 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVOGUE: Answer Verbalization through Multi-Task Learning
Jun 28, 2021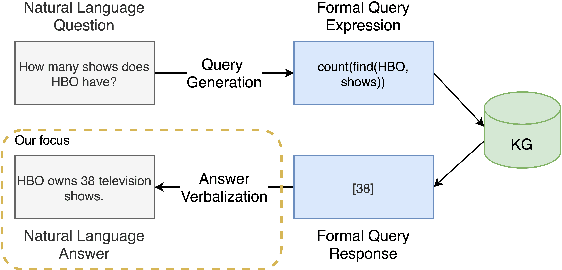
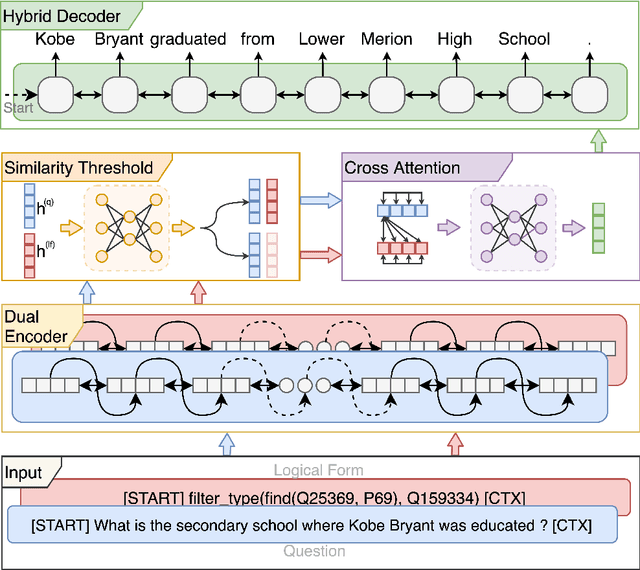
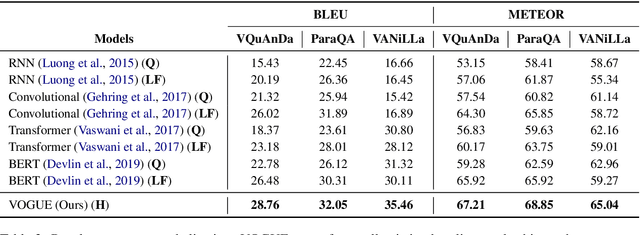
In recent years, there have been significant developments in Question Answering over Knowledge Graphs (KGQA). Despite all the notable advancements, current KGQA systems only focus on answer generation techniques and not on answer verbalization. However, in real-world scenarios (e.g., voice assistants such as Alexa, Siri, etc.), users prefer verbalized answers instead of a generated response. This paper addresses the task of answer verbalization for (complex) question answering over knowledge graphs. In this context, we propose a multi-task-based answer verbalization framework: VOGUE (Verbalization thrOuGh mUlti-task lEarning). The VOGUE framework attempts to generate a verbalized answer using a hybrid approach through a multi-task learning paradigm. Our framework can generate results based on using questions and queries as inputs concurrently. VOGUE comprises four modules that are trained simultaneously through multi-task learning. We evaluate our framework on existing datasets for answer verbalization, and it outperforms all current baselines on both BLEU and METEOR scores.