 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Style and Content Transfer by Leveraging U-Net Skip Connections in Stable Diffusion 2.*
Jan 24, 2025


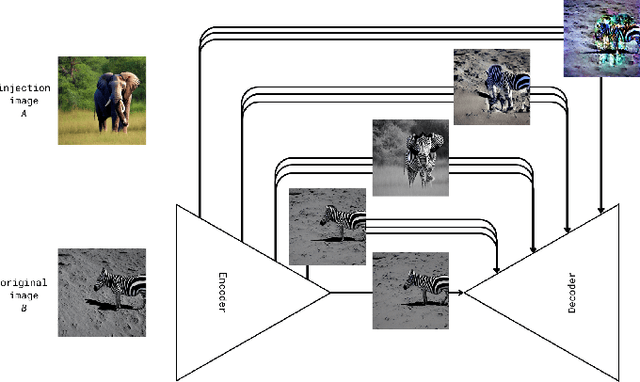
Despite significant recent advances in image generation with diffusion models, their internal latent representations remain poorly understood. Existing works focus on the bottleneck layer (h-space) of Stable Diffusion's U-Net or leverage the cross-attention, self-attention, or decoding layers. Our model, SkipInject takes advantage of U-Net's skip connections. We conduct thorough analyses on the role of the skip connections and find that the residual connections passed by the third encoder block carry most of the spatial information of the reconstructed image, splitting the content from the style. We show that injecting the representations from this block can be used for text-based editing, precise modifications, and style transfer. We compare our methods state-of-the-art style transfer and image editing methods and demonstrate that our method obtains the best content alignment and optimal structural preservation tradeoff.
There Is a Digital Art History
Aug 14, 2023In this paper, we revisit Johanna Drucker's question, "Is there a digital art history?" -- posed exactly a decade ago -- in the light of the emergence of large-scale, transformer-based vision models. While more traditional types of neural networks have long been part of digital art history, and digital humanities projects have recently begun to use transformer models, their epistemic implications and methodological affordances have not yet been systematically analyzed. We focus our analysis on two main aspects that, together, seem to suggest a coming paradigm shift towards a "digital" art history in Drucker's sense. On the one hand, the visual-cultural repertoire newly encoded in large-scale vision models has an outsized effect on digital art history. The inclusion of significant numbers of non-photographic images allows for the extraction and automation of different forms of visual logics. Large-scale vision models have "seen" large parts of the Western visual canon mediated by Net visual culture, and they continuously solidify and concretize this canon through their already widespread application in all aspects of digital life. On the other hand, based on two technical case studies of utilizing a contemporary large-scale visual model to investigate basic questions from the fields of art history and urbanism, we suggest that such systems require a new critical methodology that takes into account the epistemic entanglement of a model and its applications. This new methodology reads its corpora through a neural model's training data, and vice versa: the visual ideologies of research datasets and training datasets become entangled.
A Priority Map for Vision-and-Language Navigation with Trajectory Plans and Feature-Location Cues
Jul 24, 2022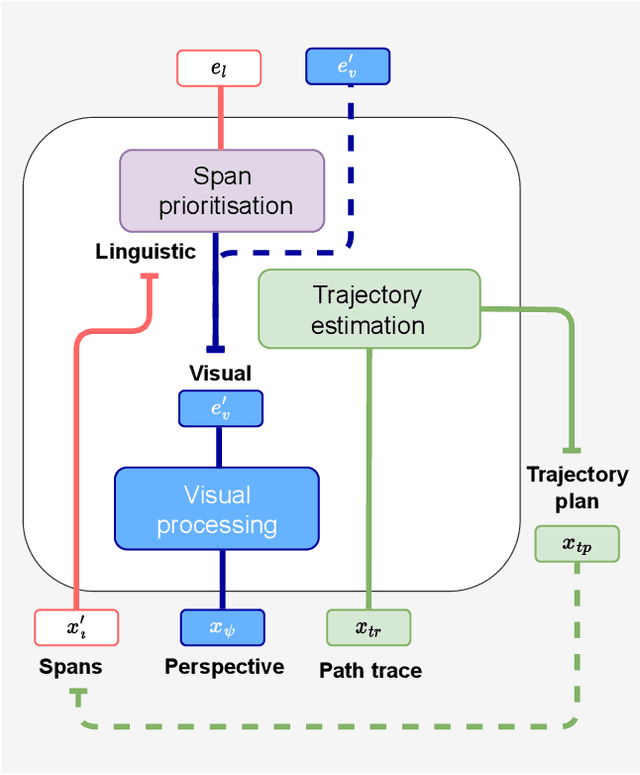
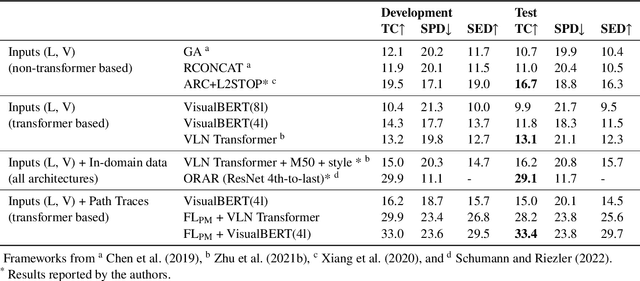
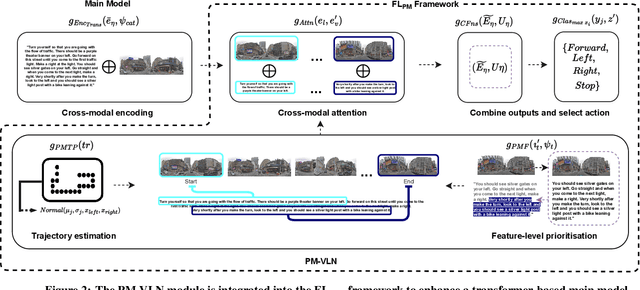
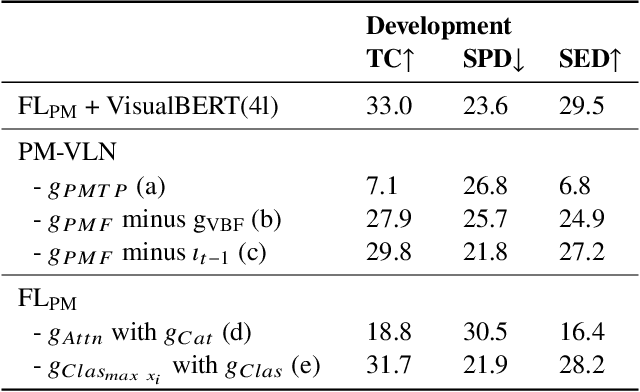
In a busy city street, a pedestrian surrounded by distractions can pick out a single sign if it is relevant to their route. Artificial agents in outdoor Vision-and-Language Navigation (VLN) are also confronted with detecting supervisory signal on environment features and location in inputs. To boost the prominence of relevant features in transformer-based architectures without costly preprocessing and pretraining, we take inspiration from priority maps - a mechanism described in neuropsychological studies. We implement a novel priority map module and pretrain on auxiliary tasks using low-sample datasets with high-level representations of routes and environment-related references to urban features. A hierarchical process of trajectory planning - with subsequent parameterised visual boost filtering on visual inputs and prediction of corresponding textual spans - addresses the core challenges of cross-modal alignment and feature-level localisation. The priority map module is integrated into a feature-location framework that doubles the task completion rates of standalone transformers and attains state-of-the-art performance on the Touchdown benchmark for VLN. Code and data are referenced in Appendix C.