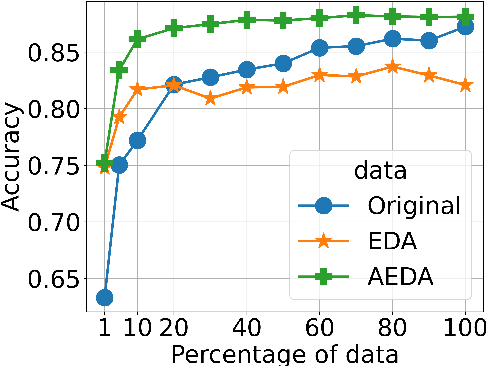
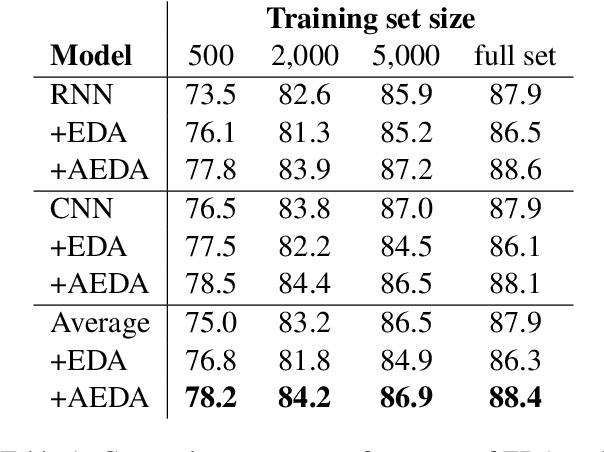

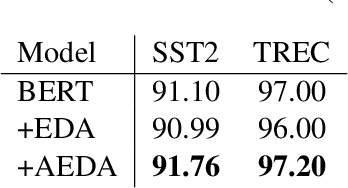
This paper proposes AEDA (An Easier Data Augmentation) technique to help improve the performance on text classification tasks. AEDA includes only random insertion of punctuation marks into the original text. This is an easier technique to implement for data augmentation than EDA method (Wei and Zou, 2019) with which we compare our results. In addition, it keeps the order of the words while changing their positions in the sentence leading to a better generalized performance. Furthermore, the deletion operation in EDA can cause loss of information which, in turn, misleads the network, whereas AEDA preserves all the input information. Following the baseline, we perform experiments on five different datasets for text classification. We show that using the AEDA-augmented data for training, the models show superior performance compared to using the EDA-augmented data in all five datasets. The source code is available for further study and reproduction of the results.