 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo and Language Alignment in 2D Systems for 3D Multi-object Scenes with Multi-Information Derivative-Free Control
Dec 31, 2025Cross-modal systems trained on 2D visual inputs are presented with a dimensional shift when processing 3D scenes. An in-scene camera bridges the dimensionality gap but requires learning a control module. We introduce a new method that improves multivariate mutual information estimates by regret minimisation with derivative-free optimisation. Our algorithm enables off-the-shelf cross-modal systems trained on 2D visual inputs to adapt online to object occlusions and differentiate features. The pairing of expressive measures and value-based optimisation assists control of an in-scene camera to learn directly from the noisy outputs of vision-language models. The resulting pipeline improves performance in cross-modal tasks on multi-object 3D scenes without resorting to pretraining or finetuning.
A Priority Map for Vision-and-Language Navigation with Trajectory Plans and Feature-Location Cues
Jul 24, 2022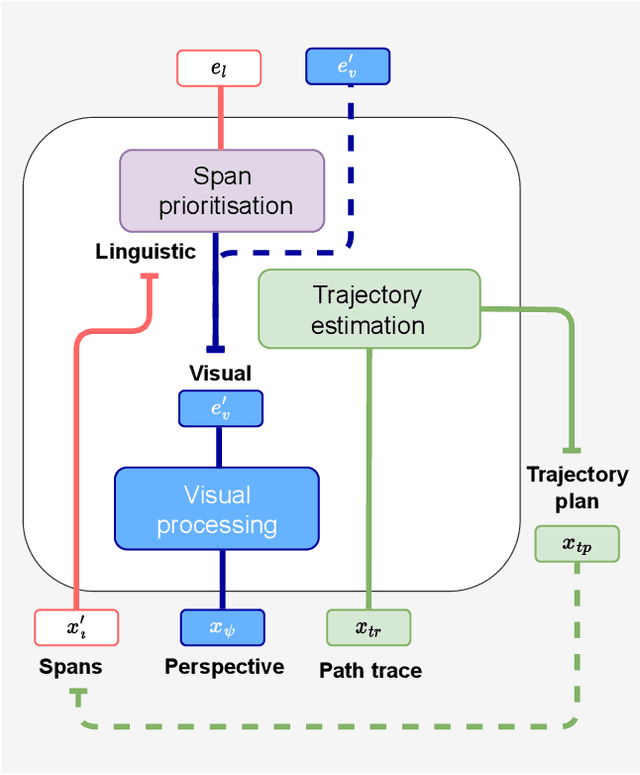
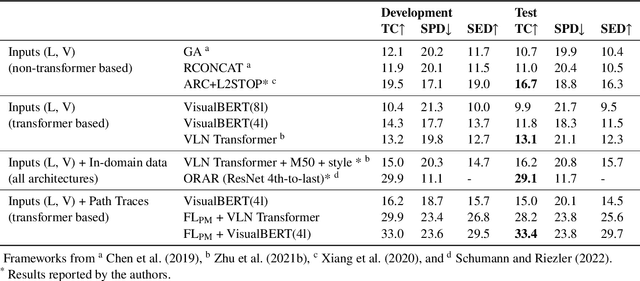
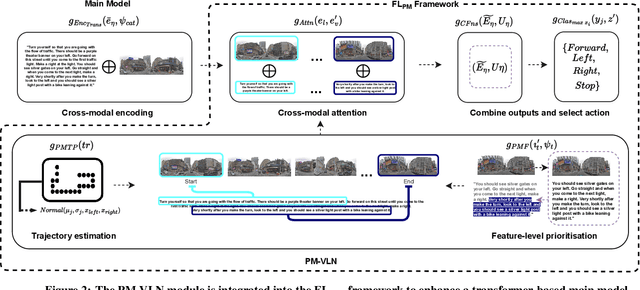
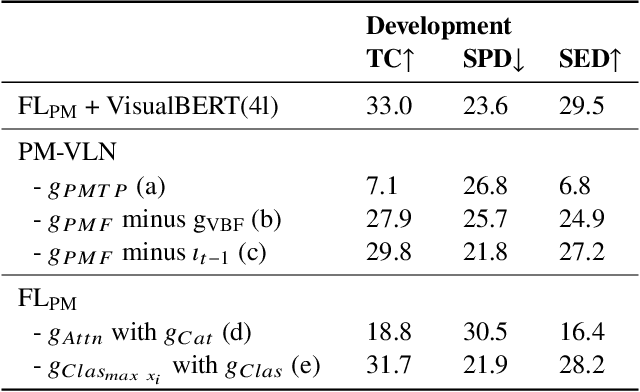
In a busy city street, a pedestrian surrounded by distractions can pick out a single sign if it is relevant to their route. Artificial agents in outdoor Vision-and-Language Navigation (VLN) are also confronted with detecting supervisory signal on environment features and location in inputs. To boost the prominence of relevant features in transformer-based architectures without costly preprocessing and pretraining, we take inspiration from priority maps - a mechanism described in neuropsychological studies. We implement a novel priority map module and pretrain on auxiliary tasks using low-sample datasets with high-level representations of routes and environment-related references to urban features. A hierarchical process of trajectory planning - with subsequent parameterised visual boost filtering on visual inputs and prediction of corresponding textual spans - addresses the core challenges of cross-modal alignment and feature-level localisation. The priority map module is integrated into a feature-location framework that doubles the task completion rates of standalone transformers and attains state-of-the-art performance on the Touchdown benchmark for VLN. Code and data are referenced in Appendix C.
MLM: A Benchmark Dataset for Multitask Learning with Multiple Languages and Modalities
Sep 04, 2020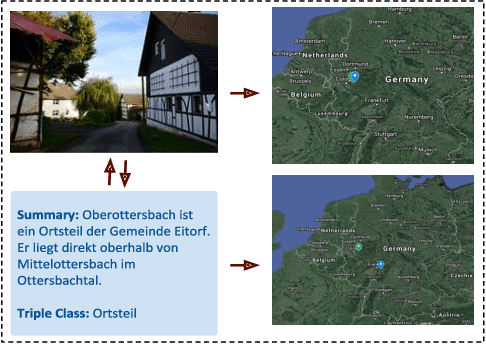
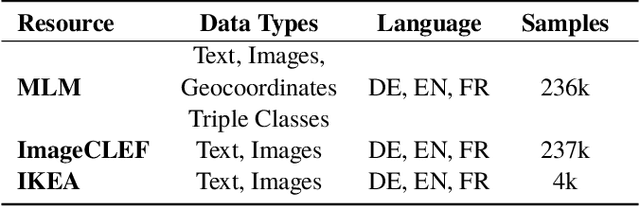
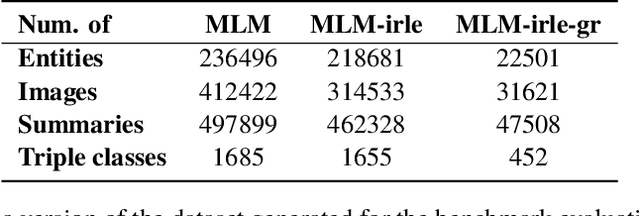
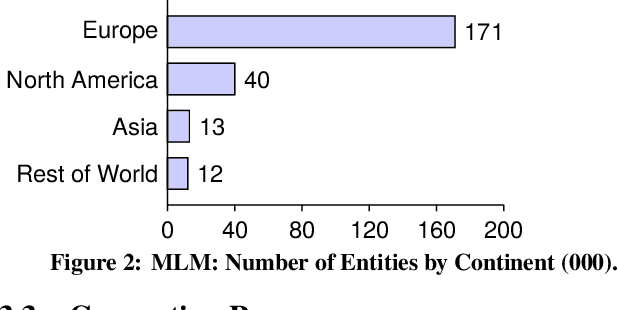
In this paper, we introduce the MLM (Multiple Languages and Modalities) dataset - a new resource to train and evaluate multitask systems on samples in multiple modalities and three languages. The generation process and inclusion of semantic data provide a resource that further tests the ability for multitask systems to learn relationships between entities. The dataset is designed for researchers and developers who build applications that perform multiple tasks on data encountered on the web and in digital archives. A second version of MLM provides a geo-representative subset of the data with weighted samples for countries of the European Union. We demonstrate the value of the resource in developing novel applications in the digital humanities with a motivating use case and specify a benchmark set of tasks to retrieve modalities and locate entities in the dataset. Evaluation of baseline multitask and single task systems on the full and geo-representative versions of MLM demonstrate the challenges of generalising on diverse data. In addition to the digital humanities, we expect the resource to contribute to research in multimodal representation learning, location estimation, and scene understanding.
Training Multimodal Systems for Classification with Multiple Objectives
Aug 26, 2020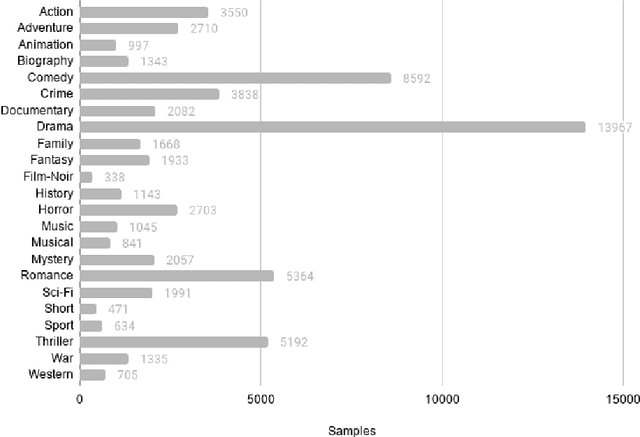

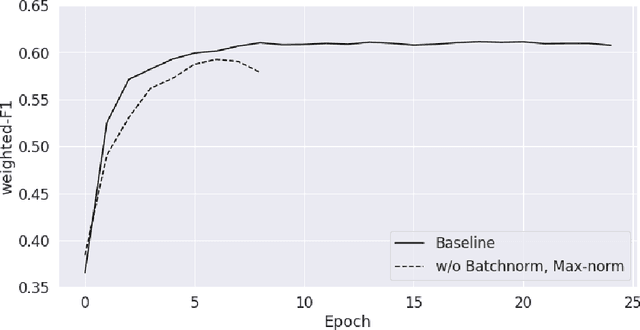
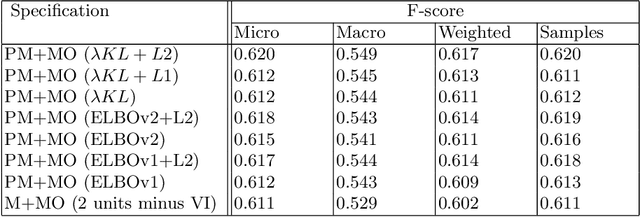
We learn about the world from a diverse range of sensory information. Automated systems lack this ability as investigation has centred on processing information presented in a single form. Adapting architectures to learn from multiple modalities creates the potential to learn rich representations of the world - but current multimodal systems only deliver marginal improvements on unimodal approaches. Neural networks learn sampling noise during training with the result that performance on unseen data is degraded. This research introduces a second objective over the multimodal fusion process learned with variational inference. Regularisation methods are implemented in the inner training loop to control variance and the modular structure stabilises performance as additional neurons are added to layers. This framework is evaluated on a multilabel classification task with textual and visual inputs to demonstrate the potential for multiple objectives and probabilistic methods to lower variance and improve generalisation.