 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLM: A Benchmark Dataset for Multitask Learning with Multiple Languages and Modalities
Paper and Code
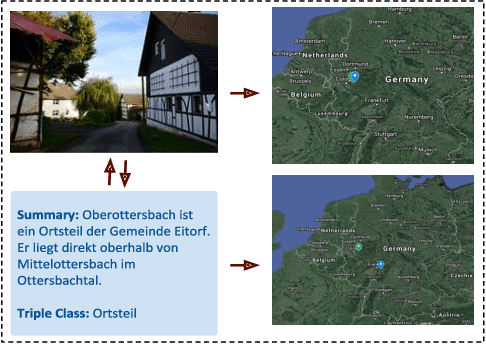
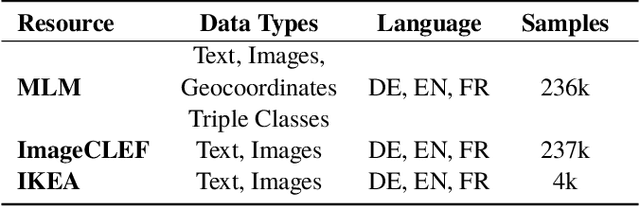
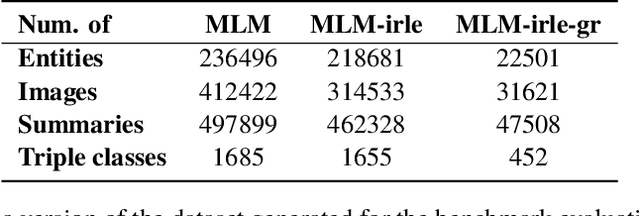
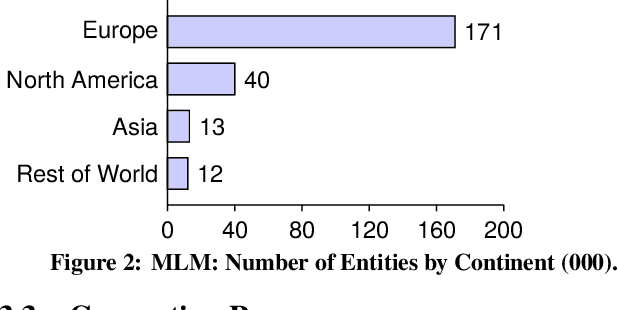
In this paper, we introduce the MLM (Multiple Languages and Modalities) dataset - a new resource to train and evaluate multitask systems on samples in multiple modalities and three languages. The generation process and inclusion of semantic data provide a resource that further tests the ability for multitask systems to learn relationships between entities. The dataset is designed for researchers and developers who build applications that perform multiple tasks on data encountered on the web and in digital archives. A second version of MLM provides a geo-representative subset of the data with weighted samples for countries of the European Union. We demonstrate the value of the resource in developing novel applications in the digital humanities with a motivating use case and specify a benchmark set of tasks to retrieve modalities and locate entities in the dataset. Evaluation of baseline multitask and single task systems on the full and geo-representative versions of MLM demonstrate the challenges of generalising on diverse data. In addition to the digital humanities, we expect the resource to contribute to research in multimodal representation learning, location estimation, and scene understanding.