 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Proposed Paradigm for Imputing Missing Multi-Sensor Data in the Healthcare Domain
Jan 07, 2026Chronic diseases such as diabetes pose significant management challenges, particularly due to the risk of complications like hypoglycemia, which require timely detection and intervention. Continuous health monitoring through wearable sensors offers a promising solution for early prediction of glycemic events. However, effective use of multisensor data is hindered by issues such as signal noise and frequent missing values. This study examines the limitations of existing datasets and emphasizes the temporal characteristics of key features relevant to hypoglycemia prediction. A comprehensive analysis of imputation techniques is conducted, focusing on those employed in state-of-the-art studies. Furthermore, imputation methods derived from machine learning and deep learning applications in other healthcare contexts are evaluated for their potential to address longer gaps in time-series data. Based on this analysis, a systematic paradigm is proposed, wherein imputation strategies are tailored to the nature of specific features and the duration of missing intervals. The review concludes by emphasizing the importance of investigating the temporal dynamics of individual features and the implementation of multiple, feature-specific imputation techniques to effectively address heterogeneous temporal patterns inherent in the data.
* 21 Pages, 6 Figures, 7 Tables
Laplace-Net: Learning Dynamical Systems with External Forcing
Mar 17, 2025Modelling forced dynamical systems - where an external input drives the system state - is critical across diverse domains such as engineering, finance, and the natural sciences. In this work, we propose Laplace-Net, a decoupled, solver-free neural framework for learning forced and delay-aware systems. It leverages a Laplace transform-based approach to decompose internal dynamics, external inputs, and initial values into established theoretical concepts, enhancing interpretability. Laplace-Net promotes transferability since the system can be rapidly re-trained or fine-tuned for new forcing signals, providing flexibility in applications ranging from controller adaptation to long-horizon forecasting. Experimental results on eight benchmark datasets - including linear, non-linear, and delayed systems - demonstrate the method's improved accuracy and robustness compared to state-of-the-art approaches, particularly in handling complex and previously unseen inputs.
Contrastive Representation Learning for Conversational Question Answering over Knowledge Graphs
Oct 09, 2022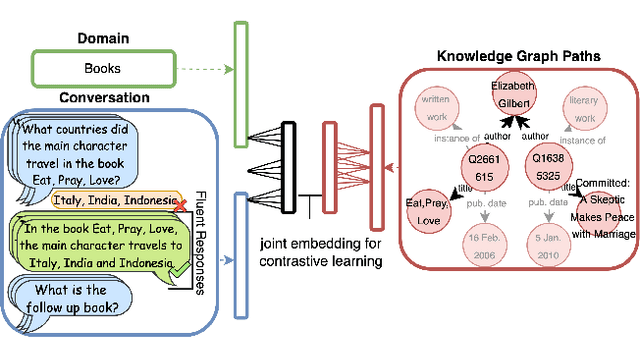
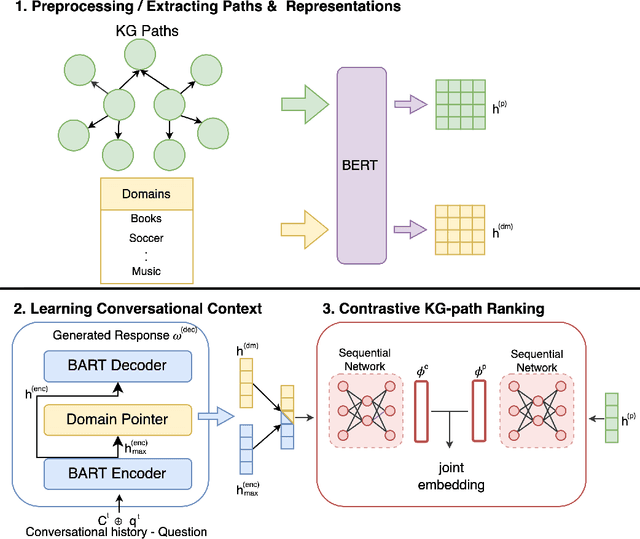
This paper addresses the task of conversational question answering (ConvQA) over knowledge graphs (KGs). The majority of existing ConvQA methods rely on full supervision signals with a strict assumption of the availability of gold logical forms of queries to extract answers from the KG. However, creating such a gold logical form is not viable for each potential question in a real-world scenario. Hence, in the case of missing gold logical forms, the existing information retrieval-based approaches use weak supervision via heuristics or reinforcement learning, formulating ConvQA as a KG path ranking problem. Despite missing gold logical forms, an abundance of conversational contexts, such as entire dialog history with fluent responses and domain information, can be incorporated to effectively reach the correct KG path. This work proposes a contrastive representation learning-based approach to rank KG paths effectively. Our approach solves two key challenges. Firstly, it allows weak supervision-based learning that omits the necessity of gold annotations. Second, it incorporates the conversational context (entire dialog history and domain information) to jointly learn its homogeneous representation with KG paths to improve contrastive representations for effective path ranking. We evaluate our approach on standard datasets for ConvQA, on which it significantly outperforms existing baselines on all domains and overall. Specifically, in some cases, the Mean Reciprocal Rank (MRR) and Hit@5 ranking metrics improve by absolute 10 and 18 points, respectively, compared to the state-of-the-art performance.
An Answer Verbalization Dataset for Conversational Question Answerings over Knowledge Graphs
Aug 13, 2022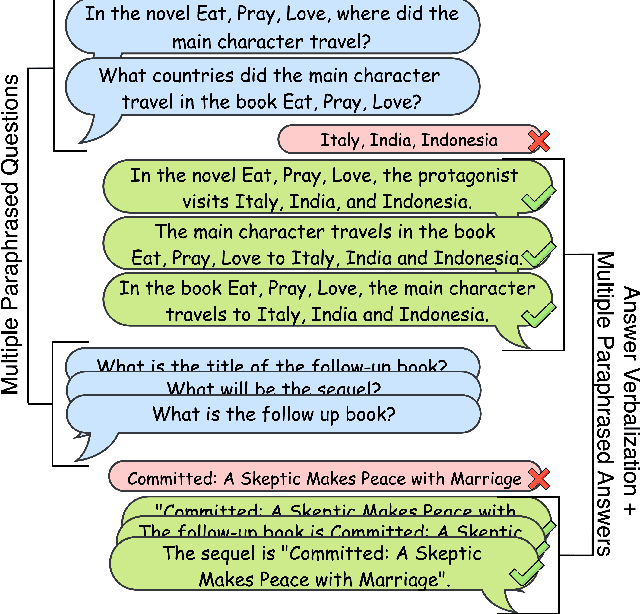

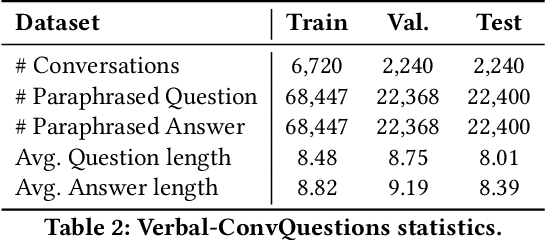
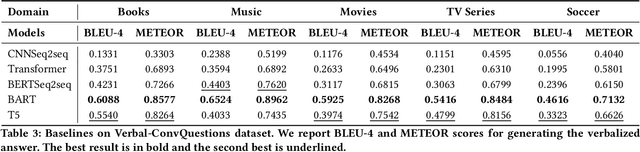
We introduce a new dataset for conversational question answering over Knowledge Graphs (KGs) with verbalized answers. Question answering over KGs is currently focused on answer generation for single-turn questions (KGQA) or multiple-tun conversational question answering (ConvQA). However, in a real-world scenario (e.g., voice assistants such as Siri, Alexa, and Google Assistant), users prefer verbalized answers. This paper contributes to the state-of-the-art by extending an existing ConvQA dataset with multiple paraphrased verbalized answers. We perform experiments with five sequence-to-sequence models on generating answer responses while maintaining grammatical correctness. We additionally perform an error analysis that details the rates of models' mispredictions in specified categories. Our proposed dataset extended with answer verbalization is publicly available with detailed documentation on its usage for wider utility.
VOGUE: Answer Verbalization through Multi-Task Learning
Jun 28, 2021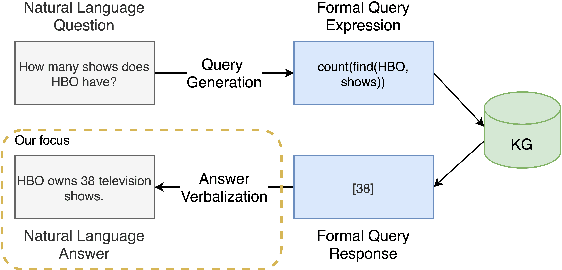
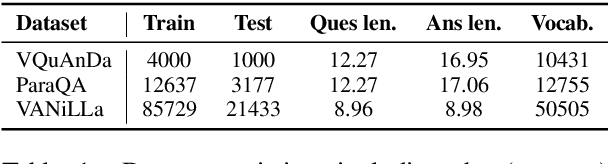
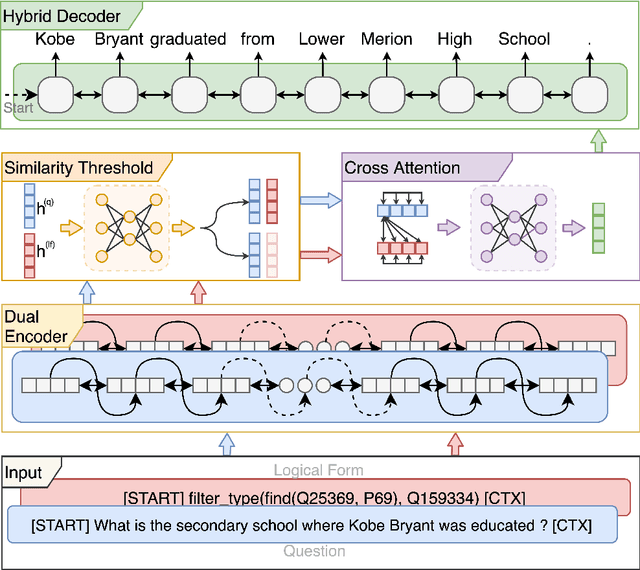
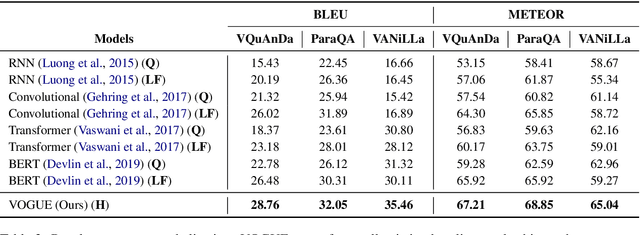
In recent years, there have been significant developments in Question Answering over Knowledge Graphs (KGQA). Despite all the notable advancements, current KGQA systems only focus on answer generation techniques and not on answer verbalization. However, in real-world scenarios (e.g., voice assistants such as Alexa, Siri, etc.), users prefer verbalized answers instead of a generated response. This paper addresses the task of answer verbalization for (complex) question answering over knowledge graphs. In this context, we propose a multi-task-based answer verbalization framework: VOGUE (Verbalization thrOuGh mUlti-task lEarning). The VOGUE framework attempts to generate a verbalized answer using a hybrid approach through a multi-task learning paradigm. Our framework can generate results based on using questions and queries as inputs concurrently. VOGUE comprises four modules that are trained simultaneously through multi-task learning. We evaluate our framework on existing datasets for answer verbalization, and it outperforms all current baselines on both BLEU and METEOR scores.
Conversational Question Answering over Knowledge Graphs with Transformer and Graph Attention Networks
Apr 04, 2021
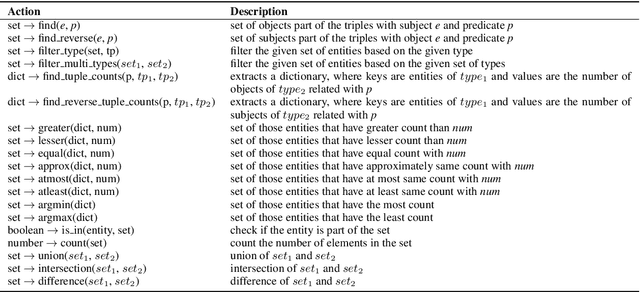
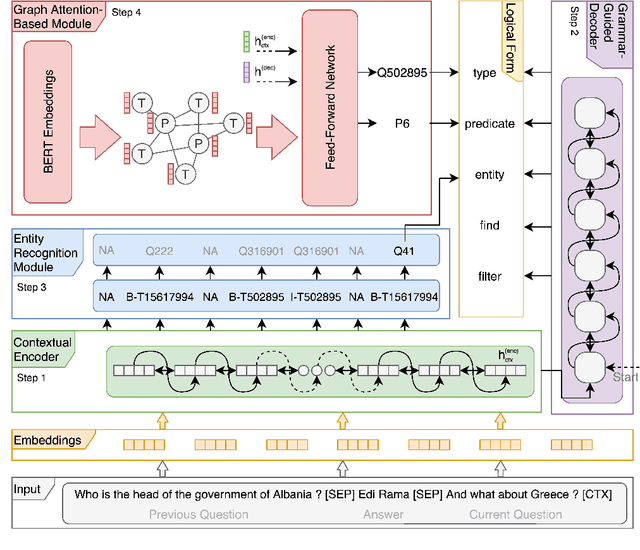
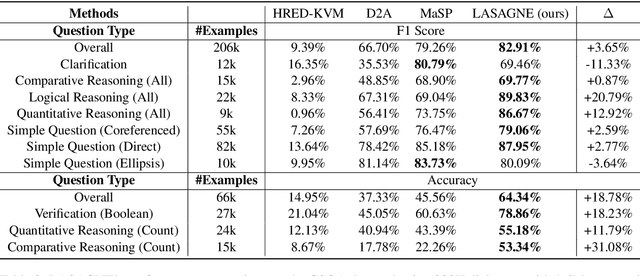
This paper addresses the task of (complex) conversational question answering over a knowledge graph. For this task, we propose LASAGNE (muLti-task semAntic parSing with trAnsformer and Graph atteNtion nEtworks). It is the first approach, which employs a transformer architecture extended with Graph Attention Networks for multi-task neural semantic parsing. LASAGNE uses a transformer model for generating the base logical forms, while the Graph Attention model is used to exploit correlations between (entity) types and predicates to produce node representations. LASAGNE also includes a novel entity recognition module which detects, links, and ranks all relevant entities in the question context. We evaluate LASAGNE on a standard dataset for complex sequential question answering, on which it outperforms existing baseline averages on all question types. Specifically, we show that LASAGNE improves the F1-score on eight out of ten question types; in some cases, the increase in F1-score is more than 20% compared to the state of the art.
Demographic Aware Probabilistic Medical Knowledge Graph Embeddings of Electronic Medical Records
Apr 03, 2021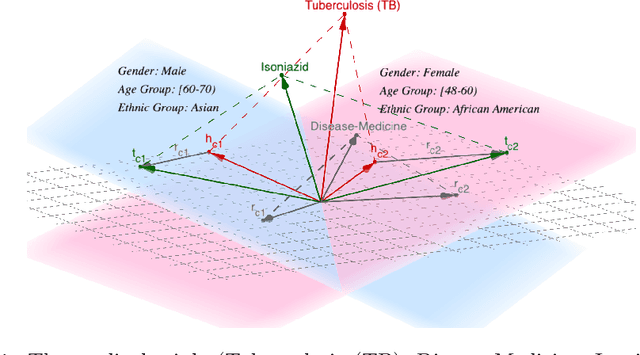
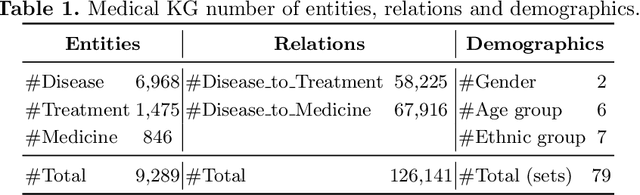
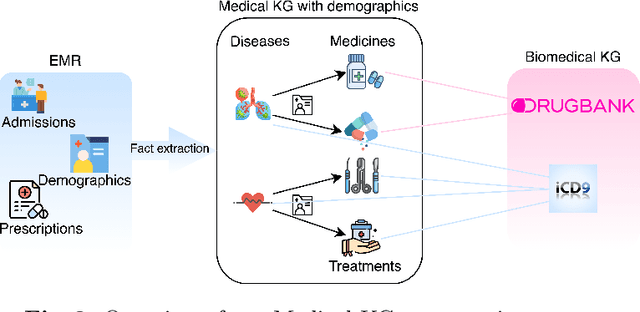
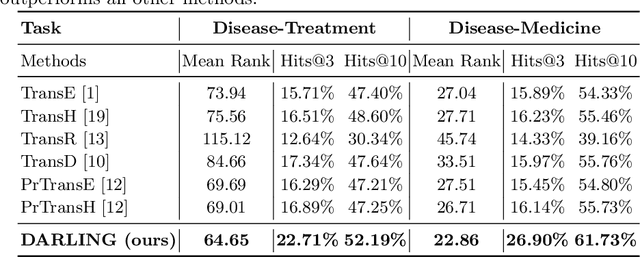
Medical knowledge graphs (KGs) constructed from Electronic Medical Records (EMR) contain abundant information about patients and medical entities. The utilization of KG embedding models on these data has proven to be efficient for different medical tasks. However, existing models do not properly incorporate patient demographics and most of them ignore the probabilistic features of the medical KG. In this paper, we propose DARLING (Demographic Aware pRobabiListic medIcal kNowledge embeddinG), a demographic-aware medical KG embedding framework that explicitly incorporates demographics in the medical entities space by associating patient demographics with a corresponding hyperplane. Our framework leverages the probabilistic features within the medical entities for learning their representations through demographic guidance. We evaluate DARLING through link prediction for treatments and medicines, on a medical KG constructed from EMR data, and illustrate its superior performance compared to existing KG embedding models.
MLM: A Benchmark Dataset for Multitask Learning with Multiple Languages and Modalities
Sep 04, 2020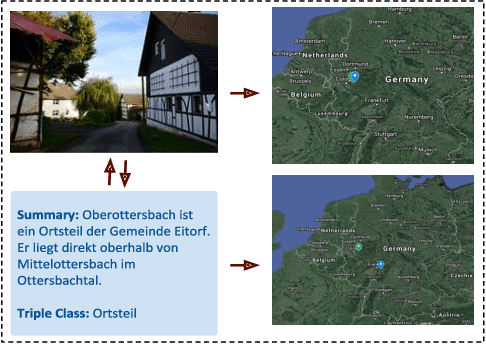
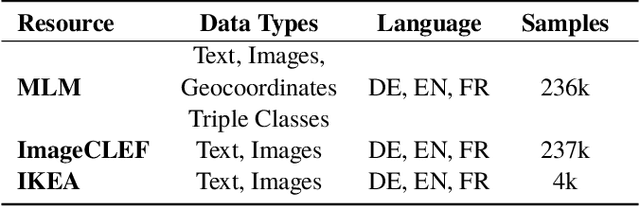
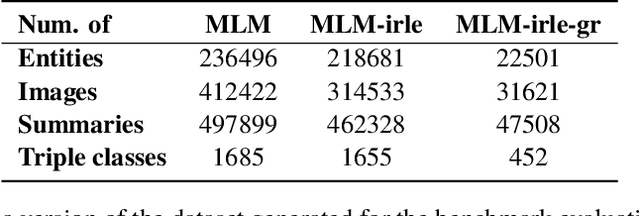
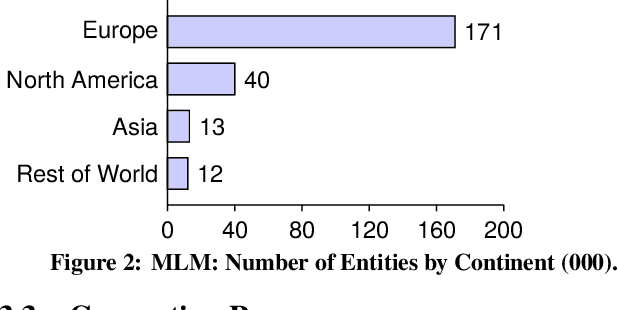
In this paper, we introduce the MLM (Multiple Languages and Modalities) dataset - a new resource to train and evaluate multitask systems on samples in multiple modalities and three languages. The generation process and inclusion of semantic data provide a resource that further tests the ability for multitask systems to learn relationships between entities. The dataset is designed for researchers and developers who build applications that perform multiple tasks on data encountered on the web and in digital archives. A second version of MLM provides a geo-representative subset of the data with weighted samples for countries of the European Union. We demonstrate the value of the resource in developing novel applications in the digital humanities with a motivating use case and specify a benchmark set of tasks to retrieve modalities and locate entities in the dataset. Evaluation of baseline multitask and single task systems on the full and geo-representative versions of MLM demonstrate the challenges of generalising on diverse data. In addition to the digital humanities, we expect the resource to contribute to research in multimodal representation learning, location estimation, and scene understanding.
Training Multimodal Systems for Classification with Multiple Objectives
Aug 26, 2020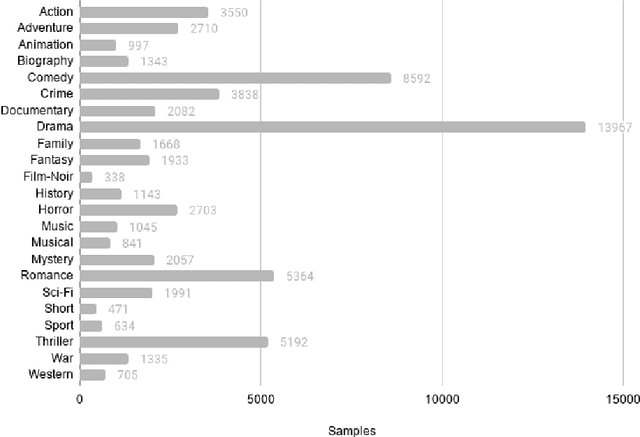

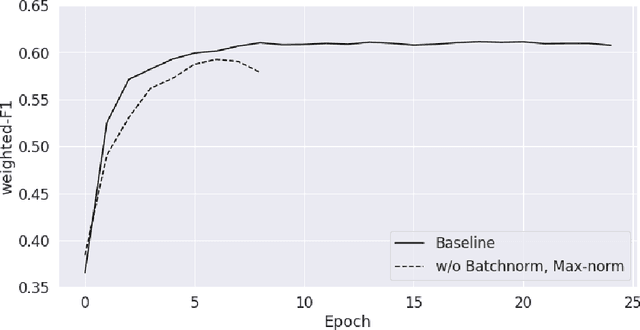
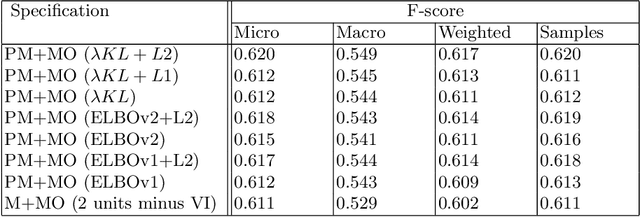
We learn about the world from a diverse range of sensory information. Automated systems lack this ability as investigation has centred on processing information presented in a single form. Adapting architectures to learn from multiple modalities creates the potential to learn rich representations of the world - but current multimodal systems only deliver marginal improvements on unimodal approaches. Neural networks learn sampling noise during training with the result that performance on unseen data is degraded. This research introduces a second objective over the multimodal fusion process learned with variational inference. Regularisation methods are implemented in the inner training loop to control variance and the modular structure stabilises performance as additional neurons are added to layers. This framework is evaluated on a multilabel classification task with textual and visual inputs to demonstrate the potential for multiple objectives and probabilistic methods to lower variance and improve generalisation.
The Semantic Asset Administration Shell
Sep 02, 2019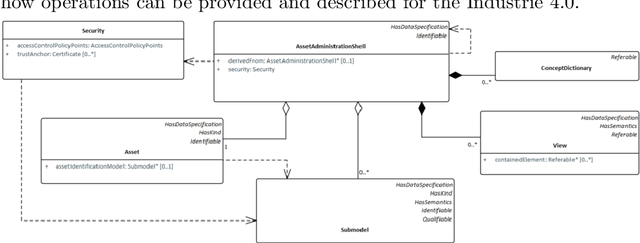



The disruptive potential of the upcoming digital transformations for the industrial manufacturing domain have led to several reference frameworks and numerous standardization approaches. On the other hand, the Semantic Web community has made significant contributions in the field, for instance on data and service description, integration of heterogeneous sources and devices, and AI techniques in distributed systems. These two streams of work are, however, mostly unrelated and only briefly regard each others requirements, practices and terminology. We contribute to closing this gap by providing the Semantic Asset Administration Shell, an RDF-based representation of the Industrie 4.0 Component. We provide an ontology for the latest data model specification, created a RML mapping, supply resources to validate the RDF entities and introduce basic reasoning on the Asset Administration Shell data model. Furthermore, we discuss the different assumptions and presentation patterns, and analyze the implications of a semantic representation on the original data. We evaluate the thereby created overheads, and conclude that the semantic lifting is manageable, also for restricted or embedded devices, and therefore meets the needs of Industrie 4.0 scenarios.