 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOEKG: The Open Event Knowledge Graph
Feb 28, 2023



Accessing and understanding contemporary and historical events of global impact such as the US elections and the Olympic Games is a major prerequisite for cross-lingual event analytics that investigate event causes, perception and consequences across country borders. In this paper, we present the Open Event Knowledge Graph (OEKG), a multilingual, event-centric, temporal knowledge graph composed of seven different data sets from multiple application domains, including question answering, entity recommendation and named entity recognition. These data sets are all integrated through an easy-to-use and robust pipeline and by linking to the event-centric knowledge graph EventKG. We describe their common schema and demonstrate the use of the OEKG at the example of three use cases: type-specific image retrieval, hybrid question answering over knowledge graphs and news articles, as well as language-specific event recommendation. The OEKG and its query endpoint are publicly available.
MM-Locate-News: Multimodal Focus Location Estimation in News
Nov 15, 2022



The consumption of news has changed significantly as the Web has become the most influential medium for information. To analyze and contextualize the large amount of news published every day, the geographic focus of an article is an important aspect in order to enable content-based news retrieval. There are methods and datasets for geolocation estimation from text or photos, but they are typically considered as separate tasks. However, the photo might lack geographical cues and text can include multiple locations, making it challenging to recognize the focus location using a single modality. In this paper, a novel dataset called Multimodal Focus Location of News (MM-Locate-News) is introduced. We evaluate state-of-the-art methods on the new benchmark dataset and suggest novel models to predict the focus location of news using both textual and image content. The experimental results show that the multimodal model outperforms unimodal models.
GeoWINE: Geolocation based Wiki, Image,News and Event Retrieval
May 04, 2021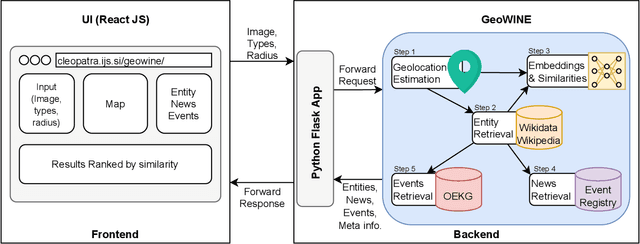

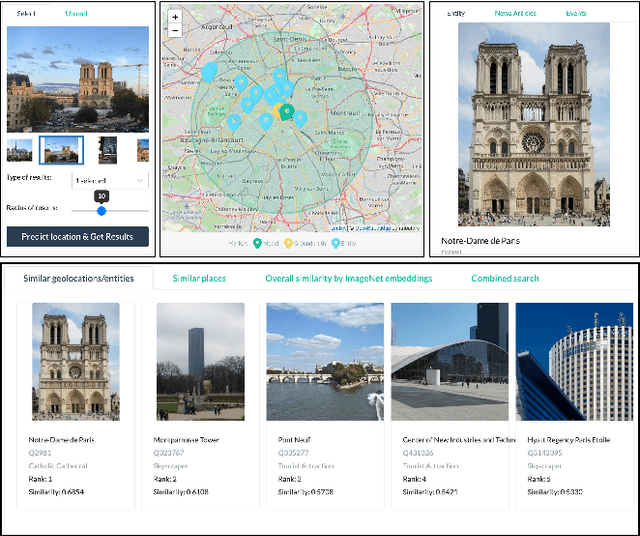
In the context of social media, geolocation inference on news or events has become a very important task. In this paper, we present the GeoWINE (Geolocation-based Wiki-Image-News-Event retrieval) demonstrator, an effective modular system for multimodal retrieval which expects only a single image as input. The GeoWINE system consists of five modules in order to retrieve related information from various sources. The first module is a state-of-the-art model for geolocation estimation of images. The second module performs a geospatial-based query for entity retrieval using the Wikidata knowledge graph. The third module exploits four different image embedding representations, which are used to retrieve most similar entities compared to the input image. The embeddings are derived from the tasks of geolocation estimation, place recognition, ImageNet-based image classification, and their combination. The last two modules perform news and event retrieval from EventRegistry and the Open Event Knowledge Graph (OEKG). GeoWINE provides an intuitive interface for end-users and is insightful for experts for reconfiguration to individual setups. The GeoWINE achieves promising results in entity label prediction for images on Google Landmarks dataset. The demonstrator is publicly available at http://cleopatra.ijs.si/geowine/.
MLM: A Benchmark Dataset for Multitask Learning with Multiple Languages and Modalities
Sep 04, 2020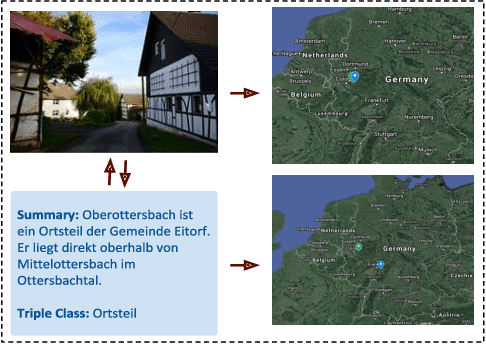
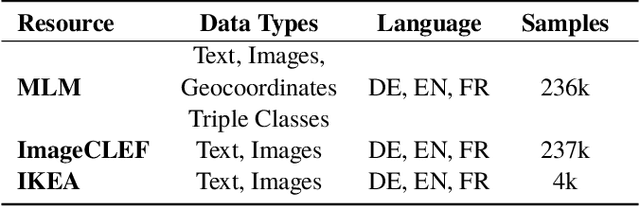
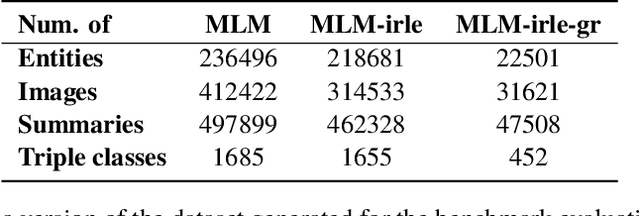
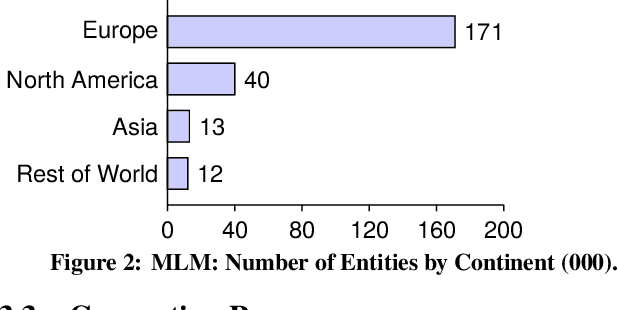
In this paper, we introduce the MLM (Multiple Languages and Modalities) dataset - a new resource to train and evaluate multitask systems on samples in multiple modalities and three languages. The generation process and inclusion of semantic data provide a resource that further tests the ability for multitask systems to learn relationships between entities. The dataset is designed for researchers and developers who build applications that perform multiple tasks on data encountered on the web and in digital archives. A second version of MLM provides a geo-representative subset of the data with weighted samples for countries of the European Union. We demonstrate the value of the resource in developing novel applications in the digital humanities with a motivating use case and specify a benchmark set of tasks to retrieve modalities and locate entities in the dataset. Evaluation of baseline multitask and single task systems on the full and geo-representative versions of MLM demonstrate the challenges of generalising on diverse data. In addition to the digital humanities, we expect the resource to contribute to research in multimodal representation learning, location estimation, and scene understanding.
A Feature Analysis for Multimodal News Retrieval
Jul 13, 2020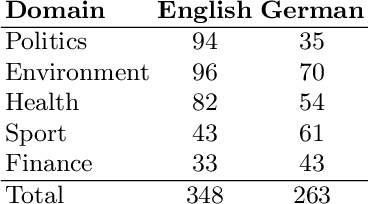

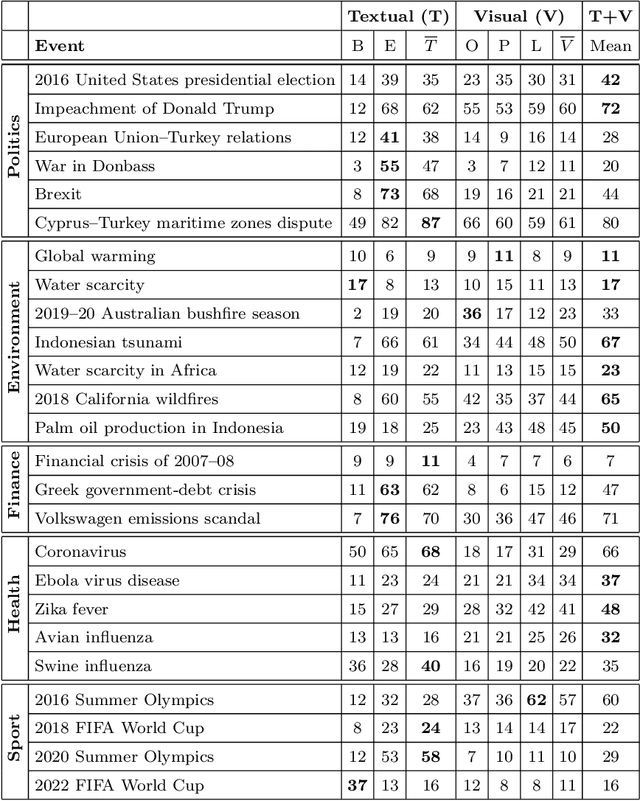
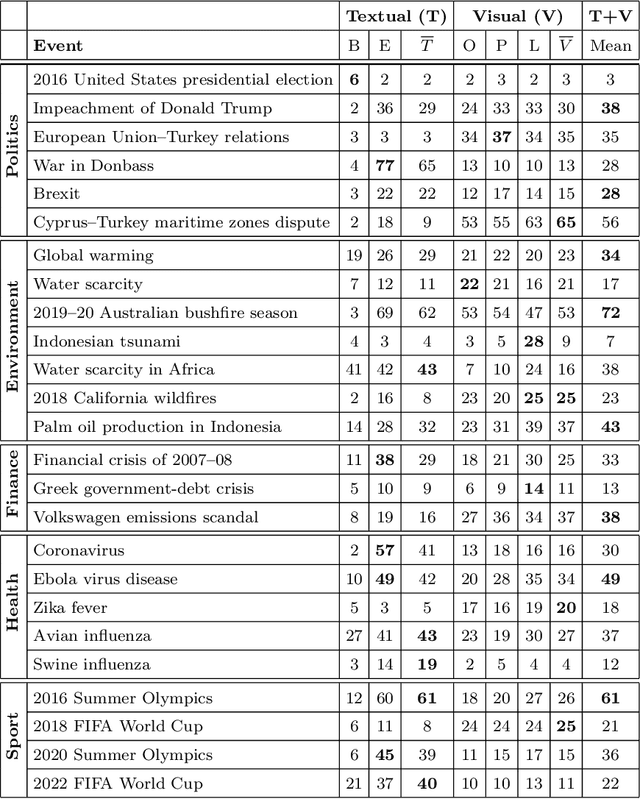
Content-based information retrieval is based on the information contained in documents rather than using metadata such as keywords. Most information retrieval methods are either based on text or image. In this paper, we investigate the usefulness of multimodal features for cross-lingual news search in various domains: politics, health, environment, sport, and finance. To this end, we consider five feature types for image and text and compare the performance of the retrieval system using different combinations. Experimental results show that retrieval results can be improved when considering both visual and textual information. In addition, it is observed that among textual features entity overlap outperforms word embeddings, while geolocation embeddings achieve better performance among visual features in the retrieval task.